分类: 系统运维
2011-01-01 15:36:54
无论采用什么技术编写网页代码,加载到浏览器上时都变成了HTML文档格式。在HTML文档中,文字内容都用各种HTML标签括起来。可以参照HTML标签或者参照标志性内容精确地将内容按照字段分别采集下来并存储到整理箱(专有名词,形象地表示结构化存储采集内容的容器)中。与精确采集相反,采集“内容片断”是指跨多个HTML标签,将这个片断中的文字内容采集下来。这种工作方式的一个极端案例是用普通网络爬虫建设基于全文索引的搜索引擎,将整个网页的文字内容一股脑采集下来。
既然有MetaSeeker的准确定位采集能力,还有必要采集文字内容片断吗?如果这个答案是肯定的,还有一个问题是:采集网页内容片断的粒度应该 怎样确定?实际上这些问题没有确切答案,当MetaSeeker用于商业目的时,用户一般会从运营维护成本角度进行权衡并回答上述问题。
一般来说,网页内容采集精度要求越高,采集规则越复杂,那么受目标网页结构变化的影响越大,虽然MetaSeeker采用包括FreeFormat技术在内的诸多专利技术设法提高采集规则的适应性,但是,目标网页的结构改变却不是网页内容采集者能够控制的。即便MetaSeeker的特有的低成本的采集规则修改功能可以帮助用户迅速调整采集规则,频繁改动或多或少地会增加运营成本。此时,就应该权衡一下是否总是需要最精确的采集规则。
个别客户采用MetaSeeker的自定义功能编写XPath和XSLT规则,例如,从一个HTML TEXT节点的字符串中用substring-after等函数将子串采集出来,可算是极其精确的采集了。这种采集规则受网页结构变化的影响最大。相反, 如果将跨多个HTML标签的内容片断采集到一个信息属性中,精度降低,适应性提高。
采集网页文字内容不是信息处理过程的最后一站,例如,建立,需要将采集结果入库,紧接着进行去噪、去重、分词、索引、分类、统计等等诸多处理过程。在这个处理过程链条上可以找到很多合适位置对采集到的HTML内容片断进行二次抽取和分割。
下面我们将用一个例子讲解采集网页文字内容片断的基本方法,自定义XPath或者XSLT规则也属于这个范畴,将在其它教程中详细解释。
