偷得浮生半桶水(半日闲), 好记性不如抄下来(烂笔头). 信息爆炸的时代, 学习是一项持续的工作.
全部博文(1772)
分类: 其他平台
2020-04-21 17:21:53
ORB-SLAM 基本介绍
ORB-SLAM 是西班牙 Zaragoza 大学的 Raúl Mur-Arta 编写的视觉 SLAM 系统。 它是一个完整的 SLAM 系统,包括视觉里程计、跟踪、回环检测,是一种完全基于稀疏特征点的单目 SLAM 系统,同时还有单目、双目、RGBD 相机的接口。其核心是使用 ORB (Orinted FAST and BRIEF) 作为整个视觉 SLAM 中的核心特征。
ORB-SLAM 基本延续了 PTAM 的算法框架,但对框架中的大部分组件都做了改进, 归纳起来主要有 4 点:
引自《基于单目视觉的同时定位与地图构建方法综述》
ORB-SLAM 的整体系统框架图
ORB-SLAM 它是由三大块、三个流程同时运行的。第一块是跟踪,第二块是建图,第三块是闭环检测。
这一部分主要工作是从图像中提取 ORB 特征,根据上一帧进行姿态估计,或者进行通过全局重定位初始化位姿,然后跟踪已经重建的局部地图,优化位姿,再根据一些规则确定新关键帧。
2. 建图(LocalMapping)
这一部分主要完成局部地图构建。包括对关键帧的插入,验证最近生成的地图点并进行筛选,然后生成新的地图点,使用局部捆集调整(Local BA),最后再对插入的关键帧进行筛选,去除多余的关键帧。
3. 闭环检测(LoopClosing)
这一部分主要分为两个过程,分别是闭环探测和闭环校正。闭环检测先使用 WOB 进行探测,然后通过 Sim3 算法计算相似变换。闭环校正,主要是闭环融合和 Essential Graph 的图优化。
ORB-SLAM 优缺点
优点:
缺点:
ORB-SLAM2
ORB-SLAM2 在 ORB-SLAM 的基础上,还支持标定后的双目相机和 RGB-D 相机。双目对于精度和鲁棒性都会有一定的提升。ORB-SLAM2 是基于单目,双目和 RGB-D 相机的一套完整的 SLAM 方案。它能够实现地图重用,回环检测和重新定位的功能。无论是在室内的小型手持设备,还是到工厂环境的无人机和城市里驾驶的汽车,ORB-SLAM2 都能够在标准的 CPU 上进行实时工作。ORB-SLAM2 在后端上采用的是基于单目和双目的光束法平差优化(BA)的方式,这个方法允许米制比例尺的轨迹精确度评估。此外,ORB-SLAM2 包含一个轻量级的定位模式,该模式能够在允许零点漂移的条件下,利用视觉里程计来追踪未建图的区域并且匹配特征点。
深度相机选择
目前的主流视觉深度传感器方案主要分结构光,Time-of-Flight 和纯双目三类。双目跟结构光一样,都是使用三角测量法根据物体匹配点的视差反算物体距离,只是双目是用自然光,而结构光是用主动光发射特定图案的条纹或散斑。ToF 是通过给目标连续发送光脉冲,然后用传感器接收从物体返回的光,通过探测光脉冲的飞行(往返)时间来得到目标物距离。
ToF 和结构光都属于主动光,比如 Kinect 1,2 代(现已停产),容易受可见光和物体表面干扰,所以更适合室内和短距离的应用场景。
小觅双目深度相机系列融合了 VSLAM+IMU ,提升精度的同时减少了累积误差和漂移,(IR)红外主动光探测器可辅助识别室内白墙和无纹理物体,克服了 ORB-SLAM 初始化运动时对无纹理物体不友好的特性。同时支持 ORB-SLAM , OKVIS,viorb 和 vins 多个开源项目案例,为了方便小伙伴们开发、移植、学习和应用,我们在 Github 上分享了 MYNT-ORBSLAM2-Sample ( ROS 及非 ROS 的接口都有提供噢~)。戳这里:https://github.com/slightech/MYNT-EYE-ORB-SLAM2-Sample
这是我们跑 ORB-SLAM2 的效果:
更多 SLAM 学习资源在这里:
附专业名词解释
Bag-of-words:词袋算法 ,它是主要用来判断同一个地点是不是被重新访问过,它的算式在实现的原理上可以认为是对每一帧或者叫每一幅图用了很多单词来进行描述。
在实际应用中在这个词袋中使用的单词量会非常大,并且这些词在现实中并没有一个非常明确的物理含义;词袋方案现在主流所采取的方案之一,它做得最好的一方案叫 DBOW2,也是一个开源的方案。
Bundle Adjustment(BA):光束平差法,就是利用非线性最小二乘法来求取相机位姿,三维点坐标。在仅给定相机内部矩阵的条件下,对四周物体进行高精度重建。
Bundle Adjustment 可以将所观测的图像位置和预测的图像位置点进行最小 error 的映射(匹配),由很多非线性函数的平方和表示(error)。因此,最小化 error 由非线性最小二乘法实现。
Essential Graph:基于位置优化的实时闭环控制。它通过生成树构建,生成树由系统、闭环控制链接和视图内容关联强边缘进行维护。
实际当中,仅通过帧间运动(ego-motion)来计算机器人轨迹是远远不够的。如下图所示:

