柔中带刚,刚中带柔,淫荡中富含柔和,刚猛中荡漾风骚,无坚不摧,无孔不入!
全部博文(1669)
分类: 架构设计与优化
2016-03-21 16:54:14
http://www.cnblogs.com/sammyliu/p/4905726.html
一周前,由 Intel 与 Redhat 在10月18日联合举办了 Shanghai Ceph Day。在这次会议上,多位专家做了十几场非常精彩的演讲。本文就这些演讲中提到的 Ceph性能优化方面的知识和方法,试着就自己的理解做个总结。
(1). 硬件层面
(2). 软件层面
更多信息,可以参考下面的文章:
显然这不是一个 Ceph 的新特性,在会议上有这方面的专家详细地介绍了该特性的原理及用法,以及与纠错码方式结合的细节。
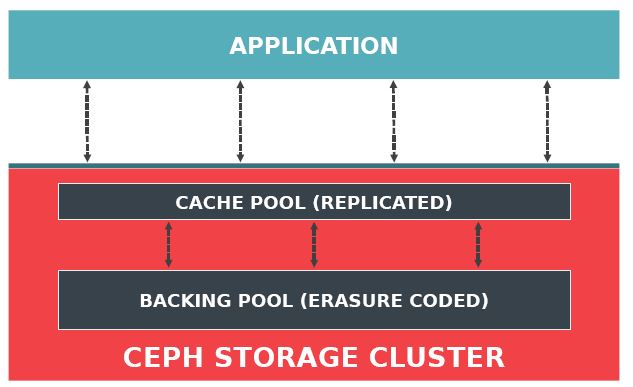
简单概括:
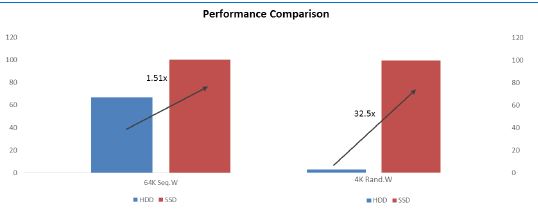
在 Ceph 集群中,往往使用 SSD 来作为 Journal(日志)和 Caching(缓存)介质,来提高集群的性能。下图中,使用 SSD 作为 Journal 的集群比全 HDD 集群的 64K 顺序写速度提高了 1.5 倍,而 4K 随机写速度提高了 32 倍。
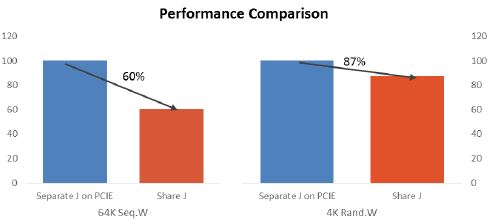
而Journal 和 OSD 使用的 SSD 分开与两者使用同一块SSD,还可以提高性能。下图中,两者放在同一个 SATA SSD 上,性能比分开两块 SSD (Journal 使用 PCIe SSD,OSD 使用 SATA SSD),64K 顺序写速度下降了 40%,而 4K 随机写速度下降了 13%。
因此,更先进的 SSD 自然能更加提高Ceph 集群的性能。SSD 发展到现在,其介质(颗粒)基本经过了三代,自然是一代比一代先进,具体表现在密度更高(容量更大)和读写数据更快。目前,最先进的就是 Intel NVMe SSD,它的特点如下:
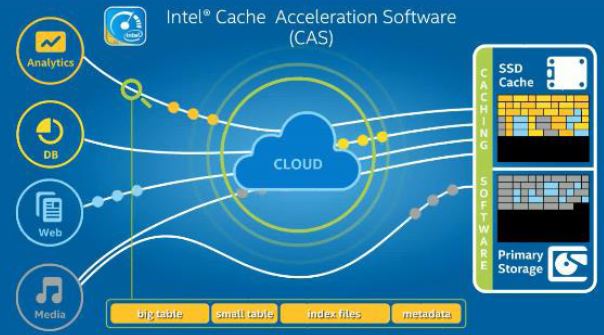
同时,Intel SSD 还可以结合 Intel Cache Acceleration Software 软件使用,它可以智能地根据数据的特性,将数据放到SSD或者HDD:
测试:
Mellanox 是一家总部在以色列的公司,全球约 1900 名员工,专注高端网络设备,2014 年revenue 为 ¥463.6M 。(今天正好在水木BBS上看到该公司在中国的分公司待遇也是非常好)。其主要观点和产品:
实际测试:
(1)测试环境:Cluster network 使用 40GbE 交换机,Public network 分布使用 10 GbE 和 40GbE 设备做对比

