
通常,日志文件都是文本格式,其中的内容是非结构化的文本串。这就使得我们查询日志信息时,一般只能使用文本编辑软件的搜索功能,输入关键字后,靠眼力去侦查每处匹配结果。在日志量不大,或者只是偶尔查一下时,这么操作倒也无妨。不过,再简单的事情也怕多次重复。如果需要频繁查询,量变就可能引起质变。如果每次还都要靠人工搜索,那么就算有再好的视力,也会有头晕目眩的时候。因此,想要轻松查询日志,就必须找到一款合适的工具,有了合适的工具,就可以一边喝着咖啡,一边轻弹条件回车就行了。
工具里面,首先想到的,就是利用各种计算机开发语言,外加关系数据库。但这类工具开发过程繁琐,还需要准备好多工作环境,包括配置语言开发环境,安装数据库服务,安装数据库查询应用等。
对于这么“重”的方案,我们果断撇开。因为今天就要介绍一个轻巧方便的工具——集算器,利用集算器,可以将文本日志变成结构化数据,然后就可以使用我们熟悉的 SQL 式查询了。
这里,我们利用到了集算语言 (Structured Process Language,简称 SPL) 的两大优点:
-
将日志内容结构化为数据表结构,SPL 远比常用开发语言简单、易用、直观。
-
SPL 支持直接对结构化的文件进行 SQL 查询,不再需要安装配置第三方数据库软件。
下面就是具体的实施过程。
1、日志结构分析
不同的日志文件,其内容格式五花八门,每一个看上去都杂乱无章。但对于某个特定的具体的日志来说,它一定会有它自己的结构。拿到日志文件后,首先要做的就是分析日志内容,提炼数据结构,总结出可以结构化的字段。
作为示例,我们用腾讯视频软件下的一个启动日志来做案例。如果你也用过腾讯视频,就可以利用下面的代码来体验和学习,分析一下自己的使用行为了。这个日志文件,位于当前用户的 AppData 路径下,并且以 QQLive.exe[Main] 开头。在我的机器上,这个文件就是:
C:\Users\[Joancy]\AppData\Roaming\Tencent\QQLive\Log\QQLive.exe[Main][2018-8-3 21-5-35-557][12164].log
上述路径中 [Joancy] 是我的 Windows 登录用户名,在你的机器中,将会是你的用户名。QQLive.exe[Main]开头的日志文件有很多,随便取一个就可以。
下面就是这个日志文件中的两行:
[18-07-19 14:35:06][9416]-[31ms][QQLiveMainModule.dll][CQQLiveModule::ParsCommandLine] cmd=”C:\Program Files (x86)\Tencent\QQLive\QQLive.exe” -system_startup
[18-07-19 14:35:08][9416]-[2266ms][HttpModule.dll][CDownloadMgr::AddTask]keyid = 1,url =
可以看到,这个日志的内容比较规整,一行一条记录。每行中一对中括号中的内容为一节,对应一个字段。只是最后的两节有点特殊,其中倒数第二节可以省略,而最后一节没用中括号括起来。这样,我们就可以整理出日志表的数据结构如下,并且把第一行内容作为对应的示例:

表(1)
解析各个字段时,需要注意:
1) 记录时间: 由于年份只有两位,所以在转成日期时间类型时,需要指定相匹配的日期格式,否则 18 就会被当成公元 18 年,而不是 2018 年了。具体的操作方法是打开集算器菜单中的选项,在弹出的窗口中点击环境页面,设置属性‘日期时间格式’为‘yy-MM-dd HH????????ss’。
