分类: 系统运维
2011-01-11 10:45:42
微博是一种新媒体和通信工具,上面有大量,首先需要将微博的内容抓取下来。单从微博的网页结构来说,上面的数据具有很规整的语义结构和元数据,所以,对于这 种旨在结构化网页数据的抓取工具来说,抓取微博的内容很容易。但是,从微博网站采用的编程技术来说,抓取微博又有很多障碍,最大的障碍是基于 Javascript/JS的AJAX程序框架,导致网络爬虫很难在微博网站上爬行和抓取数据。但是,MetaSeeker具有很强的AJAX内容抓取能 力,我们在《抓取AJAX网站》一文已经有所体验。本文将以抓取新浪微博为例,讲解MetaSeeker的一些重要特性。本文讲解的方法同样适用于抓取腾讯微博。
假设有下面的抓取目标:
注释1:登录前和登录后看到的内容数量有差别,定义上述网站抓取信息结构(用于自动生成抓取规则)时,事先登录了新浪微博,所以读者如果要用MetaStudio加载体验该信息结构,请事先通过火狐浏览器完成登录,否则可能加载失败,详细说明参见下节。
注释2:抓取AJAX网站的信息结构的加载方法有点不同,请参考《分页抓取卓越网的商品》
注释3:本文不是入门教程,如果对MetaSeeker的基本操作方法不熟悉,请按顺序阅读《MetaSeeker速成手册》
如果不登录新浪微博,访问上述样本网页看到的微博信息条数要少很多,所以,在运行之前先用Firefox访问新浪微博,完成登录。由于登录状态记录在cookie中,即便火狐浏览器退出了,在一定时间内登录状态还是有效的,在此期间运行MetaSeeker不用再次登录。
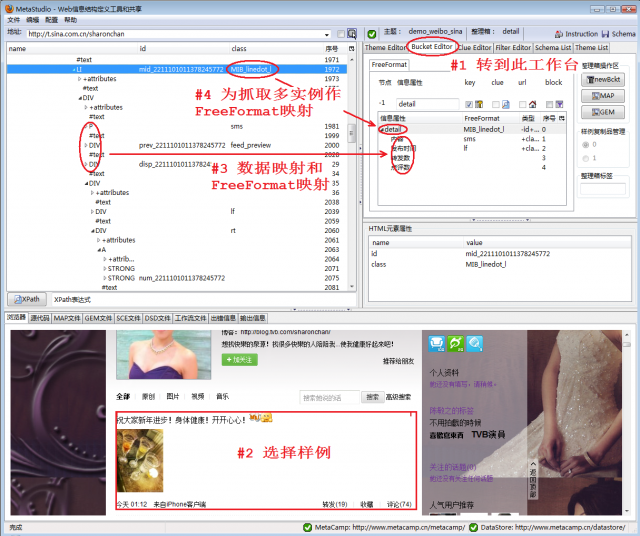
图1显示了如下步骤:
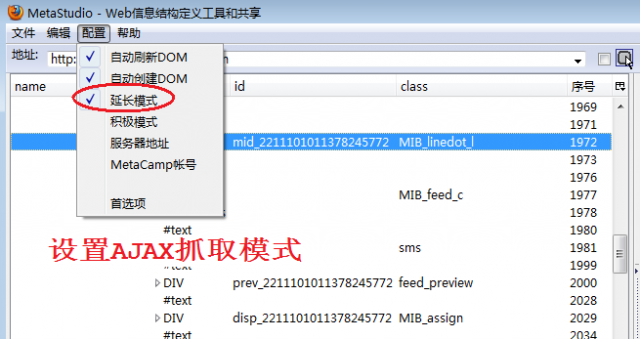
如图2所示,我们只选择了延长模式,而不像《分页抓取卓越网的商品》那样同时设置两个AJAX网页抓取模式,因为试验发现,转发数和点评数是在网页加载完成后才使用Javascript/JS程序从服务器异步加载的,所以,一定要设置延长模式。
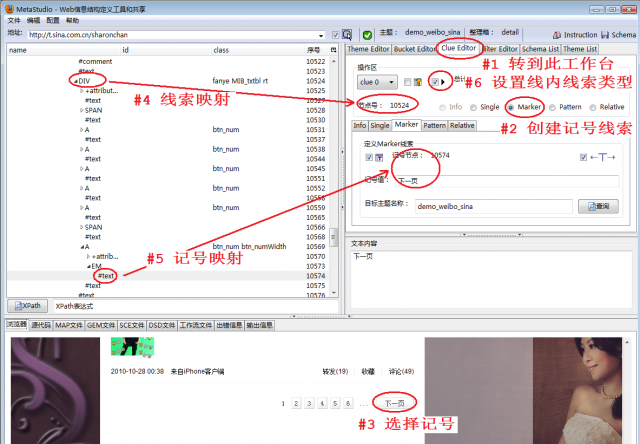
