linux grep命令
不定时更新中。。。
一、作用
百度
二、格式
grep [options] ‘pattern’ filename
三、option主要参数
下面所列的参数主要是一些常用的参数。
|
编号
|
参数
|
解释
|
|
1
|
--version or -V
|
grep的版本
|
|
2
|
-A 数字N
|
找到所有的匹配行,并显示匹配行后N行
|
|
3
|
-B 数字N
|
找到所有的匹配行,并显示匹配行前面N行
|
|
4
|
-b
|
显示匹配到的字符在文件中的偏移地址
|
|
5
|
-c
|
显示有多少行被匹配到
|
|
6
|
--color
|
把匹配到的字符用颜色显示出来
|
|
7
|
-e
|
可以使用多个正则表达式
|
|
8
|
-f FILEA FILEB
|
FILEA在FILEAB中的匹配
|
|
9
|
-i
|
不区分大小写针对单个字符
|
|
10
|
-m 数字N
|
最多匹配N个后停止
|
|
11
|
-n
|
打印行号
|
|
12
|
-o
|
只打印出匹配到的字符
|
|
13
|
-R
|
搜索子目录
|
|
14
|
-v
|
显示不包括查找字符的所有行
|
新建一个test.txt,里面内容如下:
root@Ubunut10:~/shell# cat test.txt
a
bc
def
ght12
abc999
tydvl658
123
456
789abc
1.--version
显示grep的版本号
[root@localhost shell]# grep --version
GNU grep 2.6.3
Copyright (C) 2009 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.
[root@localhost shell]#
2. -A 数字N
找到所有的匹配行,并显示匹配行后面N行
[root@localhost shell]# grep -A 2 "a" test.txt
a //匹配字符’a’ 后面两行
bc
def
--
abc999
tydvl658
123
--
789abc
[root@localhost shell]#
3.-B 数字N
找到所有的匹配行,并显示匹配行前面N行
[root@localhost shell]# grep -B 2 "a" test.txt
a
--
def
ght12
abc999 //匹配字符’a’ 前面两行
--
123
456
789abc
[root@localhost shell]#
4.-b
显示匹配到的字符在文件中的偏移地址
[root@localhost shell]# grep -b "a" test.txt
0:a //在文件中的偏移地址
15:abc999
39:789abc
[root@localhost shell]#
5. -c
显示有多少行被匹配到
[root@localhost shell]# grep -c "a" test.txt
3 //在整个txt中,共有三个字符’a’被匹配到
[root@localhost shell]#
6.--color
把匹配到的字符用颜色显示出来
7.-e
可以使用多个正则表达式
[root@localhost shell]# grep -e "a" -e "1" test.txt
a //查找txt中字符 ‘a’ 和 字符 ‘1’
ght12
abc999
123
789abc
[root@localhost shell]#
8.-f FILEA FILEB
FILEA在FILEAB中的匹配
[root@localhost shell]# cat test.txt
a
bc
def
ght12
abc999
tydvl658
123
456
789abc
[root@localhost shell]# cat test1.txt
abc
[root@localhost shell]# grep -f test.txt test1.txt
abc
[root@localhost shell]# grep -f test1.txt test.txt
abc999
789abc
[root@localhost shell]#
9.-i
不区分大小写
[root@localhost shell]# cat test1.txt
ab
Ac
6356
AKF57
[root@localhost shell]# grep -i "a" test1.txt
ab //找出所有字符’a’ 并且不区分大小写
Ac
AKF57
[root@localhost shell]#
10.-m 数字N
最多匹配N个后停止
[root@localhost shell]# grep -m 2 "a" test.txt
a
abc999 //匹配2个后停止
[root@localhost shell]#
11.-n
打印行号
[root@localhost shell]# grep -n -m 2 "a" test.txt
1:a //打印出匹配字符的行号
5:abc999
[root@localhost shell]#
12.-o
会打印匹配到的字符
[root@localhost shell]# grep -n -o "a" test.txt
1:a
5:a
9:a
[root@localhost shell]#
13.-R
搜索子目录
[root@localhost shell]# mkdir 666 //创建一个子目录
[root@localhost shell]# cp test.txt 666/ //将txt复制到子目录里面
[root@localhost shell]# ls
666 test1.txt test.txt //当前目录有两个txt和一个子目录
[root@localhost shell]# grep "a" *
test1.txt:ab //只在当前目录查找字符’a’
test.txt:a
test.txt:abc999
test.txt:789abc
[root@localhost shell]# grep -R "a" *
666/test.txt:a //在当前目录和子目录查找字符’a’
666/test.txt:abc999
666/test.txt:789abc
test1.txt:ab
test.txt:a
test.txt:abc999
test.txt:789abc
[root@localhost shell]#
14.-v
显示不包括查找字符的所有行
[root@localhost shell]# grep -v "a" test.txt
bc
def
ght12
tydvl658
123
456
[root@localhost shell]#
四、pattern主要参数
|
编号
|
参数
|
解释
|
|
1
|
^
|
匹配行首
|
|
2
|
$
|
匹配行尾
|
|
3
|
[ ] or [ n - n ]
|
匹配[ ]内字符
|
|
4
|
.
