分类: 云计算
2018-03-26 05:50:44
上一节讨论了 Health Check 在 Scale Up 中的应用,Health Check 另一个重要的应用场景是 Rolling Update。试想一下下面的情况:
现有一个正常运行的多副本应用,接下来对应用进行更新(比如使用更高版本的 image),Kubernetes 会启动新副本,然后发生了如下事件:
正常情况下新副本需要 10 秒钟完成准备工作,在此之前无法响应业务请求。
但由于人为配置错误,副本始终无法完成准备工作(比如无法连接后端数据库)。
先别继续往下看,现在请花一分钟思考这个问题:如果没有配置 Health Check,会出现怎样的情况?
因为新副本本身没有异常退出,默认的 Health Check 机制会认为容器已经就绪,进而会逐步用新副本替换现有副本,其结果就是:当所有旧副本都被替换后,整个应用将无法处理请求,无法对外提供服务。如果这是发生在重要的生产系统上,后果会非常严重。
如果正确配置了 Health Check,新副本只有通过了 Readiness 探测,才会被添加到 Service;如果没有通过探测,现有副本不会被全部替换,业务仍然正常进行。
下面通过例子来实践 Health Check 在 Rolling Update 中的应用。
用如下配置文件 app.v1.yml 模拟一个 10 副本的应用:
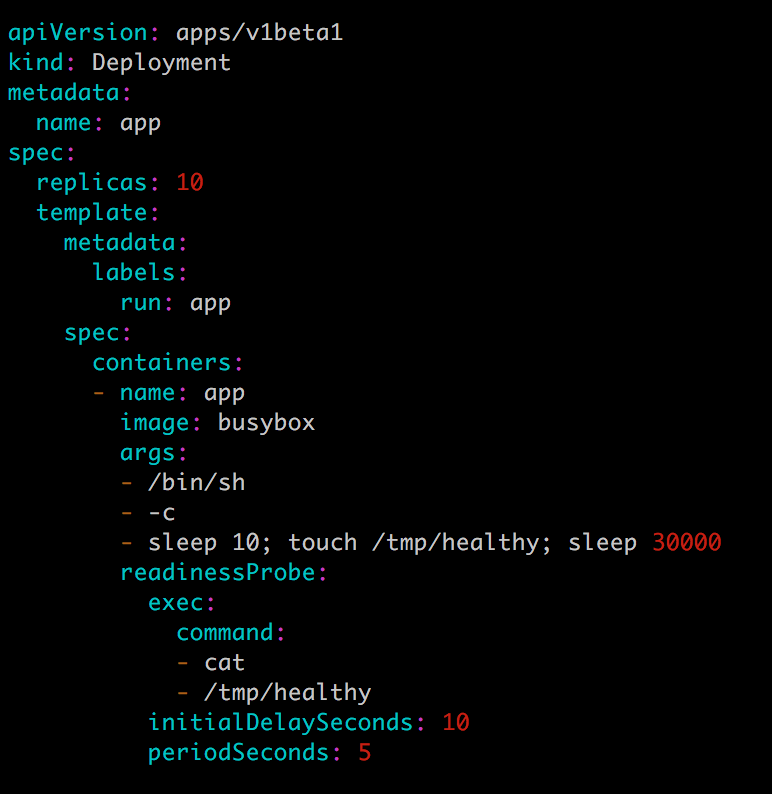
10 秒后副本能够通过 Readiness 探测。
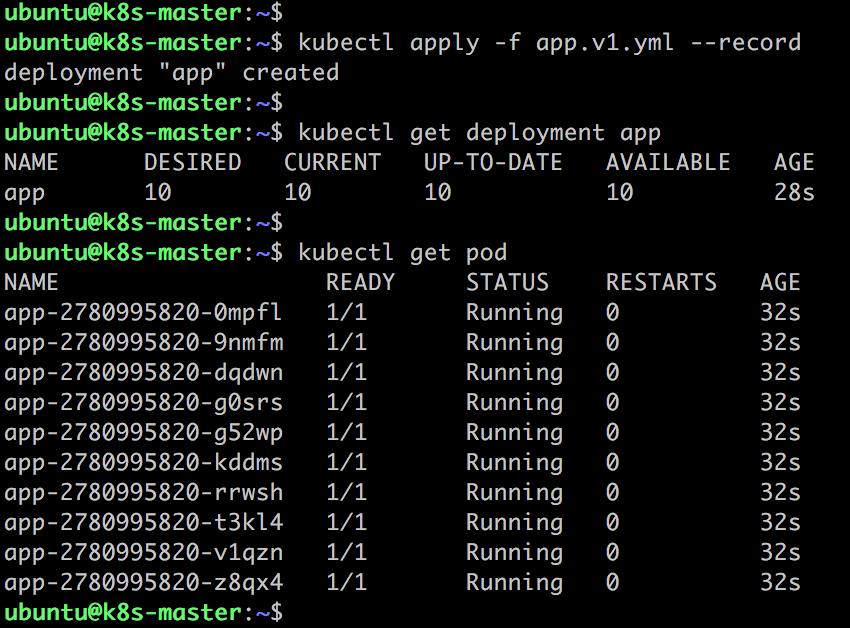
接下来滚动更新应用,配置文件 app.v2.yml 如下:
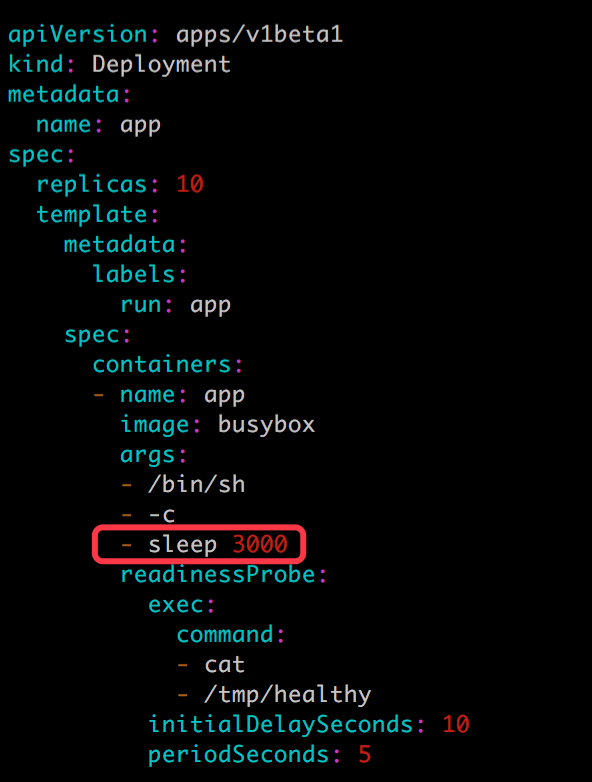
很显然,由于新副本中不存在 /tmp/healthy,是无法通过 Readiness 探测的。验证如下:
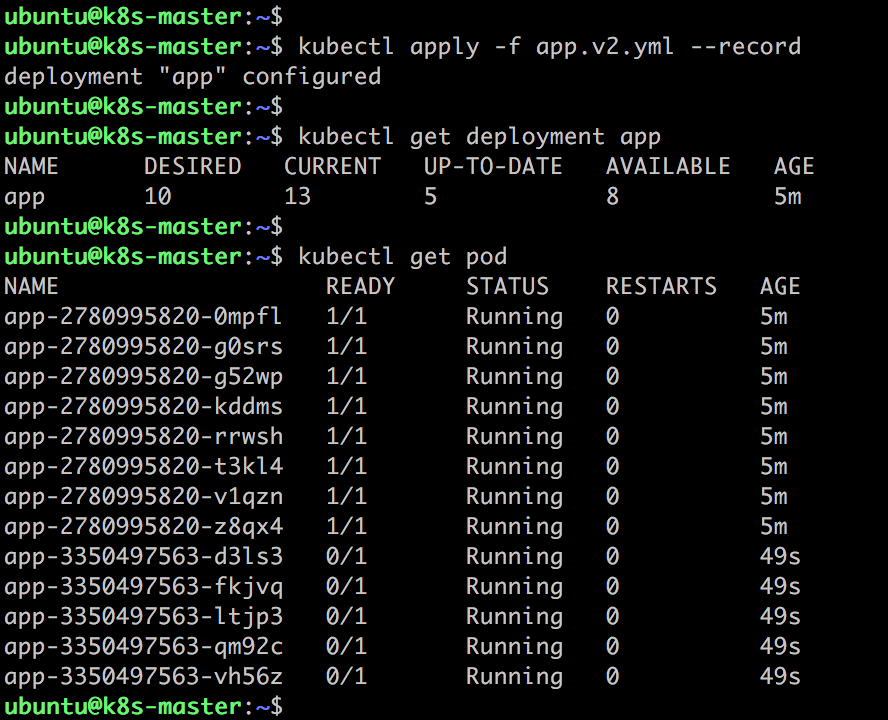
这个截图包含了大量的信息,值得我们详细分析。
先关注 kubectl get pod 输出:
