
TXT文本文件是我们常用的在应用之间传递数据的途径之一,因为它具有通用、灵活、易维护等诸多优点。不过并不是所有应用都提供了生成txt文件的功能,往往需要额外的程序设计和开发工作才能获得。这时如果能够有一个通用的工具软件,灵活地根据需要生成目标格式的文本,将能够极大地助力我们的业务工作。本文介绍的集算器就正是这样一款高效、灵活的通用工具软件,能够从不同数据源读取、计算并导出txt文件。
本文将着重介绍集算器的数据导出能力,而集算器本身强大的计算能力不是本文重点,因此文中没有刻意介绍数据源访问和计算过程。文中用到的函数请参看集算器文档《函数参考.chm》。
1. 简单导出数据
我们首先从简单的数据导出开始介绍:
1.1 导出新文件
下面这个例子中,通过两行简单读入和输出,完成了从数据源到TXT文件的导出。
A1单元格读入excel文件中的5年1班学生成绩,用来模拟可能通过计算得到的数据。
A2中的表达式将A1的数据导出到一个新的 “学生成绩表.txt”文件中。例子中使用了导出函数export。不过在这个最简单的例子中,我们没有指定额外的参数。由于没有指定x和F,因此将导出A1中的所有字段,同时保持字段名不变。由于没有指定列分隔符参数s,所以会用默认的tab分隔。不过函数使用了选项@t,因此会将字段名(excel文件的标题行)导出到第一行。

下图中就是导出的txt文件:

1.2 追加数据
假如“学生成绩表.txt”文件已经存在,我们需要在文件中再增加另一个班的成绩,那么应该怎么做呢?
与上例类似,在A1中读入要追加的5年2班的学生成绩,数据结构保持相同
A2中把数据导出到已有的“学生成绩表.txt”文件中,不过这时因为文件中已有标题,只需导出数据,因此不要加函数选项@t。同时,通过选项@a指明追加数据。

1.3 导出 csv
csv文件也是常见的纯文本文件,其中存储的表格数据以逗号分隔。如果要导出csv文件,有两种方式:
l 在导出时象下图那样加选项@c,或者
l 增加分隔参数,写成export@t(A1;",")
两种方式结果都是一样的。

导出结果如下:
学号,姓名,班级,性别,语文,数学,英语
110210,徐赵亚,5(1),男,80,60,86
110211,王莼礼,5(1),男,81,72,67
110212,沈花容,5(1),女,97,91,87
110213,李晓梅,5(1),女,86,69,73
2. 复杂导出数据
现在,我们看一下略为复杂的导出操作:
在上面的例子中我们引入一些新的需求:
l 在结果文件中增加一个序号列
l 在最后增加一个平均成绩列,并对平均成绩进行格式化保留一位小数
l 不导出学号
l 列间分隔符采用“\t| ”。

导出结果如下图所示:
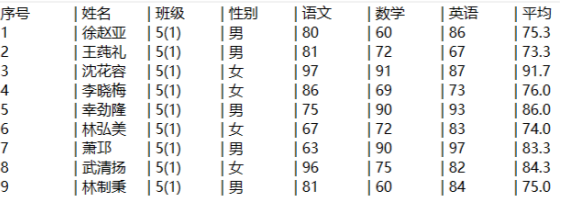
还是两行搞定!A1不用再说了,我们来看看A2的变化:#号在序表中表示记录编号,将它导出为结果中的序号列;指明导出姓名、班级、性别、语文、数学、英语列;表达式“string((语文 + 数学 + 英语 )/3,"#.0"): 平均”中,求出语文、数学、英语的平均数并格式化成只保留一位小数,命名导出的新列名为“平均”;最后一个参数指定列间分隔符为“\t| ”。
3. 导出大量数据
数据导出时还常常要面临另一个重要问题:如果数据量很大时又该怎么办?
为此,可以利用集算器提供的游标功能来处理大数据量的情况,游标在读取数据时从前向后遍历一次,逐条从数据源读取数据,而不是一次将所有数据读入内存,因此不会受到内存不足的限制。而且,集算器游标不仅可以应用于数据库,还可以应用于数据文件或者内存排列。
脚本如下图所示:

