https://blog.csdn.net/weixin_46600100/article/details/104960881?utm_source=app
https://blog.csdn.net/u014338577/article/details/82750771
我们知道,在linux操作系统中,CPU在执行一个进程的时候,都会访问内存。
但CPU并不是直接访问物理内存地址,而是通过虚拟地址空间来间接的访问物理内存地址。
所谓的虚拟地址空间,是操作系统为每一个正在执行的进程分配的一个逻辑地址,在32位机上,其范围从0 ~ 4G-1。操作系统通过将虚拟地址空间和物理内存地址之间建立映射关系,让CPU间接的访问物理内存地址。
通常将虚拟地址空间以512Byte ~ 8K,作为一个单位,称为页,并从0开始依次对每一个页编号。这个大小通常被称为页面
将物理地址按照同样的大小,作为一个单位,称为框或者块,也从0开始依次对每一个框编号。
操作系统通过维护一张表,这张表上记录了每一对页和框的映射关系。如图:
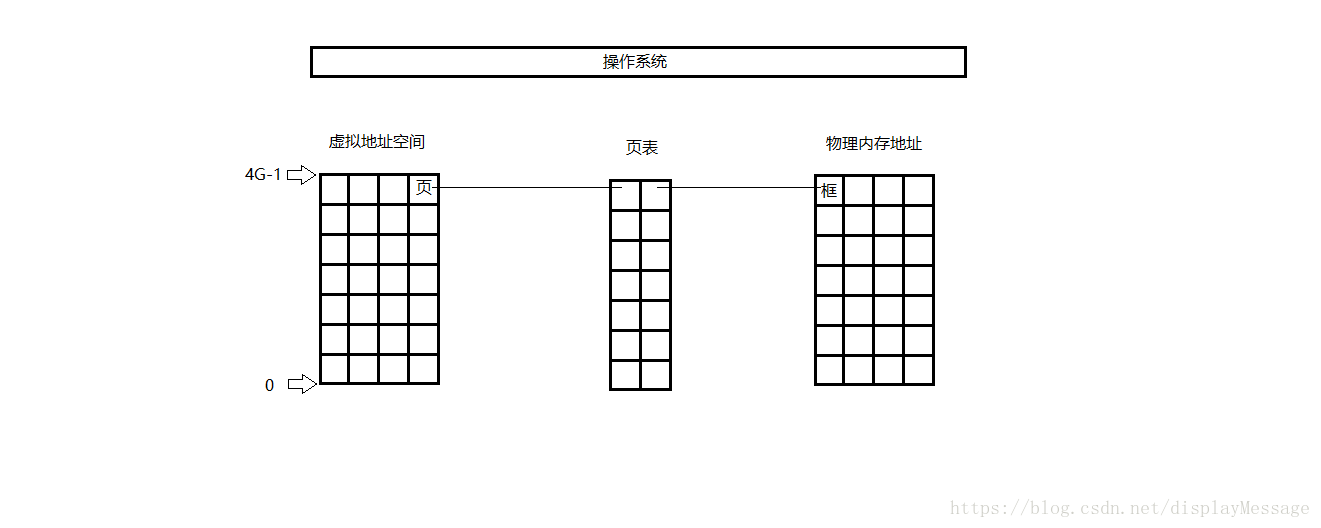 这张表,称为页表。
在windows系统下,页面为4k,这里我们以4k为例。
一个4G虚拟地址空间,将会产生1024*1024个页,页表的每一项存储一个页和一个框的映射,所以,至少需要1M个页表项。如果一个页表项大小为1Byte,则至少需要1M的空间,所以页表被放在物理内存中,由操作系统维护。
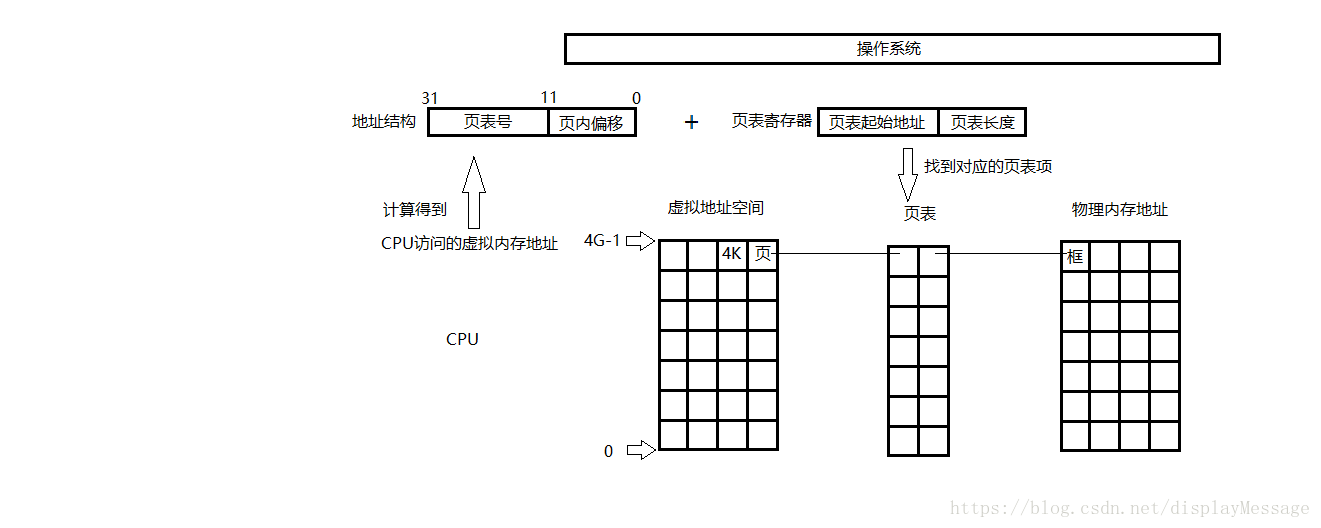
当CPU要访问一个虚拟地址空间对应的物理内存地址时,先将具体的虚拟地址A/页面大小4K,结果的商作为页表号,结果的余作为业内地址偏移。
例如:
CPU访问的虚拟地址:A
页面:L
页表号:(A/L)
页内偏移:(A%L)