如果你只用帧间匹配,那么每一帧的误差将对后面所有的运动轨迹都要产生影响。例如第二帧往右偏了0.1,那么后面第三、四、五帧都要往右偏0.1,还要加上它们自己的估算误差。所以结果就是:当程序跑上十几秒之后早就不知道飞到哪儿去了。这是经典的SLAM现象,在EKF实现中,也会发现,当机器人不断运动时,不确定性会不断增长。当然不是我们所希望的结果。
那么怎么办才好呢?想象你到了一个陌生的城市,安全地走出了火车站,并在附近游荡了一会儿。当你走的越远,看到许多未知的建筑。你就越搞不清楚自己在什么地方。如果是你,你会怎么办?
通常的做法是认准一个标志性建筑物,在它周围转上几圈,弄清楚附近的环境。然后再一点点儿扩大我们走过的范围。在这个过程中,我们会时常回到之前已经见过的场景,因此对它周围的景象就会很熟悉。
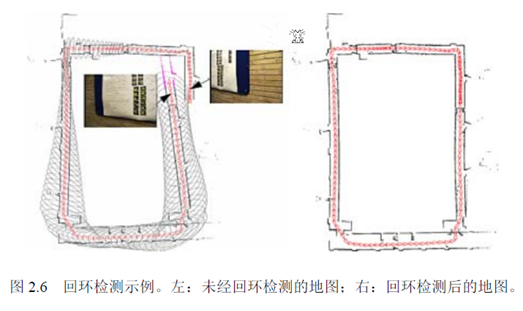
机器人的情形也差不多,除了大多数时候是人在遥控它行走。因而我们希望,机器人不要仅和它上一个帧进行比较,而是和更多先前的帧比较,找出其中的相似之处。这就是所谓的回环检测(Loop closure detection)。用下面的示意图来说明:

没有回环时,由于误差对后续帧产生影响,机器人路径估计很不稳定。加上一些局部回环,几个相邻帧就多了一些约束,因而误差就减少了。你可以把它看成一个由弹簧连起来的链条(质点-弹簧模型)。当机器人经过若干时间,回到最初地方时,检测出了大回环时,整个环内的结构都会变得稳定很多。我们就可以籍此知道一个房间是方的还是圆的,面前这堵墙对应着以前哪一堵墙,等等。
总而言之, 虽然理论上, 视觉建模可通过前后帧的差距进行建模, 实际算法精度计算会误差, 并且误差会被累积,造成最终结果不准确, 所以视觉slam做回环检测很重要.SLAM方面究竟有哪些可以研究的地方呢?我为大家上一个脑图。