为了翻页抓取所有网页,需要定义线索抓取规则,而且应该设置成线内线索类型,详细操作步骤参见《批量抓取当当网价格数据》,本文只简单介绍一下步骤(如图3):
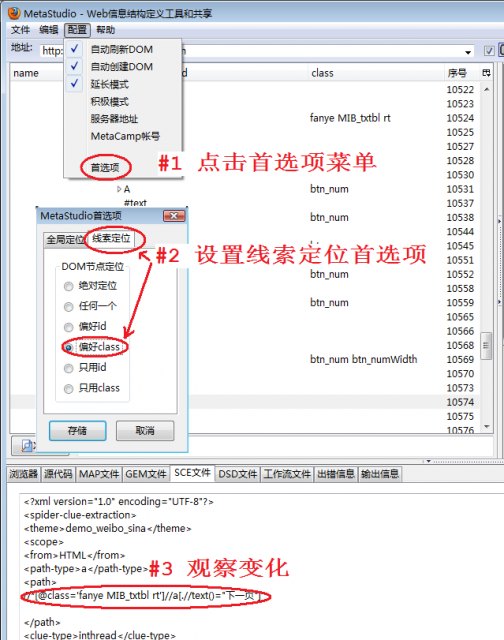
图4显示了怎样设置线索定位的首选项,这一步不是必须的,但是这样做可以提高抓取规则的适应度,也就是说即使目标网页结构修改了抓取规则受到的影响尽量小。原理说明参见,另一个应用案例参见
至此,信息结构定义完了,可以将它和自动生成的抓取规则一起上载到MetaSeeker服务器上,以便DataScraper随时随地使用这个抓取规则。很明显,信息结构定义过程与《分页抓取卓越网的商品》没有什么本质区别,但是,下面的章节我们可以看到需要更多高级技巧才能完整抓取新浪微博的内容。
用Firefox火狐浏览器阅读该样本网页上的微博消息时,如果网络速度不很快,会有一种特殊体验:微博消息很多,这个网页很长,需要拖动右侧的卷 滚条滚屏才能看全所有消息,当网速比较慢时,滚屏时先看到文字,然后是图片,然后是转发数和点评数。后者是异步加载的,没有滚动到可见范围就不从服务器上 下载这些内容。如果我们采用通常的抓取方法,势必只能抓取到前面几条消息的点评数和转发数,因此,必须要求DataScraper在抓取的时候自动滚屏。
这种情形不仅发生在微博网站上,有些网站的网页上有大量图片,为了提高网页下载速度,一般也是在滚屏时才下载图片,例如网站就是这样。
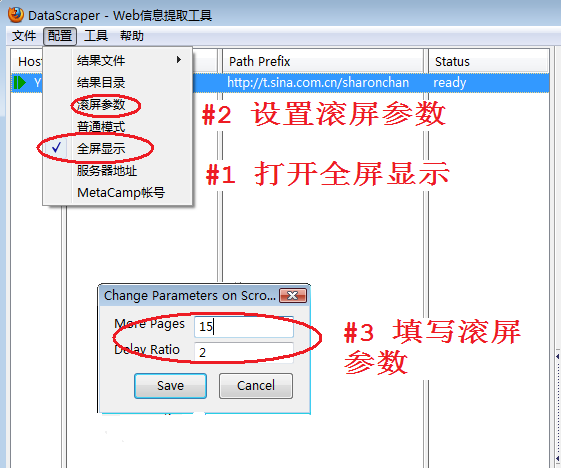
图5显示了设置滚屏参数的步骤:
如果采用周期性自动抓取模式,请参考修改crontab.xml文件的相关参数。
注释:本例将More Pages设置成15,当网络速度很慢的时候,也许30更合适,这样预留更多时间等待所有点评数和转发数加载上。
新浪微博上的照片尺寸很大,而且数量很多,下载时间很长,做Web数据挖掘系统时,图片一般不需要,如果能够阻止下载图片,将大大加快速度,如果您使用企业版,请参考。
chinaunix网友2011-03-07 14:21:09
很好的, 收藏了 推荐一个博客,提供很多免费软件编程电子书下载: http://free-ebooks.appspot.com
