C++,python,热爱算法和机器学习
全部博文(1214)
分类: 服务器与存储
2020-06-21 22:29:36
如下图,本人觉得这些始终有些抽象
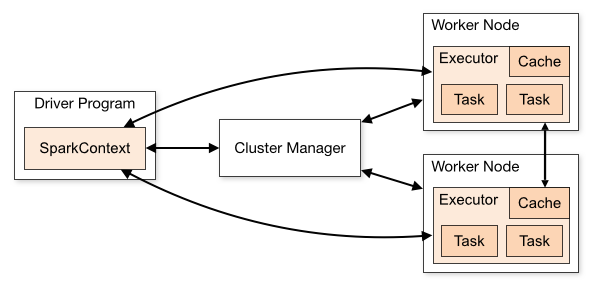
看到这样的图,我很想知道driver program在哪里啊,鬼知道?为此我自己研究了一下,网友大多都说是对的有不同想法的请评论
-
192.168.10.82 –>bigdata01.hzjs.co
-
192.168.10.83 –>bigdata02.hzjs.co
-
192.168.10.84 –>bigdata03.hzjs.co
集群的slaves文件配置如下:
-
bigdata01.hzjs.co
-
bigdata02.hzjs.co
-
bigdata03.hzjs.co
那么这三台机器都是worker节点,本集群是一个完全分布式的集群经过测试,我使用# ./start-all.sh ,那么你在哪台机器上执行的哪台机器就是7071 Master主节点进程的位置,我现在在192.168.10.84使用./start-all.sh
那么就会这样


现在假设我在192.168.10.84上执行了 bin]# spark-shell 那么就会在192.168.10.84产生一个SparkContext,此时84就是driver,其他woker节点(三台都是)就是产生executor的机器。如图

现在假设我在192.168.10.83上执行了 bin]# spark-shell 那么就会在192.168.10.83产生一个SparkContext,此时83就是driver,其他woker节点(三台都是)就是产生executor的机器。如图

总结:在local模式下 驱动程序driver就是执行了一个Spark Application的main函数和创建Spark Context的进程,它包含了这个application的全部代码。(在那台机器运行了应用的全部代码创建了sparkContext就是drive,也可以说是你提交代码运行的那台机器)

现在假设我在192.168.10.83上执行了 bin]# spark-shell 192.168.10.84:7077 那么就会在192.168.10.84产生一个SparkContext,此时84就是driver,其他woker节点(三台都是)就是产生executor的机器。这里直接指定了主节点driver是哪台机器:如图

