
窗口函数是 SQL2003 标准才开始有的一系列 SQL 函数,用于应付一些复杂运算是比较方便。但是普遍使用的 MySQL 数据库对窗口函数支持得却很不好,直到最近的版本才开始有部分支持,这当然就让 MySQL 程序员很郁闷了。
实际操作中,我们可以在 MySQL 里用 SQL 拼出窗口函数功能,但是需要使用用户变量以及多个 SELECT 表达式从左到右依次计算的隐含规则。下面我们来看两个例子(为调试方便,我们直接用集算器作为测试环境)。
1、2016 年 1 月销售额排名
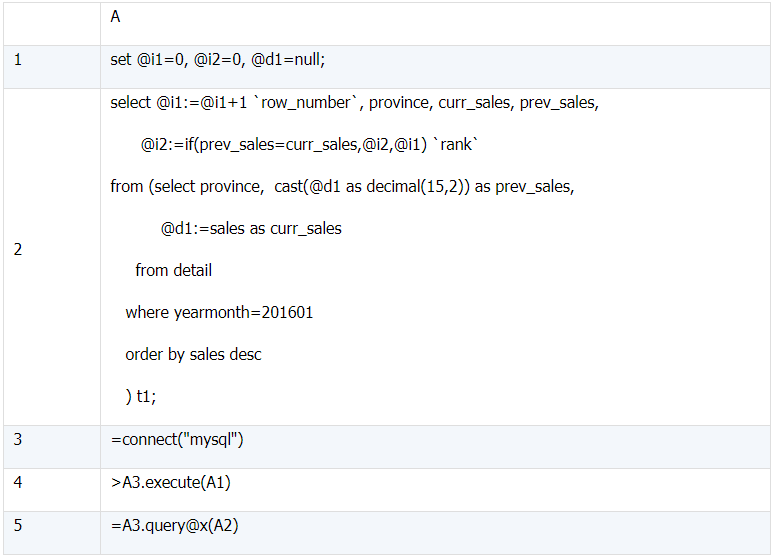
(1)A1 中语句用于初始化用户变量;
(2)A2 中语句先对销售额排倒序,然后每一行销售额与上一行销售额比较,若相等则排名不变,否则排名等于行号;
(3)A3 连接数据库;
(4)A4 执行初始化语句;
(5)A5 执行查询语句并关闭数据库连接,返回结果。
执行后 A5 为需要的结果。
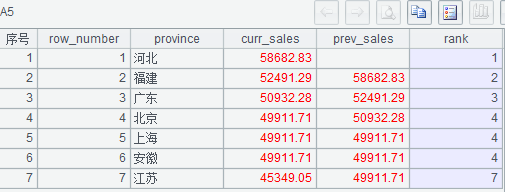
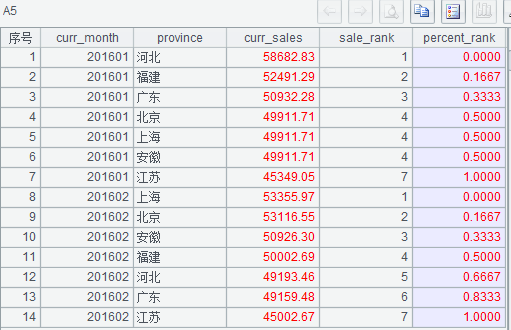
2、2016 年 1 月和 2 月销售额按月分组百分比排名

(1)A1 中语句用于初始化用户变量;
(2)A2 中语句子查询 t11 求出上一行的月份和销售额,t1 再求出本月行号与排名,t2 算出每月的行数,最后 t1 与 t2 连接再利用公式 [if(本月行数>1,(当前行的本月排名 -1)/(本组行数 -1),0)] 求出百分比排号。
执行后 A5 为需要的结果。
通过上述两个例子,我们可以看到,为了实现窗口函数相应功能,SQL 语句冗长、复杂而且可读性较差。另外,这里还使用了 SELECT 表达式从左到右依次计算的隐含规则,而这在 MySQL 参考手册是不推荐使用的,如果今后不能使用这一规则,那么写出来的 SQL 语句会更加复杂。譬如不使用这条隐含规则如何能取上一行的字段值呢?各位读者可以自行脑补。
值得庆幸的是,有了集算器及其特有的 SPL 语言,我们就大可不必这么麻烦了,MySQL 只要使用最基本的 SQL 就行了,剩下的事由集算器来完成。
下面我们就来看看集算器的 SPL 语法是如何实现相应窗口函数的功能的。