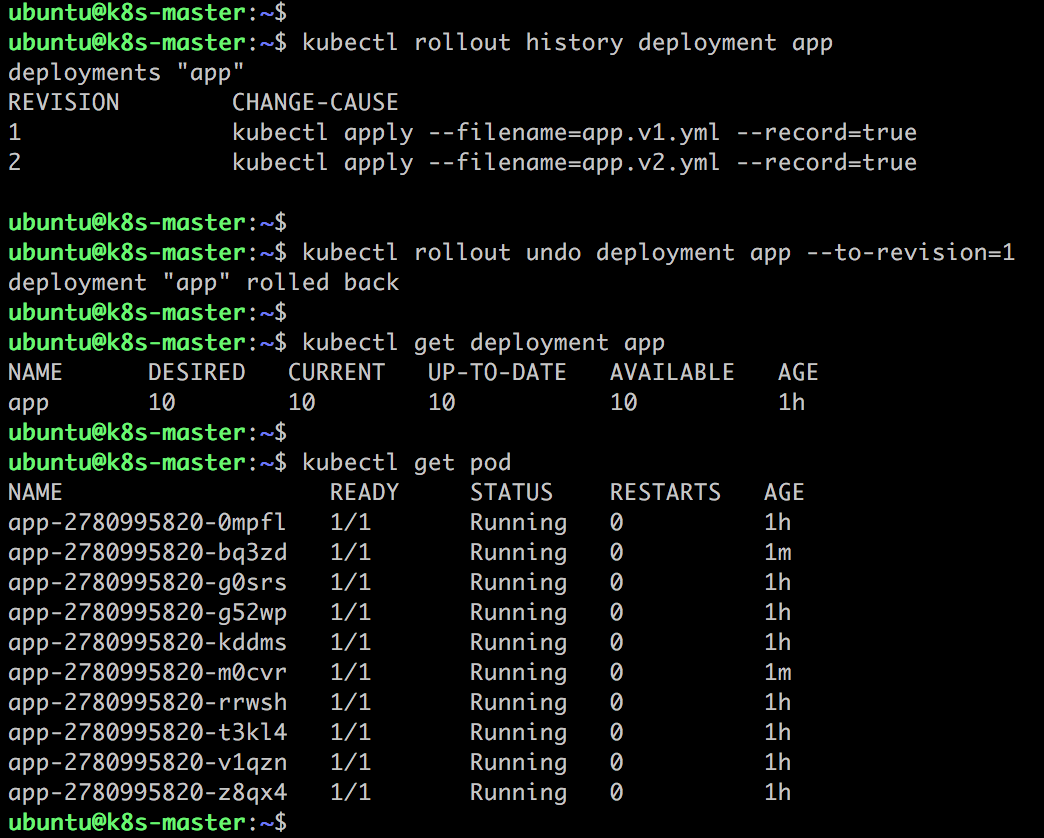
从 Pod 的 AGE 栏可判断,最后 5 个 Pod 是新副本,目前处于 NOT READY 状态。
旧副本从最初 10 个减少到 8 个。
再来看 kubectl get deployment app 的输出:
DESIRED 10 表示期望的状态是 10 个 READY 的副本。
CURRENT 13 表示当前副本的总数:即 8 个旧副本 + 5 个新副本。
UP-TO-DATE 5 表示当前已经完成更新的副本数:即 5 个新副本。
AVAILABLE 8 表示当前处于 READY 状态的副本数:即 8个旧副本。
在我们的设定中,新副本始终都无法通过 Readiness 探测,所以这个状态会一直保持下去。
上面我们模拟了一个滚动更新失败的场景。不过幸运的是:Health Check 帮我们屏蔽了有缺陷的副本,同时保留了大部分旧副本,业务没有因更新失败受到影响。
接下来我们要回答:为什么新创建的副本数是 5 个,同时只销毁了 2 个旧副本?
