NCCL源码解析6——channel setup
——lvyilong316
继续NCCL源码分析。上一篇文章介绍了机内和机间的channel搜索情况。所谓channel只是描述了一些列可以通信rank的关系,channel搜索结束后只是确定了这些关系,并记录在:comm->channels[c].ring.prev(当前rank在channel c的前节点), comm->rank(当前rank), comm->channels[c].ring.next(当前rank在channel c的后节点)。但这几个rank并没有真的建立通信连接(比如RDMA连接),因此还无法通信,所以本节就看下channel中的rank是如何进行setup的。
继续看initTransportsRank函数,接下来调用ncclTopoComputeP2pChannels获取P2P Channel的数量。所谓P2P Channel就是只两个rank之间的点对点通信channel。
-
ncclResult_t ncclTopoComputeP2pChannels(struct ncclComm* comm) {
-
/* here we already honor comm->max/minCTAs for p2pnChannels. */
-
if (comm->sharedRes->owner != comm) {
-
comm->p2pnChannels = std::min(comm->nChannels, (int)ncclParamMaxP2pNChannels());
-
comm->p2pnChannels = std::min(std::max(comm->p2pnChannels, (int)ncclParamMinP2pNChannels()), comm->sharedRes->tpP2pNChannels);
-
} else {
-
comm->p2pnChannels = std::min(comm->nChannels, (int)ncclParamMaxP2pNChannels());
-
comm->p2pnChannels = std::max(comm->p2pnChannels, (int)ncclParamMinP2pNChannels());
-
}
-
-
int minChannels = comm->p2pnChannels;
-
// We need to loop through all local GPUs to have a global picture
-
for (int g=0; g<comm->topo->nodes[GPU].count; g++) {
-
for (int r=0; r<comm->nRanks; r++) {
-
int nChannels;
-
NCCLCHECK(ncclTopoGetNchannels(comm, g, r, &nChannels));
-
if (nChannels >= 0) minChannels = std::min(minChannels, nChannels);
-
}
-
}
-
-
// Make nChannelsPerPeer and nChannels powers of 2. This is relied on when
-
// mapping p2p peers to channels.
-
comm->p2pnChannelsPerPeer = pow2Up(minChannels);
-
comm->p2pnChannels = pow2Up(comm->p2pnChannels);
-
-
comm->p2pnChannels = std::min(comm->p2pnChannels, pow2Down(ncclDevMaxChannelsForArgsBytes(ncclParamWorkArgsBytes())));
-
comm->p2pnChannelsPerPeer = std::min(comm->p2pnChannelsPerPeer, comm->p2pnChannels);
-
-
// Init channels that weren't used so far
-
for (int c=comm->nChannels; c<comm->p2pnChannels; c++) NCCLCHECK(initChannel(comm, c));
-
-
return ncclSuccess;
-
}
之前在建立ringGraph的时候有搜索出一系列的环,并根据这些环建立了channel,假设现在一共有nChannels个channel,而p2p需要p2pnChannels个channel,那么如果p2pnChannels大于nChannles,会再创建p2pnChannels - nChannels个channel,并进行初始化,其他的复用;否则直接复用即可。对于每个send/recv操作,会使用p2pnChannelsPerPeer个channel并行发送/接收。
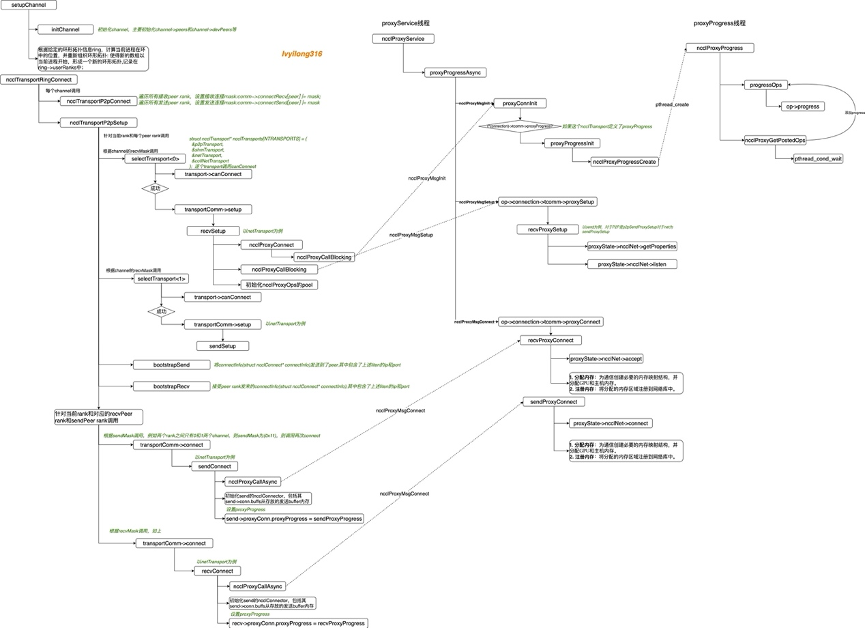
接着initTransportsRank调用ncclProxyCreate创建proxyService线程。
-
// Launch proxy service thread, after this, the proxy calls can be used.