1、SUM()、COUNT()、AVG()、MAX()、MIN()、VARIANCE
a)
select province, sales, sum(sales) over() `sum`,
avg(sales) over() `avg`, max(sales) over() `max`,
min(sales) over() `min`, count(*) over() `count`
from detail
where yearmonth=201601
order by sales;
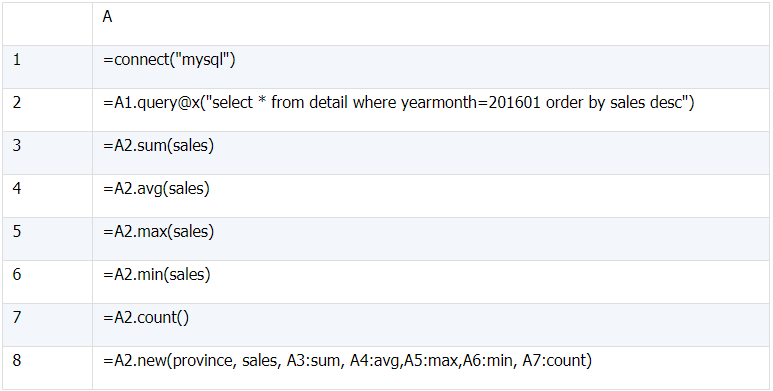
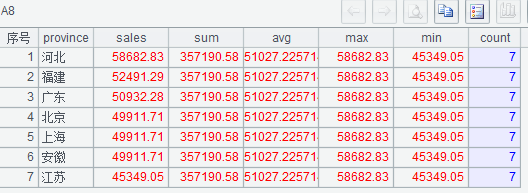
(1)A3 到 A7 依次对销售额求和、求平均、求最大、求最小及求总行数;
(2)A8 构造序表,其中每一行都有本月销售额总和、平均值、最大值、最小值及总行数
执行后 A8 的结果如下:
这个例子很常规,毫无挑战性,只是小练一把,下面开始玩真的。
b)
select yearmonth,province,sales,
sum(sales) over (partition by yearmonth) `sum`,
avg(sales) over (partition by yearmonth) `avg`,
max(sales) over (partition by yearmonth) `max`,
min(sales) over (partition by yearmonth) `min`,
count(*) over (partition by yearmonth) `count`
from detail
where yearmonth in (201601,201602) and sales>49500
order by yearmonth, sales desc;
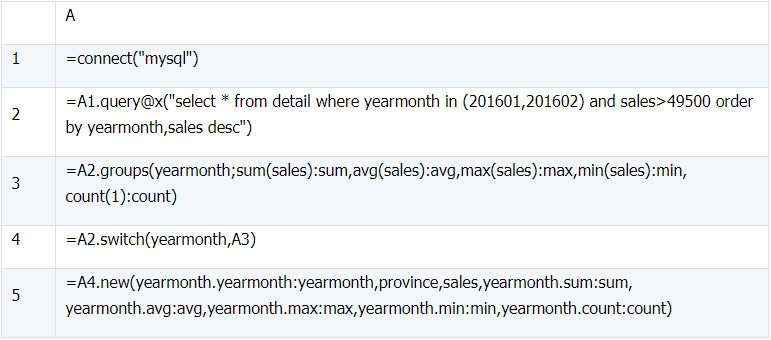
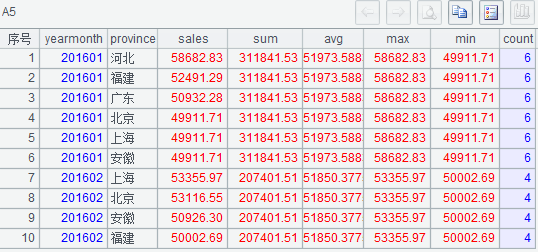
(1)A2 中按月份分组并对销售额求和、求平均、求最大、求最小及每组行数;
(2)A4 按月份将 A2 中 yearmonth 字段值转换成 A3 中相同月份的记录
执行后 A5 的结果如下。
