牛蹄印章_VX_iibull
iibull
偷得浮生半桶水(半日闲), 好记性不如抄下来(烂笔头). 信息爆炸的时代, 学习是一项持续的工作.
全部博文(1772)
ER69XX项目归纳(5)
驱动(18)
Delphi(12)
dotNet(13)
Meego(4)
Kernel(25)
U-BOOT(7)
Oracle(15)
工作(6)
2025年(21)
2024年(27)
2023年(26)
2022年(112)
2021年(217)
2020年(157)
2019年(192)
2018年(81)
2017年(78)
2016年(70)
2015年(52)
2014年(40)
2013年(51)
2012年(85)
2011年(45)
2010年(231)
2009年(287)
miaoyule
shiye
General_
cehnjinj
zhuping_
gongping
zzbok
garfield
transist
gaokeke1
LCAIJUN
老山688
xmxmx
14480948
WhiteChe
Owen_Zha
xuguangm
albertyo
分类: 其他平台
2021-05-24 11:45:29
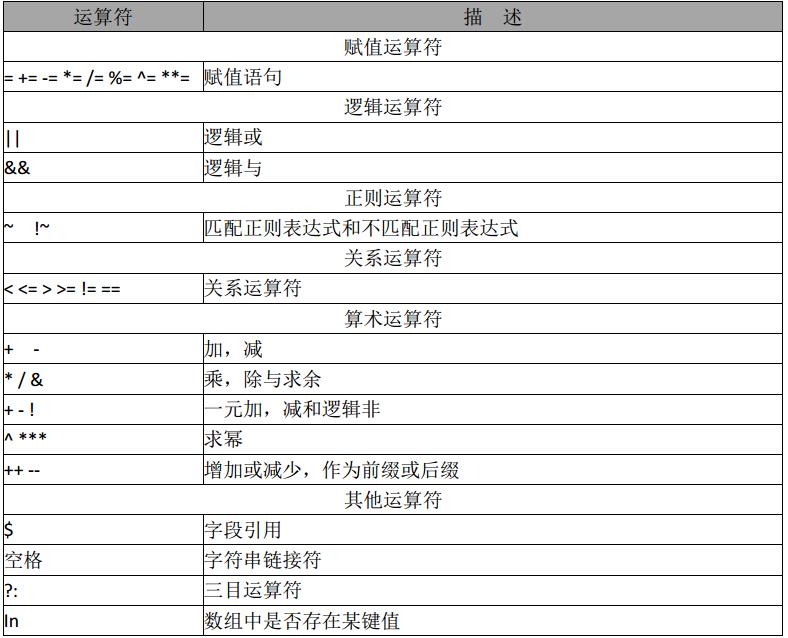
点击(此处)折叠或打开
上一篇:linux 三剑客之 sed 命令
下一篇:linux 三剑客之 grep 命令
登录 注册
 $0 为一整行 root:x:0:0:root:/root:/bin/bash
$0 为一整行 root:x:0:0:root:/root:/bin/bash