这个图是从我笔记本上拍下来的(请勿吐槽字和对焦)。可以看到,以SLAM为中心,有五个圈连接到它。我称它为Basic Theory(基础理论)、Sensor(传感器)、Mapping(建图)、Loop Detection(回环检测)、Advanced Topic(高级问题)。这可以说是SLAM的研究方向。下面我们"花开五朵,各表一枝"。
SLAM的基本理论,是指它的数学建模。也就是你如何用数学模型来表达这个问题。为什么说它"基本"呢?因为数学模型影响着整个系统的性能,决定了其他问题的处理方法。在早先的研究中(86年提出[1]至21世纪前期[2]),是使用卡尔曼滤波器的数学模型的。那里的机器人,就是一个位姿的时间序列;而地图,就是一堆路标点的集合。什么是路标点的集合?就是用(x,y,z)表示每一个路标,然后在滤波器更新的过程中,让这三个数慢慢收敛。
那么,请问这样的模型好不好?
好处是可以直接套用滤波器的求解方法。卡尔曼滤波器是很成熟的理论,比较靠谱。
缺点呢?首先,滤波器有什么缺点,基于它的SLAM就有什么缺点。所以EKF的线性化假设啊,必须存储协方差矩阵带来的资源消耗啊,都成了缺点(之后的文章里会介绍)。然后呢,最直观的就是,用(x,y,z)表示路标?万一路标变了怎么办?平时我们不就把屋里的桌子椅子挪来挪去的吗?那时候滤波器就挂了。所以啊,它也不适用于动态的场合。
这种局限性就是数学模型本身带来的,和其他的算法无关。如果你希望在动态环境中跑SLAM,就要使用其他模型或改进现有的模型了。
SLAM的基本理论,向来分为滤波器和优化方法两类。滤波器有扩展卡尔曼滤波(EKF)、粒子滤波(PF),FastSLAM等,较早出现。而优化方向用姿态图(Pose Graph),其思想在先前的文章中介绍过。近年来用优化的逐渐增多,而滤波器方面则在13年出现了基于Random Finite Set的方法[3],也是一个新兴的浪潮[4]。关于这些方法的详细内容,我们在今后的文章中再进行讨论。
作为SLAM的研究人员,应该对各种基本理论以及优缺点有一个大致的了解,尽管它们的实现可能非常复杂。
传感器是机器人感知世界的方式。传感器的选择和安装方式,决定了观测方程的具体形式,也在很大程度上影响着SLAM问题的难度。早期的SLAM多使用激光传感器(Laser Range Finder),而现在则多使用视觉相机、深度相机、声呐(水下)以及传感器融合。我觉得该方向可供研究点有如下几个:
建图,顾名思议,就是如何画地图呗。其实,如果知道了机器人的真实轨迹,画地图是很简单的一件事。不过,地图的具体形式也是研究点之一。比如说常见的有以下几种:
地图由一堆路标点组成。EKF中的地图就是这样的。但是,也有人说,这真的是地图吗(这些零零碎碎的点都是什么啊喂)?所以路标图尽管很方便,但多数人对这种地图是不满意的,至少看上去不像个地图啊。于是就有了密集型地图(Dense map)。
通常指2D/3D的网格地图,也就是大家经常见的那种黑白的/点云式地图。点云地图比较酷炫,很有种高科技的感觉。它的优点是精度比较高,比如2D地图可以用0-1表示某个点是否可通过,对导航很有用。缺点是相当吃存储空间,特别是3D,把所有空间点都存起来了,然而大多数角角落落里的点除了好看之外都没什么意义……


拓扑地图是比度量地图更紧凑的一种地图。它将地图抽象为图论中的"点"和"边",使之更符合人类的思维。比如说我要去五道口,不知道路,去问别人。那人肯定不会说,你先往前走621米,向左拐94.2度,再走1035米……(这是疯子吧)。正常人肯定会说,往前走到第二个十字路口,左拐,走到下一个红绿灯,等等。这就是拓扑地图。
既然有人要分类,就肯定有人想把各类的好处揉到一起。这个就不多说了吧。
回环检测,又称闭环检测(Loop closure detection),是指机器人识别曾到达场景的能力。如果检测成功,可以显著地减小累积误差。
回环检测目前多采用词袋模型(Bag-of-Word),研究计算机视觉的同学肯定不会陌生。它实质上是一个检测观测数据相似性的问题。在词袋模型中,我们提取每张图像中的特征,把它们的特征向量(descriptor)进行聚类,建立类别数据库。比如说,眼睛、鼻子、耳朵、嘴等等(实际当中没那么高级,基本上是一些边缘和角)。假设有10000个类吧。然后,对于每一个图像,可以分析它含有数据库中哪几个类。以1表示有,以0表示没有。那么,这个图像就可用10000维的一个向量来表达。而不同的图像,只要比较它们的向量即可。
回环检测也可以建成一个模型识别问题,所以你也可以使用各种机器学习的方法来做,比如什么决策树/SVM,也可以试试Deep Learning。不过实际当中要求实时检测,没有那么多时间让你训练分类器。所以SLAM更侧重在线的学习方法。
前面的都是基础的SLAM,只有"定位"和"建图"两件事。这两件事在今天已经做的比较完善了。近几年的RGB-D SLAM[5], SVO[6], Kinect Fusion[7]等等,都已经做出了十分炫的效果。但是SLAM还未走进人们的实际生活。为什么呢?
因为实际环境往往非常复杂。灯光会变,太阳东升西落,不断的有人从门里面进进出出,并不是一间安安静静的空屋子,让一个机器人以2cm/s的速度慢慢逛。论文中看起来酷炫的算法,在实际环境中往往捉襟见肘,处处碰壁。向实际环境挑战,是SLAM技术的主要发展方向,也就是我们所说的高级话题。主要有:动态场景、语义地图、多机器人协作等等。
本文向大家介绍了SLAM中的各个研究点。我并不想把它写成综述,因为不一定有人愿意看一堆的参考文献,我更想把它写成小故事的形式。
最后,让我们想象一下未来SLAM的样子吧:
有一天,小萝卜被领进了一家新的实验楼。在短暂的自我介绍之后,他飞快地在楼里逛了一圈,记住了哪里是走廊,哪儿是房间。他刻意地观察各个房间特有的物品,以便区分这些看起来很相似的房间。然后,他回到了科学家身边,协助他的研究。有时,科学家会让他去各个屋里找人,找资料,有时,也带着他去认识新安装的仪器和设备。在闲着没事时,小萝卜也会在楼里逛逛,看看那些屋里都有什么变化。每当新的参观人员到来,小萝卜会给他们看楼里的平面图,向他们介绍各个楼层的方位与状况,为他们导航。大家都很喜欢小萝卜。而小萝卜明白,这一切,都是过去几十年里SLAM研究人员不断探索的结果。