2) 加载时刻: 描述的是程序自从启动后,当前模块从启动后历经的毫秒数。由于字串后面有单位‘ms’,因此需要在转换为整数前先去掉这个单位。
3) 加载函数: 这个字段不一定有,所以需要在分析结构时进行判断,没有该字段时,需要插入空值。
2、结构化实施
如果采用数据库来存储结构化后的日志数据,首先需要安装和配置数据库,然后安装合适的数据库查询应用程序,这个过程可能会比较麻烦。如果利用现成的生产数据库,那么首先可能更新不方便,其次更重要的,会影响生产系统的性能。
而利用集算器,由于 SPL 支持直接对结构化的文件进行 SQL 查询,那就简单了,只需将结构化后的内容保存到文件就行了。
下面开始编程。在集算器设计器中,新建文件,设定它的网格参数为‘fileName’,用于指定需要转换的日志文件,然后把文件保存为 convert.dfx。具体的实现脚本如下:

表(2)
这段脚本的功能就是接收日志文件,将文本内容按行读取为一个序表。然后逐行拆分信息成为一条记录。最后将转换后的序表保存到同目录下另一个文件。脚本中用到最多的一个函数是 substr(src,target),作用是在 src 中找 target ,找到后返回 src 中 target 后面(右边)的字串,找不到时返回空。如果使用选项 @l 时,则返回前面(左边)的字串。 注意:文中表格的合并格,仅仅是为了阅读方便。集算器网格没有合并格,将代码复制到集算器网格中时,只能对应到合并格的首格。
脚本详解:
1)A1 格的 create 函数类似数据库的 Create Table 命令,作用是创建一个空表,字段名就是 create 函数的参数,但不需要事先指定数据类型。
2)A2 格使用 file 函数,用选项 @s 加载位于寻址路径下的 fileName 文件,通过参数”UTF-8”指明该日志文件是 UTF-8 字符集的,且包含了中文(如果中文出现乱码,那就是字符集不对)。
3)B2 将文件内容读入到序列,选项 @n 表示读取的内容是文本。
4)A3 为循环,依次遍历 B2 的成员。
5)B3 和 C3 用于跳过空行。
6)B4 初始化一个空序列,用于容纳解析后的每个字段值。
7)B5 先循环 4 次,分离前 4 个字段内容。这是因为每一行日志仅有前 4 节由‘[]’分开,而第 5 节如果有‘[]’,则其中内容解析为‘加载函数’,如果没有就将后面的所有信息解析为‘日志内容’。同时,之所以不是一次就按中括号全部拆分,是因为日志内容里面仍然可能包含‘[]’,所以随后的两个字段需要单独解析。
8) 代码块 C5 到 D8,使用 substr 函数分离出字符串值,再用 parse 函数将字符串值串解析到正确的字段类型,然后将解析出来的结果追加到 B5 定义的序列中。其中代码 D7 处理特殊的第 3 个字段内容,去掉多余的‘ms’。
9)代码块 B9 到 C11 判断当前的串如果仍是‘[]’分隔的内容,则解析出字段 5‘加载函数’。
10) 代码块 B12 到 C12 是在没有‘加载函数’内容时,插入一个 null 空值。
11)B13 把解析的最后一节内容,全部追加到序列 B4,对应最后一个字段‘日志内容’。
12)B14 把当前解析出来的所有字段值,追加到 A1 定义的数据表中。
13)A15 到 C15 获取当前文件的绝对路径,分别拆分出路径和文件名。
14)A16 重新构建一个相同目录下,扩展名为 txt 的输出文件名。
