来自农村的老实娃
分类: Oracle
2011-08-03 13:38:04
了解该特性对数据不会频繁改变的数据库(如数据仓库或报表数据库环境)的好处。
Oracle Real Application Clusters (RAC) 是一个集群数据库解决方案,为业务统一体提供可伸缩性和可用性。“可伸缩性”是一种相对说法,基于这样一种简单的规则:随着访问系统的用户数量增加,RAC 配置应能够应对这种用户数量增加。然而,重要的是,仅当应用程序在单实例 Oracle 环境中能够伸缩时,它在集群环境中才能够伸缩 — 如果应用程序是在 CPU 数量从 2 增加到 4、6、8 的情况下在一台服务器上进行伸缩的,将无法在 RAC 环境中伸缩。基本上,Oracle RAC 无法上演修复性能低下的应用程序代码的奇迹。(相比之下,可用性是系统在一个或多个组件发生故障时提供连续服务的能力。)
在可伸缩的系统中,负载必须透明地分布在集群中的所有节点上,实现真正负载平衡的环境。为了实现此目标,Oracle RAC 架构允许通过互连在实例间移动缓存的数据,否则若需要使用物理 I/O,代价将十分高昂。
例如,Oracle 数据库的结果缓存特性是在 Oracle Database 11g 第 1 版中引入的,该特性因其在内存中缓存 SQL 查询和 PL/SQL 函数结果的能力而备受关注。因此,在 Oracle RAC 环境中,相同查询或函数的多次执行可直接由缓存中的一个数据集处理,而无需在每次需要时通过互连移动数据集。在本文中,您将了解该特性的工作原理。
缓存:Oracle 提供了多种类型和形式的缓存:库缓存、缓冲区缓存、字典缓存、数据库缓存、保留缓存、回收缓存等。通过缓存数据来提高性能是 Oracle 架构长久以来的目标。
初次执行一项查询时,用户进程将在数据库缓冲区缓存中搜索数据。如果找到了数据(因为以前有人检索过此数据),则使用此数据;否则将执行 I/O 操作,将磁盘上数据文件中的数据检索到缓冲区缓存中,生成最终结果集。
随后,如果另一个查询需要相同的数据集,该进程将使用来自缓冲区缓存的数据生成用户所需的结果集。 如果缓冲区缓存包含可重用的数据,那么这个新增的结果缓存是什么?简而言之,结果缓存可以被称作缓存(在本文中是一个共享池)中的缓存区。因此,结果缓存是共享池中的一个区域,包含查询执行的最终结果。
这意味着什么?让我们通过一个示例来加深了解;以下查询是在 Oracle Database 11g 第 2 版数据库中执行的:
SELECT OL_NUMBER, SUM (OL_AMOUNT), SUM (OL_QUANTITY)
FROM ORDER_LINE OL, ORDERS ORD
WHERE OL.OL_O_ID = ORD.O_ID AND
OL.OL_W_ID = ORD.O_W_ID AND
OL.OL_D_ID = ORD.O_D_ID
GROUP BY OL_NUMBER;
跟踪文件的 tkprof 报告的输出显示,查询遍历了超过 347,000 行,提供了包含 300 行摘要数据的最终输出,即结果集。
call count cpu elapsed disk query current rows ------- ------ -------- ---------- ---------- ---------- ---------- ---------- Parse 1 0.01 0.02 0 0 0 0 Execute 1 0.00 0.00 0 0 0 0 Fetch 21 33.04 96.12 346671 347172 0 300 ------- ------ -------- ---------- ---------- ---------- ---------- ---------- total 23 33.06 96.14 346671 347172 0 300
如果另一名用户希望执行完全相同的查询,情况又会如何?用户会话将不得不再次遍历缓冲区缓存中的所有这些行,获得 300 行的最终结果。如果有一种方法能够在第二次和以后的每一次直接获取这 300 行,应该怎么办?只要我们有足够的缓冲区来容纳这些数据,就能每次直接获取这些行。
这就是结果缓存的用处。如图 1 所示,利用结果缓存特性,这 300 行被移至(第 3 步)共享池的结果缓存部分中。随后,在执行相同的查询时,可以在结果缓存中查找结果,而无需遍历 347,000 行数据。这难道不是一个巧妙的特性吗?