首先打个广告。SLAM研究者交流QQ群:254787961。欢迎各路大神和小白前来交流。
看了前面三篇博文之后,是不是有同学要问:博主你扯了那么多有用没用的东西,能不能再给力一点,拿出一个我们能实际上手玩玩的东西啊?没错,接下来我们就带着大家,实际地跑一下视觉SLAM里的那些经典程序,给大家一个直观的印象——因此博文就叫"视觉SLAM实战"啦。这些程序包括:
如果你有什么建议,可以发我的邮件或来群里交流。当然,我是边跑边写博客,而不是一口气调通再稀里哗啦写的。所以呢,最后跑的程序可能会和现在的计划有些出入啦。好了,废话不多说,先来介绍下实验器材。
1. 硬件
说好的SLAM,没有机器人怎么行?老板,先给我来三份!

这种机器人是Turtlebot的一个改装版本:Viewbot。Turtlebot的详情请参见:Viewbot是上海物景公司做的改装版本,包括可以装些额外的传感器,以及把原来的黑色底板变成透明底板什么的,用起来和turtlebot大同小异,价格1W+。为了避免做广告的嫌疑我就不放链接了。用这个机器人的好处,是ROS有直接对应的包,不用你自己写。一句话即可打开传感器读数据,再一句话就可遥控它,方便省事。
机器人的主要部件就是它的底座和上头的Kinect啦。座子自带惯导,可以估计自己的位置;Kinect么,大家都知道了,不多讲。事实上今天要跑的rgbd-slam-v2不需要座子,只要一台kinect就能动起来。我们用不着那么多机器人,只用一个就行啦(就是贴了标签那台)。
2. 软件
软件方面只需一台笔记,放在机器上跑程序。我用的是一台华硕的ubuntu,装了mac主题包真是山寨气十足啊:

具体的软件配置后面会细说。
3. 环境
环境嘛就是我的实验室,这个也不细说了。
RGB-D-SLAM-V2程序是由F. Endres大大写的。论文见[1]。为什么首先选这个程序呢?因为它的原理在我们前面的博客中介绍过了。它是一个基于深度相机、Pose graph (图优化)的程序,后端用的是g2o。另一方面,它的代码直接兼容 ROS hydro版,基本不用配置就可以运行,非常方便。下面我们一步步地教大家运行这个程序:
不着急,先从README看起:"RGBDSLAMv2 is based on the ROS project, OpenCV, PCL, OctoMap, SiftGPU and more – thanks!" 你还在等什么?装装装!好在这些东西在Ubuntu下安装,就是几句话搞定的事。
ROS hydro安装指南: (加ppa源后直接安装)
Linux OpenCV安装指南:http://blog.sciencenet.cn/blog-571755-694742.html (从源代码编译)
PCL: (加ppa后安装)
后面几个嘛,装不装就看心情了,即使没有装,rgbd-slam-v2也能运行起来。
3. 装完之后,看"Installation from scratch"一栏,基本照着做一遍即可。作者把命令都给出来了,我就不贴了。装完之后,rgbdslam就在你的ros包里啦。
4. 把机器人的Kinect usb口插进电脑,运行 roslaunch rgbdslam openni+rgbdslam.launch,就能看到一个漂亮的界面了。