15)A17 将结构化后的内容导出到输出文件。这里用到了文件的导出函数 export,该函数用于将序表的内容导出到指定文件,选项 t 表示导出的仍然是文本文件,而且文本的第一行是字段名。这里特别说明一下,选项 t 可以改为 b,意思是导出为二进制的集文件,使用集文件时,存储和读取的效率都比文本文件更高。这个例子中我们先使用文本文件,方便直接查看导出后的内容。
16)A18 向控制台打印一个转换完成的信息。
保存脚本,并且将日志文件更名为 QQLive.log 也放置到相同目录,同时在集算器的选项窗口中,找到环境页面下的寻址路径,将上述 convert.dfx 文件的目录(我这里使用的是 D:\demo)加入到 寻址路径 。然后打开 DOS 命令执行窗口,进入到安装路径下的 bin 目录(我这里的安装路径是 D:\temp\esProc)。输入 esprocx 命令执行 convert.dfx 效果如下:

图(1)
从图(1)中的打印信息可以看出,日志文件被结构化后,已经保存到 d:\demo\QQLive.txt 文件中。用文本编辑器打开 QQLive.txt,可以看到第一行是字段名称,后面的字段内容都已经规整,并用制表符分开。如下图:

图(2)
3、使用 SQL 查询日志
使用集算器查询文件序表的内容非常简单,就跟查询数据库一模一样。具体的做法也是建立连接对象,然后调用 query 方法,所不同的是,文件数据库的连接名不用填。
下面这个例子新建了一个 query.dfx 文件,定义一个参数‘sql’用于传入需要执行的 SQL 命令。脚本如下:

表(3)
脚本详解:
1)A1 建立一个参数为空的连接对象,用于对本地文件的查询。
2)A2 与执行数据库的查询一样,使用该连接对象的 query 方法,执行 sql 语句。
3)A3 返回查询结果。
同样,将该文件放置在寻址路径下,看下执行效果:
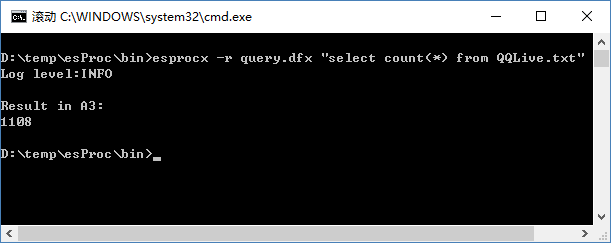
图(3)
上述 esprocx 命令用到了选项 -r,用于执行完 dfx 后,打印出返回的结果。从图(3)中可以看出,转换的日志记录共有 1108 条记录。需要注意的是,作为命令行参数时,由于 sql 语句中也包含空格,所以需要加上双引号。
通常查询日志时,往往会关注日志内容中包含某个关键字的信息,下面是对应的查询:
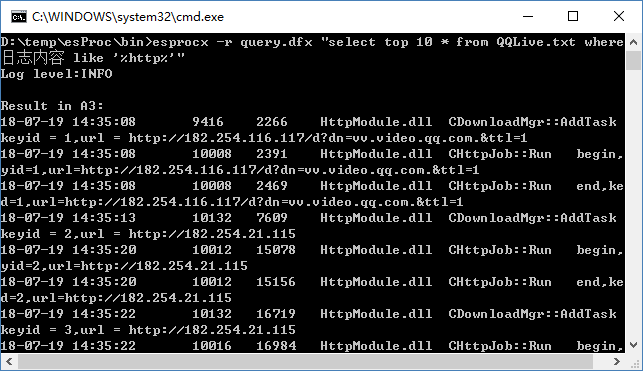
图(4)
从图(4)可以看出,这个查询是查找日志内容中包含‘http’的日志信息。同时,这里还用到了 SQL 中的 top 10 关键字,以防记录太多,把查询条件滚屏滚没了,不方便截图。实际情况中,如果查询到的结果很多,DOS 屏幕一屏显示不下,只能看到最后的十来行,这就比较尴尬了。此时只要利用下 DOS 的小技巧,将查询到的内容输出到另一个文件,就解决了:
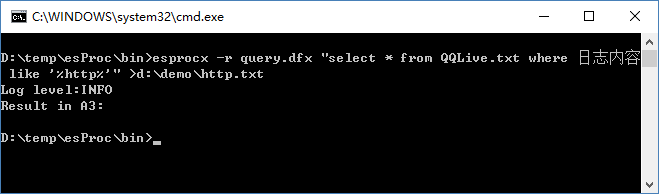
图(5)
图(5)的查询就是将日志中包含‘http’的日志都查询出来,并且保存到了 d:\\demo\\http.txt 文件中。
为了验证当前脚本的鲁棒性,我再从腾讯视频下找到一个比较大的日志文件,大约有 99 兆,将它复制到 D:\\demo 下,并命名为 QQLive99.log。再次执行转换操作:
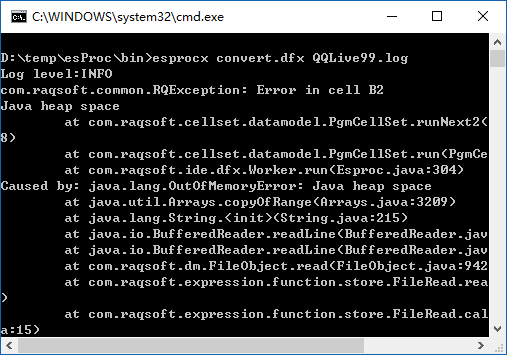
图(6)