|
匹配任意的单字符
|
|
5
|
*
|
紧跟一个单字符,表示匹配0个或者多个此字符
|
|
6
|
\
|
用来屏蔽元字符的特殊含义
|
|
7
|
\?
|
匹配前面的字符0次或者1次
|
|
8
|
\+
|
匹配前面的字符1次或者多次
|
|
9
|
X\{m\}
|
匹配字符X m次
|
|
10
|
X\{m,\}
|
匹配字符X 最少m次
|
|
11
|
X\{m,n\}
|
匹配字符X m---n 次
|
|
12
|
666
|
标记匹配字符,如666 被标记为1,随后想使用666,直接以 1 代替即可
|
|
13
|
\|
|
表示或的关系
|
新建一个text.txt
[root@localhost shell]# cat test.txt
a
bcd
1
233
abc123
defrt456
123abc
12568teids
abcfrt568
[root@localhost shell]#
1.^
匹配行首
[root@localhost shell]# grep -n '^a' test.txt
1:a //匹配以字符’a’开头的
5:abc123
9:abcfrt568
[root@localhost shell]#
[root@localhost shell]# grep -n '^abc' test.txt
5:abc123 //匹配以字符串”abc”开头的
9:abcfrt568
[root@localhost shell]#
2.$
匹配行尾
[root@localhost shell]# grep -n '33$' test.txt
4:233 //匹配以字符串”33”结束的
[root@localhost shell]# grep -n '3$' test.txt
4:233 //匹配以字符’3’结束的
5:abc123
[root@localhost shell]#
3.[ ]
匹配 [ ]内的字符,
可以使用单字符
如 [ 1] 即匹配含有字符’1’的字符串(示例1),
如 [ a] 即匹配含有字符’a’的字符串(示例2),
如 [ 1 2 3 ] 即匹配含有字符’1’ 或者 ’2’ 或者’3’ 的字符串(示例3),
也可以使用字符序列,用字符 ‘-’ 代表字符序列
如 [ 1-3 ] 即匹配含有字符’1’ 或者 ’2’ 或者’3’ 的字符串(示例4)
如 [ 1-3 a-b] 即匹配含有字符’1’ 或者 ’2’ 或者’3’ 或者 ’a’ 或者 ’b’的字符串(示例5)
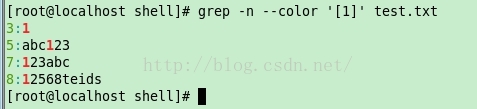
示例1:
[root@localhost shell]# grep -n --color '[1]' test.txt
3:1
5:abc123
7:123abc
8:12568teids
示例2:
[root@localhost shell]# grep -n --color '[a]' test.txt
1:a
5:abc123
7:123abc
9:abcfrt568
示例3:
[root@localhost shell]# grep -n --color '[1 2 3]' test.txt
3:1
4:233
5:abc123
7:123abc
8:12568teids
示例4:
[root@localhost shell]# grep -n --color '[1-3]' test.txt
3:1
4:233
5:abc123
7:123abc
8:12568teids
[root@localhost shell]#
示例5:
[root@localhost shell]# grep -n --color '[1-3 a-b]' test.txt
1:a
2:bcd
3:1
4:233
5:abc123
7:123abc
8:12568teids
9:abcfrt568
[root@localhost shell]#
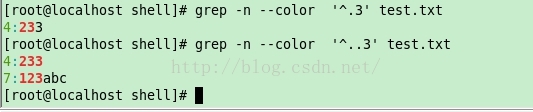
4. .