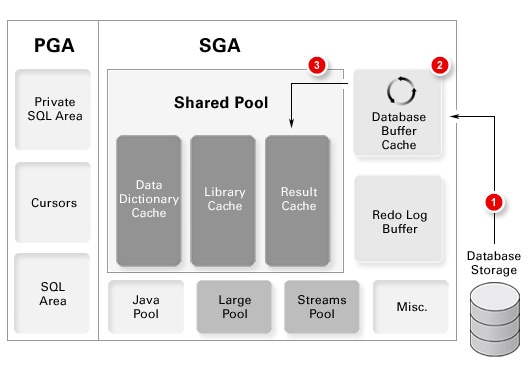
图 1 结果缓存行为
可以在客户端或服务器端对结果缓存进行管理。客户端结果缓存实现需要应用程序使用 Oracle 调用接口 (OCI) 调用。相比之下,服务器端实现就简单得多。就本文的讨论而言,我们将侧重于结果缓存的服务器端实现。
对于服务器端实现,相同的查询可使用 /*+ RESULT CACHE */ 提示执行,也可以将 result_cache_mode 参数设置为 AUTO。将此参数设置为 AUTO 会将所有查询结果移至共享池的结果缓存部分中,这样最终的 300 行将移至共享池的结果缓存部分中以便重用。
在执行带有此提示的查询时,数据库会在共享池的结果缓存部分中查找,确定缓存中是否存在结果。如果确实存在,数据库将检索结果并将数据返回给用户,而不执行查询。
然而,可以由于以下原因而不缓存结果:
初次执行查询。
由于 result_cache_max_result 设定的限制,其他操作需要使用所分配的空间,因而缓存已刷新。
一个数据库管理员执行了 dbms_result_cache.flush 过程,查询必须再次执行。随后,将最终结果集移动并存储到结果缓存中。
NAME TYPE VALUE ------------------------------------ ----------- ---------- client_result_cache_lag big integer 3000 client_result_cache_size big integer 0 result_cache_max_result integer 5 result_cache_max_size big integer 251680K result_cache_mode string MANUAL result_cache_remote_expiration integer 0
client_result_cache_lag 和 client_result_cache_size 参数用于在客户端配置结果缓存。其他参数用于在服务器端配置结果缓存。
服务器上的结果缓存大小由两个参数决定:result_cache_max_result 和 result_cache_max_size。
默认情况下,result_cache_max_size 参数约为 memory_target 参数的 0.25%,或者 shared_pool 参数的 1%。可对此参数进行修改,以控制结果缓存中存储的内容量。result_cache_max_result 参数指定一个结果缓存可占用 result_cache_max_size 的百分比情况。默认值为 5%。
每个结果集在缓存中都是使用 CACHE_ID 标识的,这是一个长度为 90 个字符的字符串。查询的 CACHE_ID 与 V$SQL 中包含的用于标识库缓存中的查询的 SQL_ID 并不匹配。与针对 Oracle 数据库执行的每个 SQL 查询生成的 SQL_ID 不同,CACHE_ID 针对的是共享池的结果缓存部分中存储查询最终结果的一个区域或存储段 (bucket)。
如果上述查询在执行时使用了 /*+ RESULT_CACHE */ 提示,将生成以下计划。分配给结果缓存的名称是 CACHE_ID。
--------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 150 | 4950 | | 126K (1)| 00:25:17 |
| 1 | RESULT CACHE | 8fbjhchhd9zwh7uhn4mv7dhvga | | | | | |
| 2 | HASH GROUP BY | | 150 | 4950 | | 126K (1)| 00:25:17 |
|* 3 | HASH JOIN | | 20M| 649M| 45M| 125K (1)| 00:25:09 |
| 4 | INDEX FAST FULL SCAN| ORDERS_I2 | 2063K| 21M| | 2743 (1)| 00:00:33 |
| 5 | INDEX FAST FULL SCAN| IORDL | 20M| 432M| | 87415 (1)| 00:17:29 |
--------------------------------------------------------------------------------------------------------------
有几个视图用于监视与结果缓存相关的信息。与结果缓存相关的对象可从 V$RESULT_CAHCE_OBJECTS 视图获取。以下查询可帮助验证结果缓存中包含 CACHE_ID 为 8fbjhchhd9zwh7uhn4mv7dhvga 的结果集。
SQL> SELECT ID, TYPE, CREATION_TIMESTAMP, BLOCK_COUNT, COLUMN_COUNT, PIN_COUNT, ROW_COUNT FROM V$RESULT_CACHE_OBJECTS WHERE CACHE_ID='8fbjhchhd9zwh7uhn4mv7dhvga'; ID TYPE CREATION_ BLOCK_COUNT COLUMN_COUNT PIN_COUNT ROW_COUNT ---------- ---------- --------- ----------- ------------ ---------- ---------- 2 Result 19-JAN-10 1 3 0 300
本文的主要目的是讨论 Oracle RAC 环境中的结果缓存行为。因此,让我们来更具体地了解结果缓存,逐步深入讨论其在 Oracle RAC 实现中的行为。对于 Oracle RAC 新手,我们首先从一些背景信息入手。