CPU中有一个页表寄存器,里面存放着当前进程页表的起始地址和页表长度。将上述计算的页表号和页表长度进行对比,确认在页表范围内,然后将页表号和页表项长度相乘,得到目标页相对于页表基地址的偏移量,最后加上页表基地址偏移量就可以访问到相对应的框了,CPU拿到框的起始地址之后,再把页内偏移地址加上,访问到最终的目标地址。如图:
这张表,称为页表。
在windows系统下,页面为4k,这里我们以4k为例。
一个4G虚拟地址空间,将会产生1024*1024个页,页表的每一项存储一个页和一个框的映射,所以,至少需要1M个页表项。如果一个页表项大小为1Byte,则至少需要1M的空间,所以页表被放在物理内存中,由操作系统维护。
当CPU要访问一个虚拟地址空间对应的物理内存地址时,先将具体的虚拟地址A/页面大小4K,结果的商作为页表号,结果的余作为业内地址偏移。
例如:
CPU访问的虚拟地址:A
页面:L
页表号:(A/L)
页内偏移:(A%L)
CPU中有一个页表寄存器,里面存放着当前进程页表的起始地址和页表长度。将上述计算的页表号和页表长度进行对比,确认在页表范围内,然后将页表号和页表项长度相乘,得到目标页相对于页表基地址的偏移量,最后加上页表基地址偏移量就可以访问到相对应的框了,CPU拿到框的起始地址之后,再把页内偏移地址加上,访问到最终的目标地址。如图:
 注意,每个进程都有页表,页表起始地址和页表长度的信息在进程不被CPU执行的时候,存放在其PCB内。
按照上述的过程,可以发现,CPU对内存的一次访问动作需要访问两次物理内存才能达到目的,第一次,拿到框的起始地址,第二次,访问最终物理地址。CPU的效率变成了50%。为了提高CPU对内存的访问效率,在CPU第一次访问内存之前,加了一个快速缓冲区寄存器,它里面存放了近期访问过的页表项。当CPU发起一次访问时,先到TLB中查询是否存在对应的页表项,如果有就直接返回了。整个过程只需要访问一次内存。如图:
注意,每个进程都有页表,页表起始地址和页表长度的信息在进程不被CPU执行的时候,存放在其PCB内。
