分类: 敏捷开发
2020-08-26 10:12:34
如今,提到人工智能,几乎无人不谈深度学习,似乎不用深度学习就不好意思谈人工智能。今天我们就用几分钟的时间来讲一下深度学习到底是什么,有什么用。
首先深度学习并不等于人工智能,它只是一种算法,和普通的机器学习算法一样,是解决问题的一种方法。真要区分起来,人工智能、机器学习和深度学习,三者大概是下图这种关系。人工智能是一个很大的概念,机器学习是其中的一个子集,而深度学习又是机器学习的一个子集。

其次,深度学习也不是什么新技术,深度学习的概念源于人工神经网络的研究,早在上世纪 40 年代,通用计算机问世之前,科学家就提出了人工神经网络的概念。而那个时候的计算机刚刚开始发展,速度非常慢,最简单的网络也得数天才能训练完毕,效率极其低下,因此在接下来的十几年都没有被大量使用。近些年,随着算力的提升,GPU、TPU 的应用,神经网络得到了重大发展。伴随着 AlphaGo 的胜利,深度学习也一战成名。
其实,同机器学习方法一样,深度学习方法也有监督学习与无监督学习之分。例如,卷积神经网络(Convolutional Neural Networks,简称 CNN)就是一种深度的监督学习下的机器学习模型,而深度置信网络(Deep Belief Nets,简称 DBN)就是一种无监督学习下的机器学习模型。深度学习的”深度“是指从”输入层“到”输出层“所经历层次的数目,即”隐藏层“的层数,层数越多,深度也越深。
所以越是复杂的选择问题,越需要深度的层次多。除了层数多外,每层”神经元“-小圆圈的数目也要多。例如,AlphaGo 的策略网络是 13 层,每一层的神经元数量为 192 个。深度学习的实质,是通过构建具有很多隐层的机器学习模型和海量的训练数据,来学习更有用的特征,从而最终提升分类或预测的准确性。
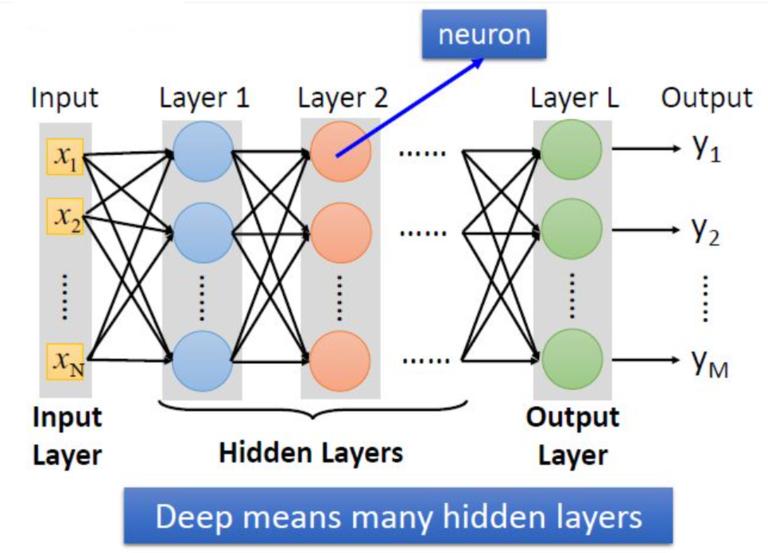
深度学习提出了一种让计算机自动学习出模式特征的方法,并将特征学习融入到了建立模型的过程中,从而减少了人为设计特征造成的不完备性。但是,在有限数据量的应用场景下,深度学习算法不能够对数据的规律进行无偏差的估计。为了达到很好的精度,需要海量数据的支撑。另外,深度学习中图模型的复杂化导致算法的时间复杂度急剧提升,为了保证算法的实时性,需要更高的并行编程技巧和更多更好的硬件支持。
在应用方面,虽然深度学习被吵得火热,但是也并不是无所不能。目前深度学习主要应用在图像识别,语音识别等领域。而在很多商业场景,例如金融数据,它的效果并不太好,很容易出现过拟合,这在机器学习中是非常致命的问题,即在训练数据上表现的很好,但是泛化能力却很差,在未见到的数据上,表现的很差。深度学习模型很容易受到数据中难以察觉的扰动,这些扰动会欺骗模型做出错误的预测或分类,而在很多场景的数据中是存在着大量噪音的。另外深度学习的过程是一个黑箱子,无法解释其做出的决策,这也导致在某些场景难以应用,比如一个银行审批贷款的深度学习系统,在拒绝了客户的贷款申请之后,而无法给出合理的解释,那么被自动拒绝了贷款的用户自然无法接受。深度学习模型需要海量的数据支撑,算法也比较复杂,模型的训练速度很慢,通常要几天甚至数周,同时还会耗费大量的计算资源,这也限制了它在各行业的广泛应用。
因此,深度学习只是机器学习的一种,和其它算法一样,有自己的长处也有不足。在实际应用中根据业务场景和问题选择合适的算法才能解决问题的有效方法,而不是看谁用了深度学习就去景仰。在一些自动建模产品中,一般也会集成深度学习算法,用户只要把数据丢进去,建模工具就会自动预处理数据,选择最优算法建好模型,使用起来非常简单方便。
对进一步数据挖掘和 AI 技术感兴趣的同学还可以搜索“乾学院”,上面有面向小白的零基础“数据挖掘”免费课程。