结果转换失败。看图(6)中的堆栈信息,原来是 Java heap space 异常。99 兆大的日志文件,按说也不算大,为啥就内存溢出了呢?先查看下当前命令程序的内存分配状况,该内存堆大小的参数在 bin\config.txt 中指定,我当前的最大堆参数设定为 -Xmx200m,才 200 兆,所以内存溢出是可能的。再回头分析下表(2)中 B2 的脚本‘=A2.read@n()’,该语句的意思为将文件 A2 的内容全部读为内存序表。还有 B14 中的‘>A1.record(B4)’,该语句的意思为解析后的记录全部追加在 A1 格子中。也就是分配的最大堆内存至少要大于两倍的源文件大小,才可能顺利算完。这还只是粗算,因为还有其他代码占用内存,以及文本文件转为内存对象后,内存占用也会增大。当然,解决办法之一就是提高最大堆参数。但这种改法治标不治本,一是物理内存总是有限的,不可能无限增大。二是堆大小增大后,过得了当前 99M 的文件,却未必过得了 1G 的文件。所以还是得从脚本上下功夫,看看有没有游标之类的办法,使用游标每次读一块数据,处理完后立即输出,就一劳永逸了。
4、使用游标规避内存溢出
SPL 有文件游标,只要使用文件对象的 cursor 方法就可以返回游标。不过,游标对象是数据库的概念,从游标取出的数据都是序表。但日志文件本身就是一行行的串,读取它就是为了分析后才能得出序表。这就像一个近视眼想去配眼镜,却又看不清柜台远处眼镜的价格。只能问售货员“眼镜怎么卖啊?”,“你自己看”——柜员懒懒地回答。“我能看清还买你的眼镜做什么?!”于是,柜员的慵懒造成了死循环……
要打破这个循环,首先得由柜员告诉顾客眼镜的价格。同理,我们在构造游标时可以使用 s 选项,先不解析文本,直接将整行当一个字段值返回就是,此时使用缺省的字段名:‘_1’。
另外,游标和文件操作在使用上有一些区别,使用文件的 read 函数得到的是一个序列,其成员就是每行文本。而游标返回的是一个序表,序表的成员是记录,需要再取记录中的字段值才能得到每行文本。所以,使用游标处理时要多处理一层,稍微麻烦一些。弄清了这个区别之后,后面的拆分就都一样了。
此处我仍然贴出全部脚本,方便读者直接将脚本复制到集算器执行。为了和前面的 convert.dfx 有所区分,使用游标转换的文件命名为 convertCursor.dfx。脚本如下:

表(4)
表(4)中跟表(2)的拆分脚本以及读取文件等相同代码就不再解释,下面只解释不同的部分:
1)E1 中使用 now() 函数记录脚本计时开始。
2)B2 使用 cursor@s 将文件的每一行作为一条记录,使用缺省字段名‘_1’,返回游标。
3)A3 到 C4 代码块为拆分文件名,生成输出文件。由于使用游标每次只处理一部分数据,处理完的数据直接追加到输出文件。所以在最开始时要将已经存在的输出文件删除,否则每执行一回当前脚本,就会累加一次重复数据。其中用到了 movefile(fn,path),该函数的作用为移动文件 fn 到 path 下,当 path 省略时表示删除当前文件。
4)D4 为定义一个计数器,用于累计当前完成了多少记录的转换,用于后续信息输出。
5)A5 为循环游标取数,后面的参数 100000 为一次读取的记录数。这个数值不能太小,否则读取文件的次数太频繁,效率低。但也不能太大,太大时,如果内存比较小,也可能内存溢出。所以这个值需要在可分配内存下,满足不溢出时,尽可能取大一些。具体多少需要根据分配给 esprocx 的堆大小测试得到。
6)B5 为循环遍历 A5 中的序表。
7)C5 为 B5 循环时,每个成员为一条记录,此处将 B5 中记录的‘_1’字段值取出来。
8)B18 将分析后的值导出到输出文件,注意使用了选项 a,将每次的数据追加到当前文件。
9)B19 和 C19 为计数并输出计数信息,以便转换时可以看到转换进度。 注意 :SPL 中需要将字符串跟数值拼接到一起时,不能使用‘+’,而要使用‘/’符号!