按照上述的过程,可以发现,CPU对内存的一次访问动作需要访问两次物理内存才能达到目的,第一次,拿到框的起始地址,第二次,访问最终物理地址。CPU的效率变成了50%。为了提高CPU对内存的访问效率,在CPU第一次访问内存之前,加了一个快速缓冲区寄存器,它里面存放了近期访问过的页表项。当CPU发起一次访问时,先到TLB中查询是否存在对应的页表项,如果有就直接返回了。整个过程只需要访问一次内存。如图:
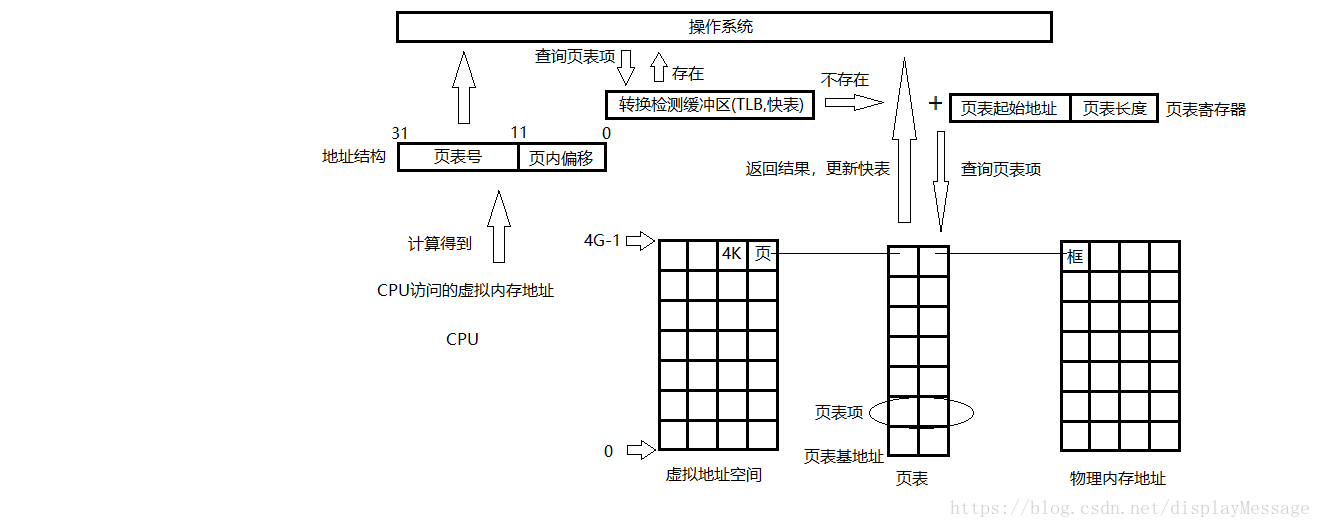 这种方式极大的提高了CPU对内存的访问效率。将近90%。
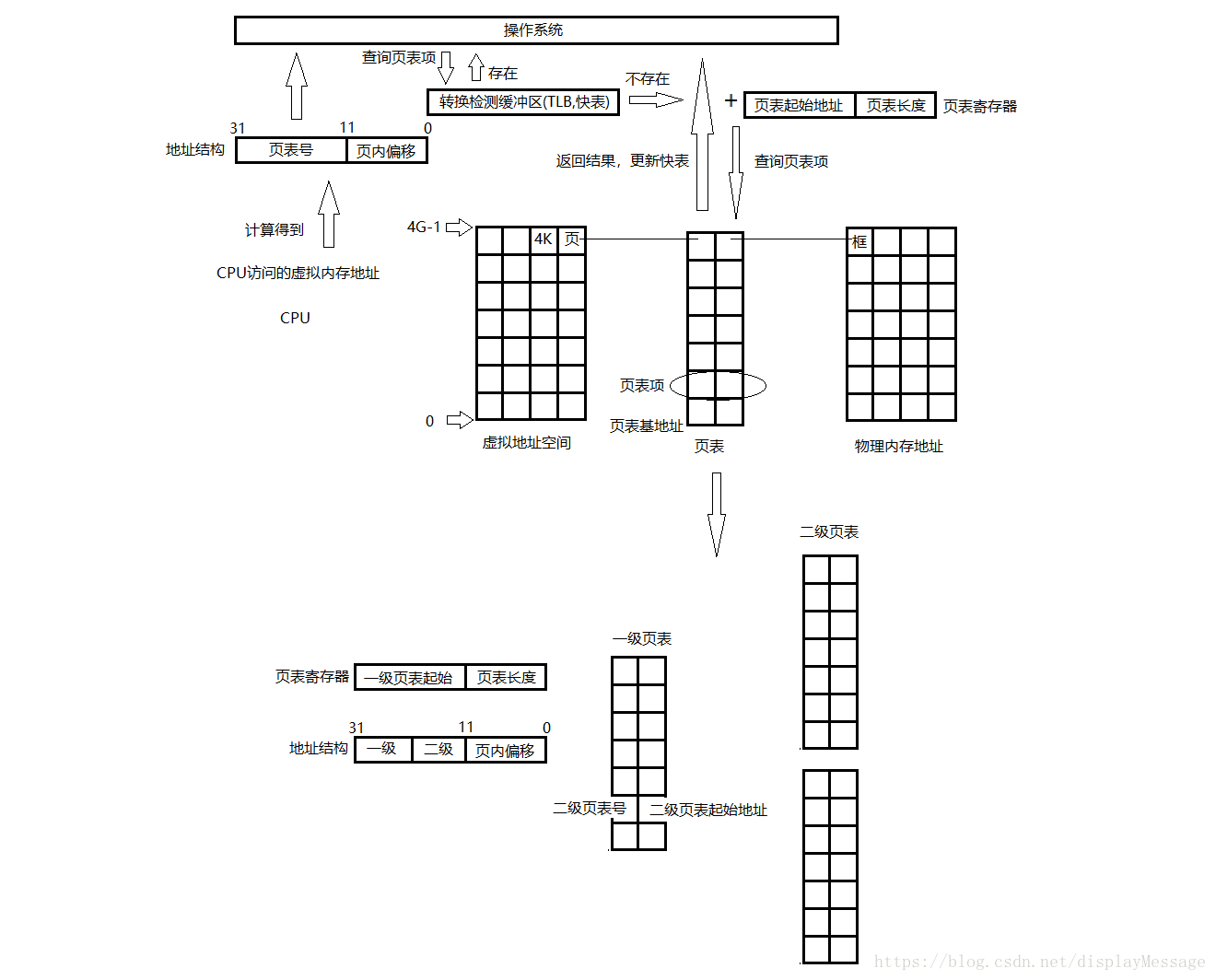
然而这样的方式还是存在弊端,在物理内存中需要拿出至少1M的连续的内存空间来存放页表。可以通过多级页表的方式,将页表分为多个部分,分别存放,这样就不要求连续的整段内存,只需要多个连续的小段内存即可。
把连续的页表拆分成多个页表称之为一级页表,再创建一张页表,这张页表记录每一张一级页表的起始地址并按照顺序为其填写页表号。
通过这样的方式,CPU从基地址寄存器中拿到了一级页表的地址,从地址结构中取出一级页表的页表号,找到二级页表的起始物理地址;然后结合地址结构中的中间10位(二级页表上的页表号),可以找到对应的框的起始地址,最后结合页内偏移量,就可以计算出最终目标的物理地址。如图:
这种方式极大的提高了CPU对内存的访问效率。将近90%。
然而这样的方式还是存在弊端,在物理内存中需要拿出至少1M的连续的内存空间来存放页表。可以通过多级页表的方式,将页表分为多个部分,分别存放,这样就不要求连续的整段内存,只需要多个连续的小段内存即可。
把连续的页表拆分成多个页表称之为一级页表,再创建一张页表,这张页表记录每一张一级页表的起始地址并按照顺序为其填写页表号。