2、VARIANCE()、STD()
a)
select province, sales, variance(sales) over() `variance`, std(sales) over() `std`
from detail where yearmonth=201601;
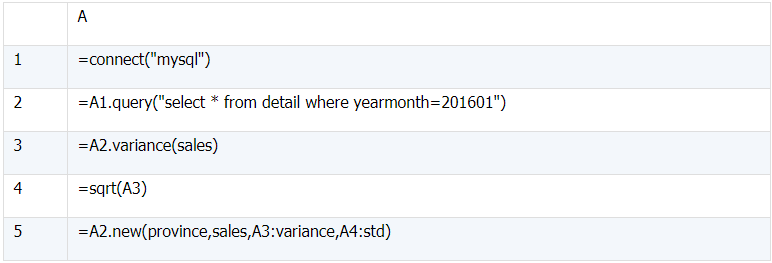
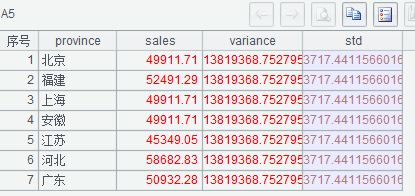
(1)A3 对销售额求方差。
(2)A4 对 A3 求平方根即为标准差
执行后 A5 的结果如下。
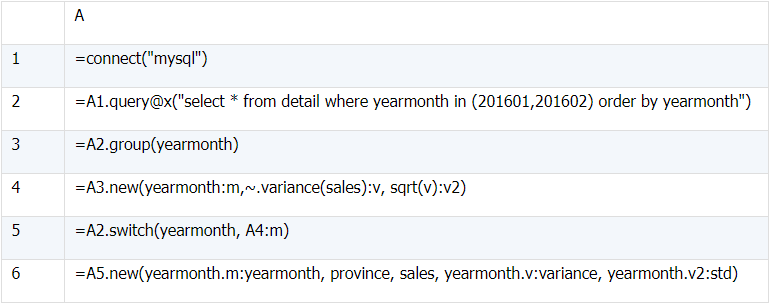
b)
select yearmonth, province, sales,
variance(sales) over(partition by yearmonth) `variance`,
std(sales) over(partition by yearmonth) `std`
from detail
where yearmonth in (201601, 201602);
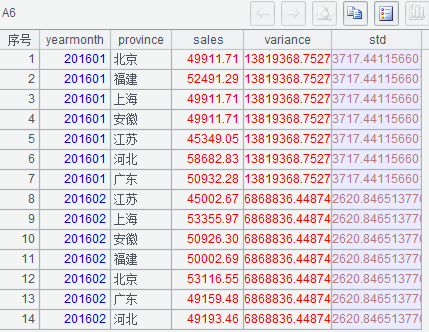
(1)A3 按月份分组
(2)A4 求每月销售额的方差
执行后 A6 的结果如下:
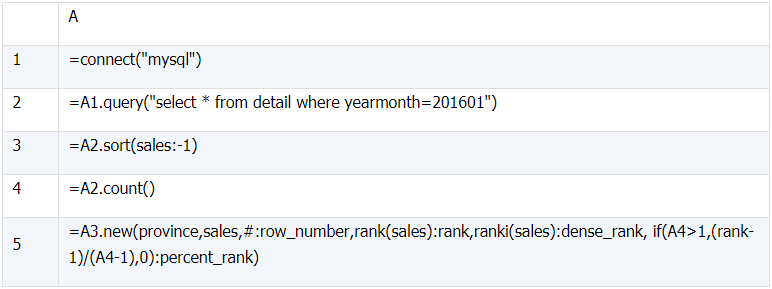
3、ROW_NUMBER()、RANK()、DENSE_RANK()、PERCENT_RANK()
a)
select province, sales, row_number() over(order by sales desc) `row_number`,
rank() over (order by sales desc) `rank`,
dense_rank() over (order by sales desc) `dense_rank`,
percent_rank() over (order by sales desc) `percent_rank`
from detail
where yearmonth=201601;
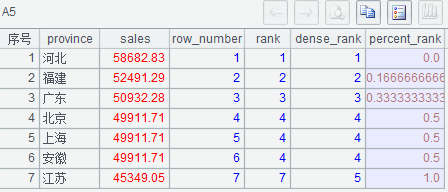