10)B20 使用了 reset 函数将当前的内容清空,好为下一次分析容纳数据。
11)A21 到 A22 为计时,并输出计时信息。
再来看下使用游标转换 QQLive99.log 的效果:
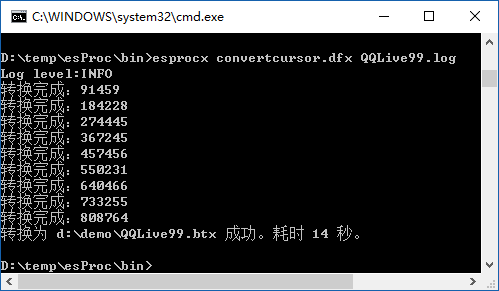
图(7)
从图(7)中信息可以看出,每次从游标取十万条记录来分析时不再内存溢出,且转换耗时 14 秒。为了比较下不同块大小时的效率,我将每次取数改为 100,再看下效果:
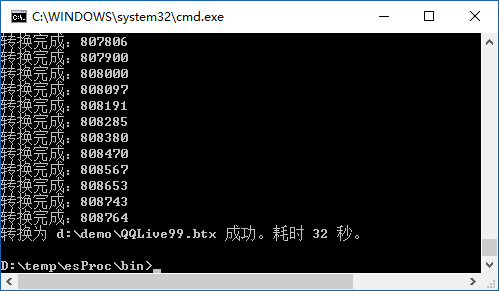
图(8)
从图(8)可以看出,效率明显降低,耗时增加了一倍还要多。所以,只要内存不溢出时,每次游标取数的记录数,尽可能大一些为好。在 convertCursor.dfx 脚本中,输出的文件格式是二进制的集文件,下面看下集文件跟文本文件的区别,修改输出文件为文本文件后,执行转换效果为:

图(9)
可以看到相对于图(7)使用集文件,转换为文本文件耗时多了 2 秒,转换效率变差了。同时文件大小也不同,集文件格式更紧凑,参考下图:
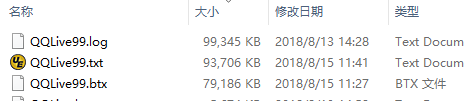
图(10)
图(10)中,集文件 QQLive99.btx 不到 80M,比转换后的文本文件 QQLive99.txt 小了 10% 多。可见集文件无论在处理速度上,还是存储性能上,都要优于文本文件,所以一般情形下,尽量使用集文件存储结构化后的序表。
5、使用多路游标并行计算
第 4 节讲到使用游标来处理数据时,为了提高计算效率,我们可以增大每次从游标取数的行数。但是这个取数的块大小跟物理内存大小是成正比的,当达到了内存极限时,这个数据就没法再提高了。那么是不是就没法再提高代码效率了呢?
当然不是,对于程序计算来说,计算的效率无非就是两方面:一是尽可能将数据加载到内存再计算,充分利用内存的高效 IO,减少对硬盘的多次低效访问;二是现在的 CPU 几乎都是多核的,可以高效并发处理数据,如果采用并发,充分利用多核性能,也能提高计算效率。那么 SPL 是如何利用多线程并发呢?