通过这样的方式,CPU从基地址寄存器中拿到了一级页表的地址,从地址结构中取出一级页表的页表号,找到二级页表的起始物理地址;然后结合地址结构中的中间10位(二级页表上的页表号),可以找到对应的框的起始地址,最后结合页内偏移量,就可以计算出最终目标的物理地址。如图:
我们知道,CPU是通过寻址来访问内存的。32位CPU的寻址宽度是 0~0xFFFFFFFF ,16^8 计算后得到的大小是4G,也就是说可支持的物理内存最大是4G。
但在实践过程中,碰到了这样的问题,程序需要使用4G内存,而可用物理内存小于4G,导致程序不得不降低内存占用。
为了解决此类问题,现代CPU引入了 MMU(Memory Management Unit 内存管理单元)。
MMU 的核心思想是利用虚拟地址替代物理地址,即CPU寻址时使用虚址,由 MMU 负责将虚址映射为物理地址。
MMU的引入,解决了对物理内存的限制,对程序来说,就像自己在使用4G内存一样。
内存分页(Paging)是在使用MMU的基础上,提出的一种内存管理机制。它将虚拟地址和物理地址按固定大小(4K)分割成页(page)和页帧(page frame),并保证页与页帧的大小相同。
这种机制,从数据结构上,保证了访问内存的高效,并使OS能支持非连续性的内存分配。
在程序内存不够用时,还可以将不常用的物理内存页转移到其他存储设备上,比如磁盘,这就是大家耳熟能详的虚拟内存。
在上文中提到,虚拟地址与物理地址需要通过映射,才能使CPU正常工作。
而映射就需要存储映射表。在现代CPU架构中,映射关系通常被存储在物理内存上一个被称之为页表(page table)的地方。
如下图:

从这张图中,可以清晰地看到CPU与页表,物理内存之间的交互关系。
进一步优化,引入TLB(Translation lookaside buffer,页表寄存器缓冲)
由上一节可知,页表是被存储在内存中的。我们知道CPU通过总线访问内存,肯定慢于直接访问寄存器的。