注意:连续加载两个使用相同样本页面的信息结构会失败,观察MetaStudio底端的状态条,能够看到MetaStudio加载过程停顿了,状态条上没有显示“完成”字样。这是MetaStudio的bug,要避免,或者重启MetaStudio后再加载同一个信息结构。
加载《采集当当网百货价格》一文定义的主题名是demo_DD_list_1的信息结构,经常失败。
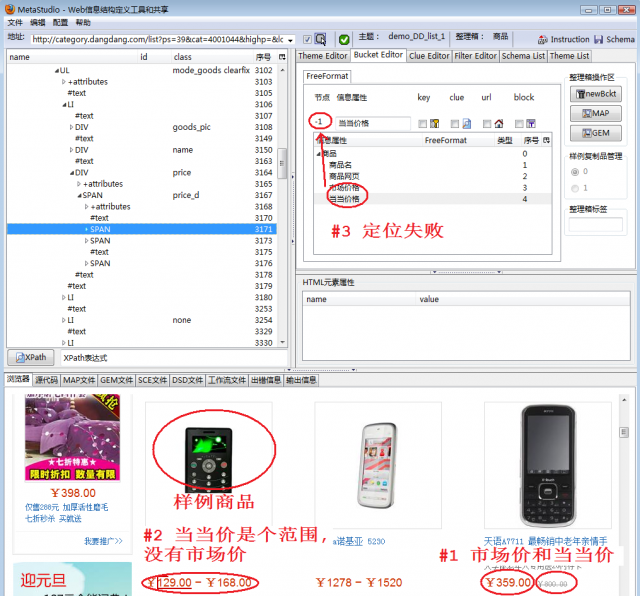
图1显示加载状态,并分析失败原因:
当遇到这种情况,如果仅仅按照《网页采集规则失效怎么办》一文介绍的方法修改信息结构无济于事,因为当当网展示的商品不断变化,排在第一个作为样例的商品会变化,以前成功地定义了demo_DD_list_1说明当时样例商品是正常的。另外,在这种情况下,MetaStudio加载信息结构失效不一定引起采集过程中DataScraper失败,所以,不一定非要采取措施修正这个问题,一般来说,只有看到DataScraper上报错误日志时再采取行动。DataScraper一般会上报:Suitable data schema cannot be found。
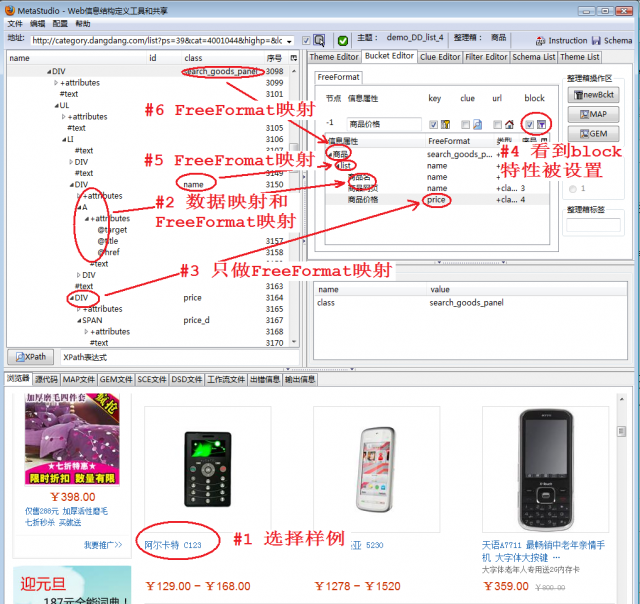
如图2,我们重新定义了采集规则,主题名改成 demo_DD_list_4,说明如下:
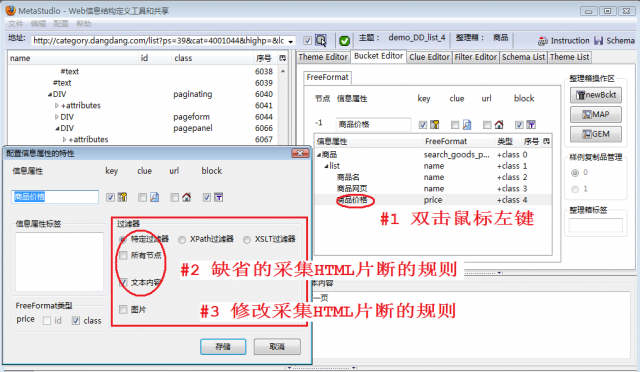
如图3,MetaStudio自动设置的block特性是可以修改的,步骤如下:
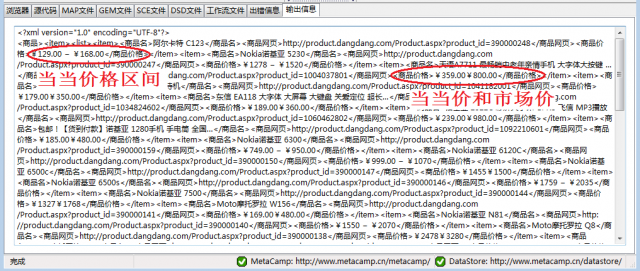
图4是MetaStudio上输出的采集结果片断,可以看到:
每个商品的这些价格信息都放在一个信息属性中,在处理采集结果时,需要根据存放规律将价格分割并抽取出来,例如,采用Java的正则表达式可以很容易将两个价格或者价格区间分割开。
chinaunix网友2011-03-08 18:04:10
很好的, 收藏了 推荐一个博客,提供很多免费软件编程电子书下载: http://free-ebooks.appspot.com
chinaunix网友2011-03-08 18:03:50
很好的, 收藏了 推荐一个博客,提供很多免费软件编程电子书下载: http://free-ebooks.appspot.com