(2)测试结果:结果显示,使用 40GbE 设备的集群的吞吐量是使用 10 GbE 集群的 2.5 倍,IOPS 则提高了 15%。
目前,已经有部分公司使用该公司的网络设备来生产全SSD Ceph 服务器,比如,SanDisk 公司的 InfiniFlash 就使用了该公司的 40GbE 网卡、2个 Dell R720 服务器作为 OSD 节点、512 TB SSD,它的总吞吐量达到 71.6 Gb/s,还有富士通和Monash 大学。
传统上,访问硬盘存储需要几十毫秒,而网络和协议栈需要几百微妙。这时期,往往使用 1Gb/s 的网络带宽,使用 SCSI 协议访问本地存储,使用 iSCSI 访问远端存储。而在使用 SSD 后,访问本地存储的耗时大幅下降到几百微秒,因此,如果网络和协议栈不同样提高的话,它们将成为性能瓶颈。这意味着,网络需要更好的带宽,比如40Gb/s 甚至 100Gb/s;依然使用 iSCSI 访问远端存储,但是 TCP 已经不够用了,这时 RDMA 技术应运而生。RDMA 的全称是 Remote Direct Memory Access,就是为了解决网络传输中服务器端数据处理的延迟而产生的。它是通过网络把资料直接传入计算机的存储区,将数据从一个系统快速移动到远程系统存储器中,而不对操作系统造成任何影响,这样就不需要用到多少计算机的处理功能.它消除了外部存储器复制和文本交换操作,因而能腾出总线空间和CPU 周期用于改进应用系统性能. 通用的做法需由系统先对传入的信息进行分析与标记,然后再存储到正确的区域。
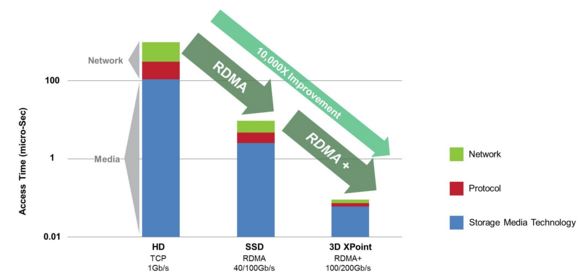
这种技术上,Mellanox 是业界领先者。它通过 Bypass Kenerl 和 Protocol Offload 的实现,提供高带宽、低CPU占用和低延迟。目前,该公司在 Ceph 中实现了 XioMessager,使得Ceph 消息不走 TCP 而走 RDMA,从而得以提高集群性能,该实现在 Ceph Hammer 版本中提供。
更多信息,可以参考:
<2015/11/26 更新>
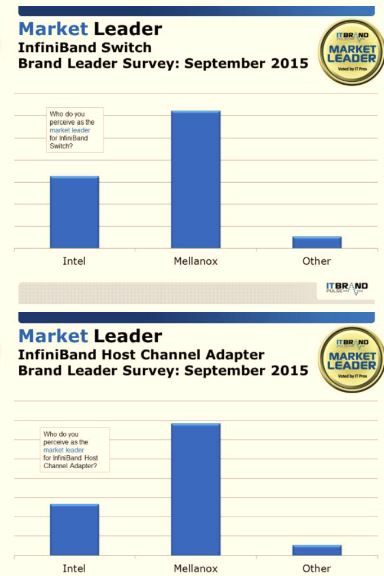
之前不熟悉这个公司,一个原因是其名字实在太长太难记了。今天看到西瓜哥的微信,才发现这个公司的Infiniband 交换机和 HBA 卡在美国数据中心里面的领导地位。唯一能和它竞争的就是Intel。
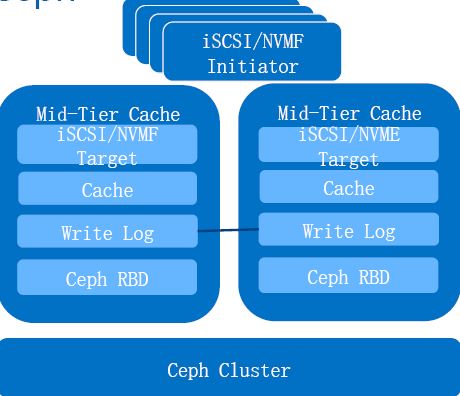
该方案在客户端应用和 Ceph 集群之间添加一个缓存层,使得客户端的访问性能得以提高。该层的特点:
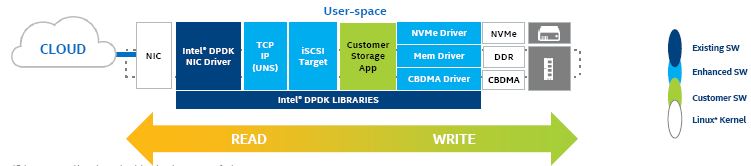
Intel 使用该技术,在用户空间(user space)实现了全 DPDK 网卡及驱动、TCP/IP协议栈(UNS)、 iSCSI Target,以及 NVMe 驱动,来提高Ceph的 iSCSI 访问性能。好处:
该方案的一大特点是使用用户态网卡,为了避免和内核态的网卡冲突,在实际配置中,可以通过 SRIOV 技术,将物理网卡虚拟出多个虚拟网卡,在分配给应用比如OSD。通过完整地使用用户态技术,避免了对内核版本的依赖。
目前,Intel 提供 Intel DPDK、UNS 、优化后的 Storage 栈作为参考性方案,使用的话需要和 Intel 签订使用协议。用户态NVMe驱动已经开源。
该代码库(code libaray)使用 Intel E5-2600/2400 和 Atom C2000 product family CPU 的新指令集来实现相应算法,最大化地利用CPU,大大提高了数据存取速度,但是,目前只支持单核 X64 志强和 Atom CPU。在,EC 速度得到几十倍提高,总体成本减少了百分之25到30.