(1)A5 中 #表示当前行在 A3 中的序号
(2) 百分比排名的公式 =if(行数 >1,( 排名 -1)/(行数 -1))
执行后 A5 的结果如下:
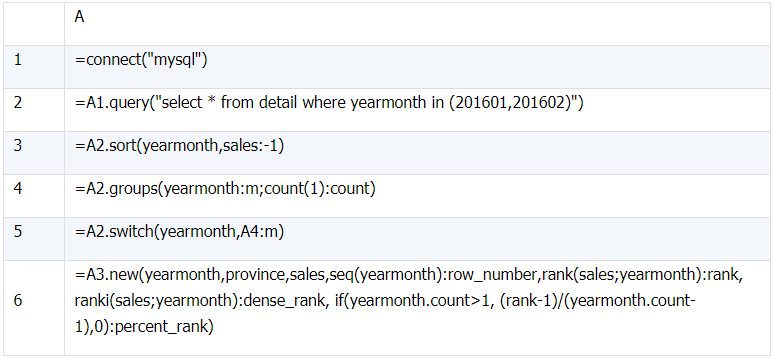
b)
select province, sales,
row_number() over(partition by yearmonth order by sales desc)
`row_number`,
rank() over (partition by yearmonth order by sales desc) `rank`,
dense_rank() over (partition by yearmonth order by sales desc)
`dense_rank`,
percent_rank() over (partition by yearmonth order by sales desc)
`percent_rank`
from detail
where yearmonth in (201601,201602);
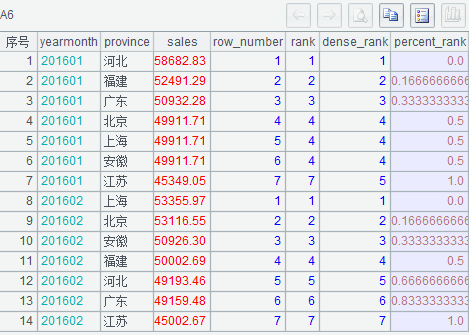
执行后 A6 的结果如下:
4、NTILE()
a)
select province, sales, ntile(3) over() `ntile`
from detail
where yearmonth=201601;
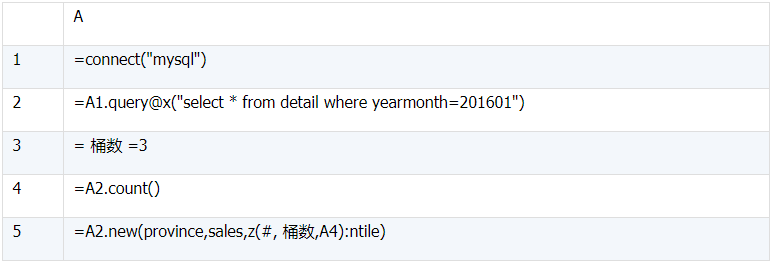
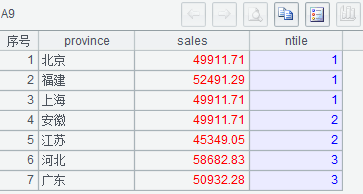
(1)A3 里指明桶数为 3
(2)A5 中 z(i, 桶数, 总行数) 计算第 i 行所在桶号
执行后 A9 的结果如下:
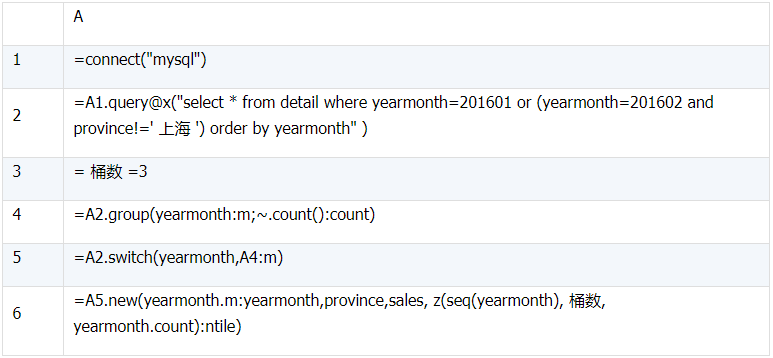
b)
select yearmonth, province, sales, ntile(3) over(partition by yearmonth)
`ntile`
from detail
where yearmonth=201601 or( yearmonth=201602 and province!='上海');