可以看出作者真的挺用心,居然做了UI。像我这样的懒人绝对不可能做UI的……不谈这些,底下的两个图就是Kinect当前采到的彩色图与深度图,而上面则是3D在线点云图(可以用鼠标转视角)。现在,程序还在待机状态,敲下Enter会采集单帧数据,而敲下空白键则会连续采集。
此外,程序的参数可以在openni+rgbdslam.launch文件中调整。例如特征点类型呀(支持SIFT,SURF,ORB,SIFTGPU),最大特征数量等等。
现在,我们连上Turtlebot的遥控端:
roslaunch turtlebot_bringup minimal.launch (启动底座)
roslaunch turtlebot_teleop keyboard_teleop.launch (启动遥控)
按下rgbd-slam-v2的空白键,让机器人四处走起来。UI的状态栏会显示程序的运行状态,我看到过的有 正在提取特征、加入新Frame,等等。如果它成功匹配上,上图的点云就会更新,并且会跟着机器人转动。

我让小车在实验室的一个角上转了几圈。它把中间放置的一堆箱子(实际上是垃圾)都扫出来了。当你觉得满意后,再按下Space键,停止程序。然后从菜单中选出需要保存的东西:机器人的轨迹,最终点云图,等等。轨迹是一个txt文件,而点云图则一个pcd,在安装PCL之后调用pcl_viewer即可查看。
别看上面像是打了码一样的,最后出的点云图可是高清无码的:

轨迹方面,用Matlab写个脚本plot一下即可:
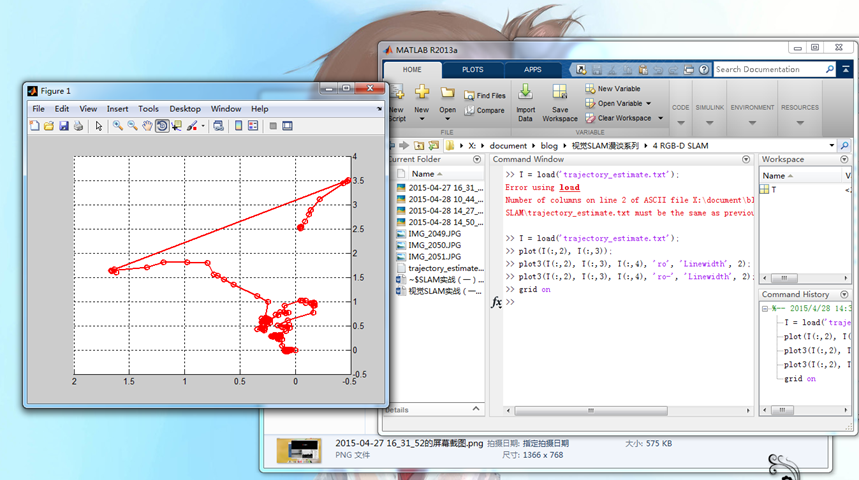
可以看到轨迹上出现了断层,实际上是机器人转的比较快,算法跟丢了,然而之后又通过回环检测给找了回来。
最后,总结一下这个实验吧。
Rgbd-slam-v2是14年论文里提到的算法。它整合了SLAM领域里的各种技术:图像特征、回环检测、点云、图优化等等,是一个非常全面且优秀的程序。它的UI做的也很漂亮,你可以在它的源代码上继续开发。作者也提供了数据集供研究者们测试。
缺点:在美观之外,由于要提特征(SIFT很费时)、渲染点云,这些事情是很吃资源的,导致算法实时性不太好。有时你会发现它卡在那儿不动了,不得不等它一小会。机器人如果走的太快,很容易跟丢。于是我的机器人就真的像只乌龟一样慢慢地在地板上爬了……一旦转头快了,轨迹基本就断掉了。此外,程序采集关键帧的频率很高,稍微一会就采出几十个帧,不太适合做长时间的SLAM。最后合出来的点云有300W+个点,我用网格滤波之后才能勉强显示出来。
根据个人使用d435的经验 (侧看墙), 前进速度要尽量平滑, 旋转一定要足够大的弧度还得保证有效的视距, 否则重来吧. slamtec的经验为视距保持 2m内, 速度 2cm/s. 按照这种建议,YY酒店要搞一个整天. (40m * 5端 * 2来回 = 400米 = 40000cm --> 20000秒 = 5个小时, 这得疯)rosrun image_view image_view image:=/camera/rgb/image_color 查看rgb彩图.