本次会议上,还发布了若干Ceph 性能测试和调优工具。
Intel的该工具可以用来部署、测试、分析和调优(deploy, benchmark, analyze and tuning)Ceph 集群,目前它已经被开源,代码 。主要功能包括:
Ceph 软件栈(可能的性能故障点和调优点):
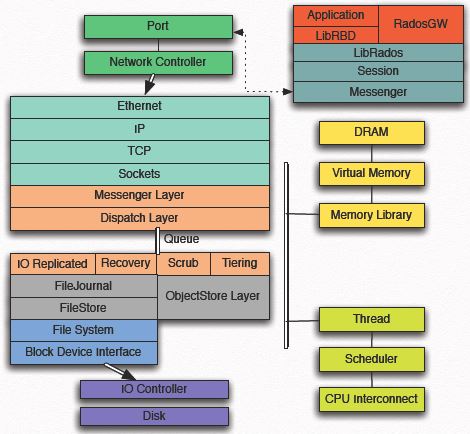
可视性性能相关工具汇总:

Benchmarking 工具汇总:

调优工具汇总:

上面的几种方法,与传统的性能优化方法相比,部分具有其创新性,其中,
注:以上所有内容皆来自于本次会议上展示的资料以及会后发送的资料。如有内容不合适在本文发布,请与本人联系。再次感谢 Intel 和 RedHat 举办本次会议。