SPL 开发多线程并发程序很简单,比如第 4 节中用的游标,只要加上选项 m(Multi,多路)就可以返回多路游标。至于这个“多路”具体是多少,可以在“选项”中的“常规”面板下,由最大并行数来指定。这个数据也不是越大越好,毕竟 CPU 的核数一定,太多线程时,反而因为不断调度而浪费时间。一般情形下,这个最大并行数最好不要超过 CPU 的物理核数,性能最佳。我的电脑是 4 核的,所以我采用最大并行数为 4。
下面贴出实现代码,使用多路游标转换的文件命名为 convertMCursor.dfx。脚本如下:
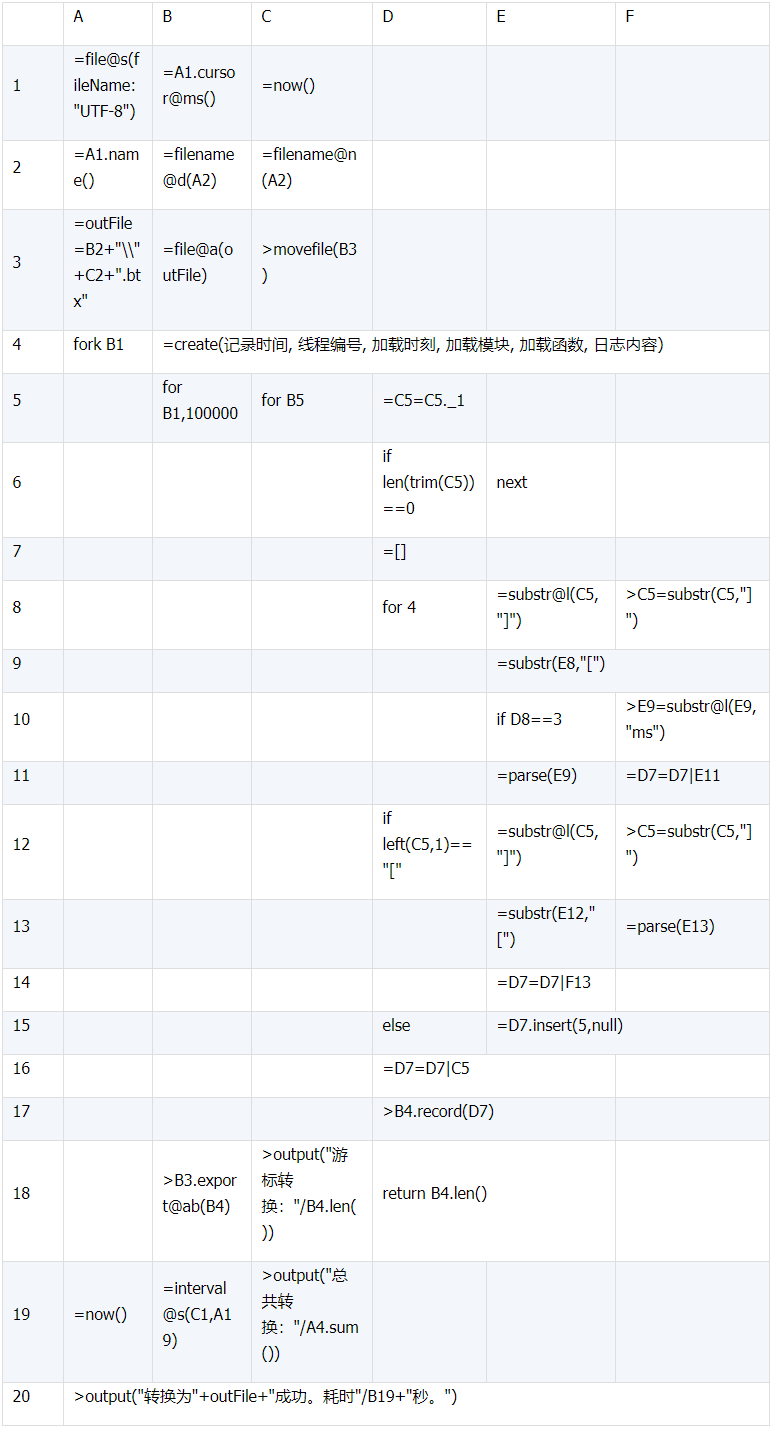
表(5)
脚本详解:
1)B1 使用的游标加了选项 m,返回多路游标。本机采用 4 路游标。
2) 由于 4 路游标是并行执行的,但是写文件操作却没法并行。此时需要在 B3 格中的打开文件时,使用选项 a,意思是打开的文件在并发写时,线程间自动排队,而不报告文件锁异常。
3)A4 中,多路游标的使用,得用 fork 语句,由于多个游标是并发执行的,所以需要将创建表结构的 create 语句放入 A5,让每个游标有自己的局部序表。
4)B18 到 D18 为导出游标数据,打印当前游标的转换数目后,将转换数目返回。需要 注意 的是由于游标是并行执行的,所以转换后的结果不一定对应源文件的次序。
5)A19 到 A20 代码块,打出转换的总记录数以及耗时信息。
看下多路游标执行的效果:

图(11)
从图(11)打出的信息可以看出,共采用了 4 路游标并发执行转换,总共耗时 8 秒,比起没并发前的 16 秒,速度提高了 1 倍,可见并发的效率还是很高的。还有就是当前的并发结果都要写出到同一个文件,由于写出文件仍然是串行的,没法充分利用并发,要不速度还能更快些。