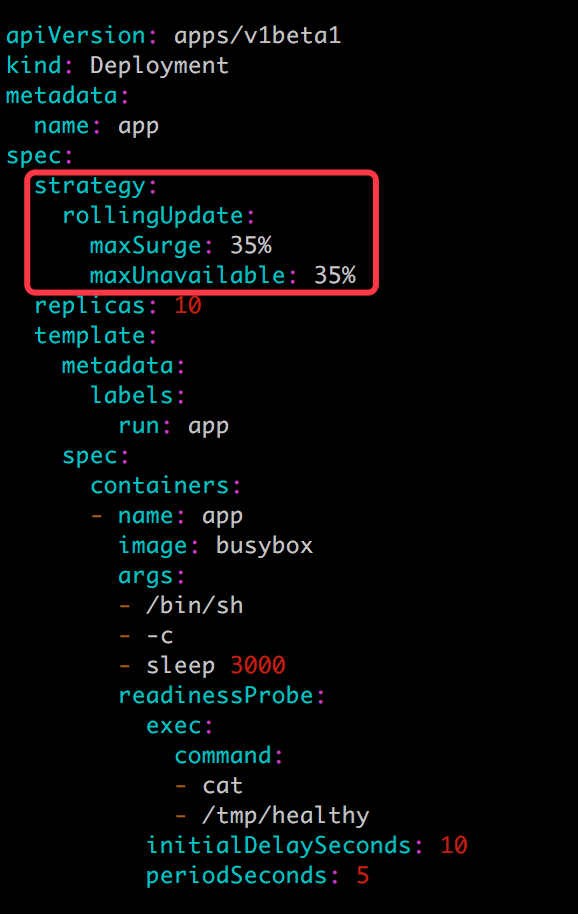
原因是:滚动更新通过参数 maxSurge 和 maxUnavailable 来控制副本替换的数量。
maxSurge
此参数控制滚动更新过程中副本总数的超过 DESIRED 的上限。maxSurge 可以是具体的整数(比如 3),也可以是百分百,向上取整。maxSurge 默认值为 25%。
在上面的例子中,DESIRED 为 10,那么副本总数的最大值为:
roundUp(10 + 10 * 25%) = 13
所以我们看到 CURRENT 就是 13。
maxUnavailable
此参数控制滚动更新过程中,不可用的副本相占 DESIRED 的最大比例。 maxUnavailable 可以是具体的整数(比如 3),也可以是百分百,向下取整。maxUnavailable 默认值为 25%。
在上面的例子中,DESIRED 为 10,那么可用的副本数至少要为:
10 - roundDown(10 * 25%) = 8
所以我们看到 AVAILABLE 就是 8。
maxSurge 值越大,初始创建的新副本数量就越多;maxUnavailable 值越大,初始销毁的旧副本数量就越多。
理想情况下,我们这个案例滚动更新的过程应该是这样的:
首先创建 3 个新副本使副本总数达到 13 个。
然后销毁 2 个旧副本使可用的副本数降到 8 个。
当这 2 个旧副本成功销毁后,可再创建 2 个新副本,使副本总数保持为 13 个。
当新副本通过 Readiness 探测后,会使可用副本数增加,超过 8。
进而可以继续销毁更多的旧副本,使可用副本数回到 8。
旧副本的销毁使副本总数低于 13,这样就允许创建更多的新副本。
这个过程会持续进行,最终所有的旧副本都会被新副本替换,滚动更新完成。
而我们的实际情况是在第 4 步就卡住了,新副本无法通过 Readiness 探测。这个过程可以在 kubectl describe deployment app 的日志部分查看。

如果滚动更新失败,可以通过 kubectl rollout undo 回滚到上一个版本。
如果要定制 maxSurge 和 maxUnavailable,可以如下配置:
本章我们讨论了 Kubernetes 健康检查的两种机制:Liveness 探测和 Readiness 探测,并实践了健康检查在 Scale Up 和 Rolling Update 场景中的应用。
下节我们开始讨论 Kubernetes 如何管理数据。
书籍:
1.《每天5分钟玩转Kubernetes》
2.《每天5分钟玩转Docker容器技术》
3.《每天5分钟玩转OpenStack》