匹配任意的单字符
[root@localhost shell]# grep -n --color '^.3' test.txt
4:233 //任意字符开头然后第二个字符为 ‘3’
[root@localhost shell]# grep -n --color '^..3' test.txt
4:233 //任意两个字符开头,然后第三个字符为 ‘3’
7:123abc
[root@localhost shell]#
5. *
紧跟一个单字符,表示匹配0个或者多个此字符
下面例子的意思是,匹配字符’3’ 0次或者多次
[root@localhost shell]# grep -n --color '3*' test.txt
1:a
2:bcd
3:1
4:233
5:abc123
6:defrt456
7:123abc
8:12568teids
9:abcfrt568
10:3
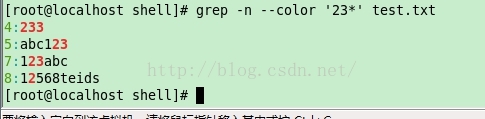
下面例子的意思是:匹配字符串”23”,但是 ‘3’ 被匹配的次数 >= 0
[root@localhost shell]# grep -n --color '23*' test.txt
4:233
5:abc123
7:123abc
8:12568teids
[root@localhost shell]#
6. \
用来屏蔽元字符的特殊含义
下面的例子的意思是 在字符串 "365.398" 中,查找’.’这个字符,而不是任意单字符
[root@localhost shell]# echo "365.398" | grep --color '.'
365.398
[root@localhost shell]# echo "365.398" | grep --color '\.'
365.398
[root@localhost shell]#
7. \?
匹配前面的字符0 次或者 多次
[root@localhost shell]# grep -n --color '3\?' test.txt
1:a
2:bcd
3:1
4:233
5:abc123
6:defrt456
7:123abc
8:12568teids
9:abcfrt568
下面例子的意思是:匹配字符串”33”但是 第二个字符‘3’只能匹配0次或者1次,因此实际匹配到的字符有“33 ”和 ‘3’这两种
[root@localhost shell]# grep -n --color '33\?' test.txt
4:233
5:abc123
7:123abc
下面例子的意思是:匹配字符串”23”但是 第二个字符‘3’只能匹配0次或者1次,因此实际匹配到的字符有“23 ”和 ‘2’这两种
[root@localhost shell]# grep -n --color '23\?' test.txt
4:233
5:abc123
7:123abc
8:12568teids
[root@localhost shell]#
8. \+
匹配前面的字符1次或者多次
[root@localhost shell]# grep -n --color '3\+' test.txt
4:233
5:abc123
7:123abc
9.X\{m\}
匹配字符X m次
[root@localhost shell]# grep -n --color '3\{1\}' test.txt
4:233
5:abc123
7:123abc
10.X\{m,\}
匹配字符X 最少m次
[root@localhost shell]# grep -n --color '3\{1,\}' test.txt
4:233
5:abc123
7:123abc
[root@localhost shell]#
11.X\{m,n\}
匹配字符X m---n 次
[root@localhost shell]# grep -n --color '3\{0,1\}' test.txt
1:a
2:bcd
3:1
4:233
5:abc123
6:defrt456
7:123abc
8:12568teids
9:abcfrt568
[root@localhost shell]#
13. \|
表示或的关系
[root@localhost shell]# grep -n --color 'ab∥23' test.txt
4:233
5:abc123
7:123abc
9:abcfrt568
五、示例
仅使用grep获取到ip,不使用其他 如 cut sed awk 命令
[root@localhost shell]# ifconfig eth0 | grep -o 'inetaddr:[0?9]{1,}\.\?\{1,\}' | grep --color -o '[0?9]{1,}\.\?\{1,\}'
菜鸟一枚,如有错误,多多指教。。。