此外,针对集文件的查询,也是可以并行的,且语法跟 Oracle 的语法保持一致。比如执行“select /*+parallel(4)*/ * from QQLive99.btx”时,查询实际是产生了 4 个游标在并发查询。但要注意的是,只有使用 z 选项导出生成的集文件,才能并行。因为并行时,每个线程必须拥有自己的一段文件,使用 z 选项才会写出可分段的集文件。
本例中,由于字段不固定,我们不得不逐个字段顺次拆解,多次使用substr函数一节节拆分,思路虽然简单,但脚本繁琐冗长,最终影响脚本的理解和维护。如果能够假设每一行中字段都格式固定,且不会有字段缺失,那么利用SPL的正则分析函数regex就会非常简便。
例如,假设所有日志均为如下结构:
[18-08-13 13:50:21][13104]-[0ms][QQLiveMainModule.dll][CQQLiveModule::ParsCommandLine] cmd="C:\Program Files (x86)\Tencent\QQLive\QQLive.exe"
那么只需要定义正则表达式:
\[(.*)\]\[(.*)\]-\[(.*)ms\]\[(.*)\]\[(.*)\](.*)
将这个正则表达式作为参数传递给regex函数,其中每一个*对应一个字段。经过函数拆分后,一行日志的每一段都将被依次解析到一个字段中,字段会被自动命名为下划线加序号。这样一来,脚本就会变得非常简单:
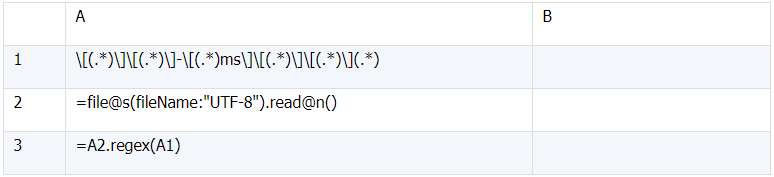
表(6)
脚本解析:
1) A1定义正则表达式,这个表达式是一个常量,直接写在格子里。
2) A2打开日志文件,并将全部内容读进序表。
3) A3采用序列的正则分析函数regex,以A1中的表达式为规则,对A2进行分析并返回结果。
从集算设计器中执行这个脚本,fileName参数依旧使用文件QQLive.log,执行后查看A3的值如下:

图(12)
可以看到,使用序列的regex函数利用正则表达式来分析这类固定格式的日志,脚本简洁清晰,非常便利。
想要了解集算器还有哪些令人耳目一新的强大功能吗?