为了进一步优化性能,现代CPU架构引入了TLB,用来缓存一部分经常访问的页表内容。
如下图:

对比前面那张图,在中间加入了TLB。
为什么要支持大内存分页?
TLB是有限的,这点毫无疑问。当超出TLB的存储极限时,就会发生 TLB miss,之后,OS就会命令CPU去访问内存上的页表。如果频繁的出现TLB miss,程序的性能会下降地很快。
为了让TLB可以存储更多的页地址映射关系,我们的做法是调大内存分页大小。
如果一个页4M,对比一个页4K,前者可以让TLB多存储1000个页地址映射关系,性能的提升是比较可观的。
调整OS内存分页
在Linux和windows下要启用大内存页,有一些限制和设置步骤。
Linux:
限制:需要2.6内核以上或2.4内核已打大内存页补丁。
确认是否支持,请在终端敲如下命令:
# cat /proc/meminfo | grep Huge
HugePages_Total: 0
HugePages_Free: 0
Hugepagesize: 2048 kB
如果有HugePage字样的输出内容,说明你的OS是支持大内存分页的。Hugepagesize就是默认的大内存页size。
接下来,为了让JVM可以调整大内存页size,需要设置下OS 共享内存段最大值 和 大内存页数量。
共享内存段最大值
建议这个值大于Java Heap size,这个例子里设置了4G内存。
# echo 4294967295 > /proc/sys/kernel/shmmax
大内存页数量
# echo 154 > /proc/sys/vm/nr_hugepages
这个值一般是 Java进程占用最大内存/单个页的大小 ,比如java设置 1.5G,单个页 10M,那么数量为 1536/10 = 154。
注意:因为proc是内存FS,为了不让你的设置在重启后被冲掉,建议写个脚本放到 init 阶段(rc.local)。
阅读(12021) | 评论(0) | 转发(0) |