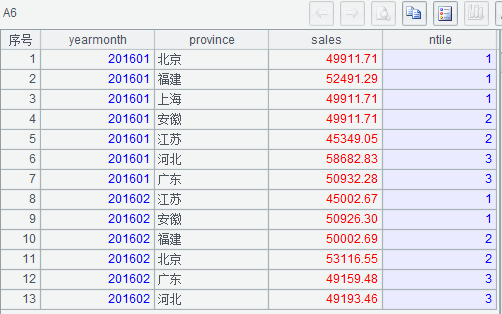
执行后 A6 的结果如下:
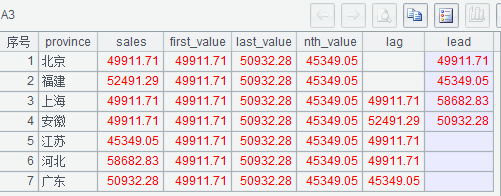
5、FIRST_VALUE()、LAST_VALUE()、NTH_VALUE()、LAG()、LEAD()
a)
select province,sales,
first_value(sales) over(partition by yearmonth) `first_value`,
last_value(sales) over(partition by yearmonth) `last_value`,
nth_value(sales, 5) over(partition by yearmonth) `nth_value`,
lag(sales, 2) over(partition by yearmonth) `lag`,
lead(sales, 3) over(partition by yearmonth) `lead`
from detail
where yearmonth=201601;
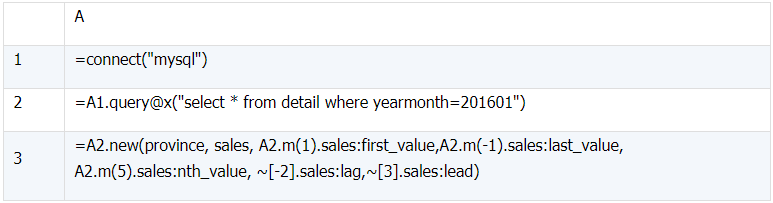
(1)Am(i) 取 A2 中第 i 条记录,越界返回 null,负数则从后往前数第 abs(i) 条记录,不能使用 A2(i),因为 A2(i) 越界会报错
执行后 A3 的结果如下:
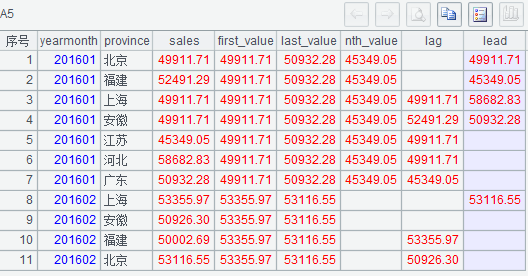
b)
select yearmonth,province,sales,
first_value(sales) over(partition by yearmonth) `first_value`,
last_value(sales) over(partition by yearmonth) `last_value`,
nth_value(sales, 5) over(partition by yearmonth) `nth_value`,
lag(sales, 2) over(partition by yearmonth) `lag`,
lead(sales, 3) over(partition by yearmonth) `lead`
from detail