导出结果如下:
A1连接demo数据库
A2打开订单表作为游标
A3定义序号变量n,赋初值为0
A4是具体的导出过程,将游标所指的大数据导出到big.txt文件中。
对于大数据量的情况我们把游标作为导出数据源,而在前面的普通导出情况下则是把序表作为导出数据源。除了游标中不能以#代表记录号自动产生序号以外,两者用法完全相同。
为了产生序号,导出时利用A3中定义的变量n,在每导出一条数据时加1后导出为序号列即可。
4. 工资助手
最后,我们来看一个真正实战的例子:
当今企业给员工发工资一般都通过银行代发的方式。银行都提供了网上服务,企业可以通过这个途径来完成自助工资发放,具体的做法是:
银行提供了一个代发工资的文本文件格式,企业用户只要按格式编写此文件,再通过网上银行上载此文件,就可以完成工资发放。
下面我们就来看看如何利用集算器方便地完成代发工资文本文件的生成。
我们以民生银行为例,其文件格式如下:
ATNU:0019999
MICN:
CUNM:北京 XXXX 技术有限公司
MIAC:0110014180030254
EYMD:1
TOAM:80576.39
COUT:5
---------------------------------------
6226220101871111|19944.65|赵爱润 ||
6226220101872222|18349.08|孙学乾 ||
6226220101873333|15955.72|王老集 ||
6226220101874444|14360.15|张小算 ||
6226220101875555|11966.79|李大器 ||
此文件前 8 行是文件头,第 1、2、5、8 行内容固定不变,第 3 行是企业名称,第 4 行是企业在民生银行的账号,第 6 行是本次发工资的总金额,第 7 行是发工资的总笔数。从第 9 行开始是具体的工资信息,第一项是员工工资账号,第二项是工资金额,第三项是员工姓名,第四、五项空着不填就行。各项之间用竖线分隔。
此文本文件的格式要求非常严格,不能出错,因此不适合财务人员直接编辑,需要通过程序生成。
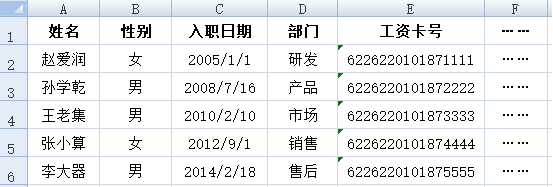
企业与工资相关的有两个 excel 表,一个是员工表,另一个是工资表,如下两图所示。

账务人员负责填好员工工资表后,就可以打开集算器 ide,运行预先编写好的 dfx 程序了:

A1中读入编写的员工表
B1中读入编写的工资表
A2中按姓名将两张表合并成一张表
A3打开要保存的代发工资文件
从 A4 到 B7 中逐行写入文件头:其中:B6 是工资总额,从 A2 中算出银行实发总额填入;A7 是本次代发的总笔数。
在 A8 中导出生成代发工资文件,分别是工资卡号、工资金额、姓名、空列、空列 (最后两列是不需要填的,所以用备注列代表)。
脚本中除了 A4 格是用替换写入以外,其它格都用了 @a 选项,表示是追加写入。
至于其它银行,过程大致与此类似。只要根据银行对文本文件格式的说明,编写好集算器 dfx 程序就可以了。
简单总结一下,在数据导出过程中,集算器提供了 write()和 export() 两个函数,前者是逐行写入,后者是批量写入。函数提供了参数和函数选项两种控制方法,使用不同的参数或函数选项,我们可以指定是否导出字段名 / 标题、是否导出所有字段、是否使用新的字段名、追加还是替换文件、使用哪个字符做分隔参数等等选择。
在见证了数据导出过程中集算器强大而灵活的能力后,是不是也有了莫名的冲动呢?赶快下载集算器,加入共同探索、一起变强的行列吧!