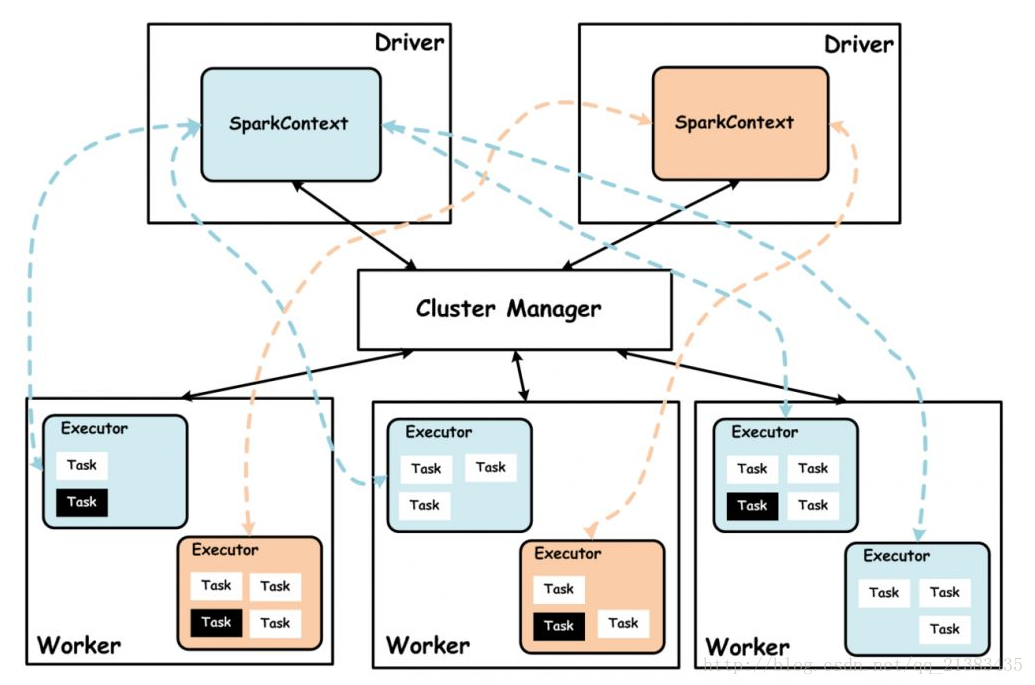
Driver: 使用Driver这一概念的分布式框架有很多,比如hive,Spark中的Driver即运行Application的main()函数,并且创建SparkContext,创建SparkContext的目的是为了准备Spark应用程序的运行环境,在Spark中由SparkContext负责与ClusterManager通讯,进行资源的申请,任务的分配和监控等。当Executor部分运行完毕后,Driver同时负责将SaprkContext关闭,通常SparkContext代表Driver.
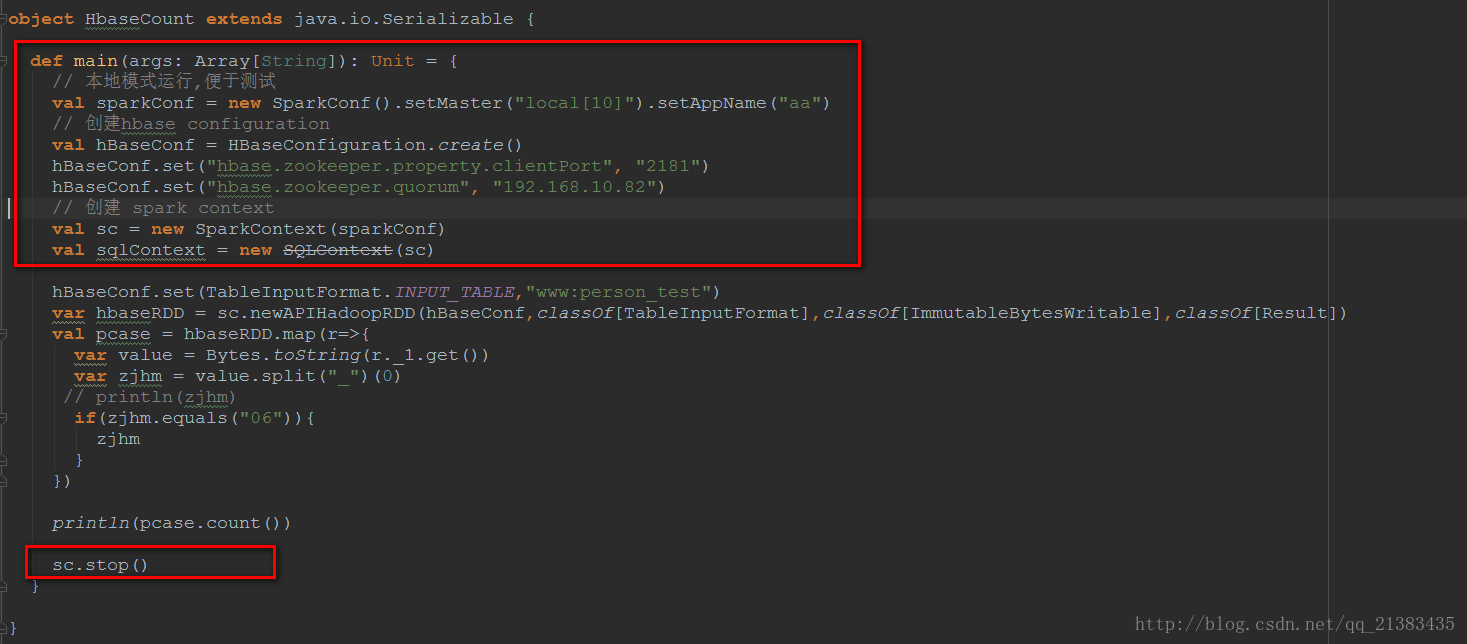
上面红色框框都属于Driver,运行在Driver端,中间没有框住的部分属于Executor,运行的每个ExecutorBackend进程中。println(pcase.count())collect方法是Spark中Action操作,负责job的触发,因为这里有个sc.runJob()方法
def count(): Long = sc.runJob(this, Utils.getIteratorSize _).sum
hbaseRDD.map()属于Transformation操作。
总结:Spark Application的main方法(于SparkContext相关的代码)运行在Driver上,当用于计算的RDD触发Action动作之后,会提交Job,那么RDD就会向前追溯每一个transformation操作,直到初始的RDD开始,这之间的代码运行在Executor。