where yearmonth=201601 or (yearmonth=201602 and sales>50000);

(1)A5 中,seq(yearmonth) 尽可能不要在 if 函数中使用,因为 seq 函数是在对 A2 中记录循环过程中累加的,导致 seq 函数少执行 1 次就少累加 1。
(2)A5 中,前面的表达式用 seq=seq(yearmonth) 对变量 seq 赋值,这样后续表达式就可以引用变量 seq。
执行后 A5 的结果如下:
6、CUME_DIST()
a)
select province,sales, cume_dist() over(order by sales) `cume_dist`
from detail
where yearmonth=201601;
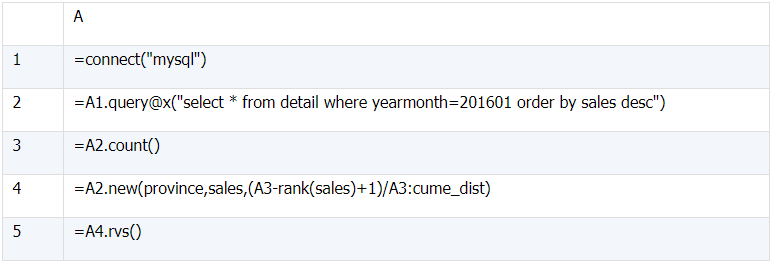
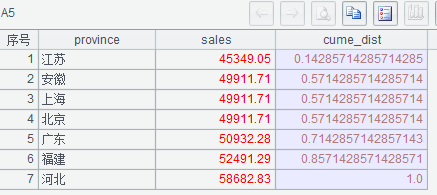
(1)CUME_DIST()over (order by sales) 求销售额从小到大的累积概率分布,公式为 (小于等于当前销售额的行数 / 总行数)
(2) 小于等于当前销售额的行数 = 总行数 - 当前销售额从大到小的排名 +1
(3)A2 必须按销售额从大到小排序
(4)A5 数据倒排
执行后 A5 的结果如下:
b)
select yearmonth, province,sales,
cume_dist() over(partition by yearmonth order by sales) `cume_dist`
from detail
where yearmonth in (201601,201602);
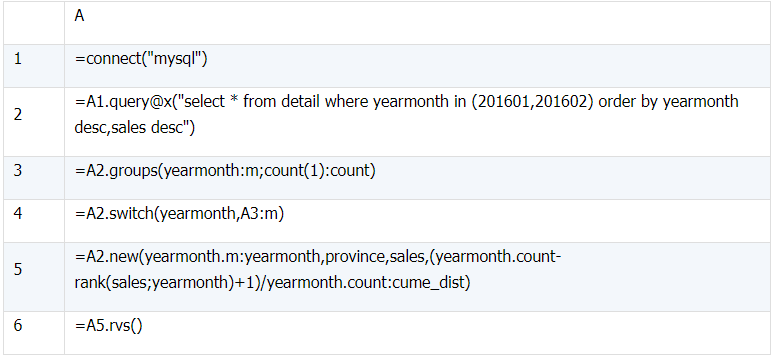
(1) 对应于最后的倒排,A2 中按月份从大到小排序
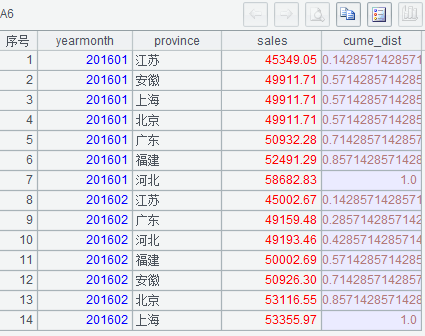
执行后 A6 的结果如下:
看完十多个例子,有没有觉得集算器代码实现 so easy?!而且,由于集算器可以对单元格进行分步计算,我们可以按照自然的思路逐步查看查询结果,从而更加简便、直观地完善整个查询脚本。赶紧用起来吧,你会发现更多又方便又强大的功能!