-
if (parent && parent->config.splitShare) {
-
comm->proxyState = parent->sharedRes->proxyState;
-
ncclAtomicRefCountIncrement(&parent->sharedRes->proxyState->refCount);
-
} else {
-
NCCLCHECKGOTO(ncclProxyCreate(comm), ret, fail);
-
}
具体线程处理函数为ncclProxyService,当然如果支持UDS的话还会创建对应的UDS线程。
-
ncclResult_t ncclProxyCreate(struct ncclComm* comm) {
-
/* proxyState is shared among parent comm and split comms. comm->proxyState->thread is
-
* pthread_join()'d by commFree() in init.cc when the refCount reduces down to 0. */
-
//……
-
pthread_create(&comm->proxyState->thread, NULL, ncclProxyService, comm->proxyState);
-
ncclSetThreadName(comm->proxyState->thread, "NCCL Service %2d", comm->cudaDev);
-
-
// UDS support
-
INFO(NCCL_PROXY, "UDS: Creating service thread comm %p rank %d", comm, comm->rank);
-
pthread_create(&comm->proxyState->threadUDS, NULL, ncclProxyServiceUDS, comm->proxyState);
-
ncclSetThreadName(comm->proxyState->threadUDS, "NCCL UDS Service %2d", comm->cudaDev);
-
}
-
return ncclSuccess;
-
}
而proxy的监听端口和socket信息是在我们第二章讲bootstrap网络的时候创建的,并采用 bootstrapAllGather 方法获取了所有进程(rank)的 proxy 监听端口和所有进程的 UDS 信息。
在NCCL中,intra-node场景,GPU与GPU之间建立P2P transport,以及inter-node场景,通过NET建立NET transport的时候,都需要proxy线程的参与,其实总共有两个proxy线程,一个叫做proxyService线程,是每个NODE中每个GPU对应的一个,主要维护连接建立, 用于transport的setup和connect阶段。另一个叫做proxyProgress线程,也是每个NODE中每个GPU对应的一个,主要在inter-node通信过程中,处理kernel和IB之间的数据交互。而我们这里提到的就是proxyService线程。
接下来,构建 p2pSchedule 数据结构,包含每个round中点对点(P2P)通信的发送rank和接收rank。通过这种方式,可以实现全量 rank 间的通信。
-
do { // Build p2p schedule
-
int node = comm->node;
-
int nNodes = comm->nNodes;
-
int nRanks = comm->nRanks;
-
int local = comm->localRank;
-
int nLocals = comm->maxLocalRanks;
-
struct ncclNodeRanks* nodeRanks = comm->nodeRanks;
-
bool flat = false;
-
for (int node = 0; node < nNodes; node++) {
-
if (nodeRanks[node].localRanks != nLocals) {
-
flat = true;
-
nNodes = 1; node = 0;
-
nLocals = nRanks; local = rank;
-
break;
-
}
-
}
-
int nNodesPow2 = pow2Up(nNodes);
-
int nLocalsPow2 = pow2Up(nLocals);
-
comm->p2pSchedule = ncclMemoryStackAlloc<ncclComm::P2pSchedulePair>(&comm->memPermanent, nRanks);
-
comm->planner.peers = ncclMemoryStackAlloc<ncclKernelPlanner::Peer>(&comm->memPermanent, nRanks);
-
uint32_t nodeRound = 0;
-
uint32_t nodeDelta = 0;
-
int round = 0;
-
// When enumerating peer deltas we use the quadratic formula (x*x+x)/2 mod N.
-
// Since that formula only produces valid permutations when N is a pow of 2,
-
// we let N = pow2Up(n) and filter out results greater-eq to n.
-
// Example sequence for 16 ranks: 0, 1, 3, 6, 10, 15, 5, 12, 4, 13, 7, 2, 14, 11, 9, 8
-
do {
-
if (nodeDelta < nNodes) { // Filter nonsensical node deltas
-
int sendNode = (node + nodeDelta) % nNodes;
-
int recvNode = (node - nodeDelta + nNodes) % nNodes;
-
uint32_t localRound = 0;
-
uint32_t localDelta = 0;
-
do {
-
if (localDelta < nLocals) { // Filter nonsensical node-local deltas
-
int sendLocal = (local + localDelta) % nLocals;
-
int recvLocal = (local - localDelta + nLocals) % nLocals;
-
comm->p2pSchedule[round].sendRank = flat ? sendLocal : nodeRanks[sendNode].localRankToRank[sendLocal];
-
comm->p2pSchedule[round].recvRank = flat ? recvLocal : nodeRanks[recvNode].localRankToRank[recvLocal];
-
round += 1;
-
}
-
localRound += 1;
-
localDelta = (localDelta + localRound) & (nLocalsPow2 - 1); // Quadratic update
-
} while (localRound != nLocalsPow2);
-
}
-
nodeRound += 1;
-
nodeDelta = (nodeDelta + nodeRound) & (nNodesPow2 - 1); // Quadratic update
-
} while (nodeRound != nNodesPow2);
-
-
if (round != nRanks) {
-
WARN("P2p schedule creation has bugs.");
-
ret = ncclInternalError;
-
goto fail;
-
}
-
} while (0);
随后,调用setupChannel设置通信 channel。该函数主要计算当前进程在ring中的位置和rank=0进程在ring中位置的距离,并赋值给ring->index。此外,setupChannel重新组织ring中的所有 ranks,使得本进程的 rank 作为ring的起点,并把重组后的ring赋值给ring->userRanks。接着,调用ncclTransportRingConnect等连接对应的 channel。关于ncclTransportRingConnect后面再详细展开。
-
comm->runtimeConn = comm->cuMemSupport && ncclParamRuntimeConnect();
-
if (comm->runtimeConn) {
-
for (int c=0; c<comm->nChannels; c++) {
-
NCCLCHECKGOTO(setupChannel(comm, c, rank, nranks, rings+c*nranks), ret, fail);
-
}
-
// Setup NVLS
-
NCCLCHECKGOTO(ncclNvlsSetup(comm, parent), ret, fail);
-
// Check if we can setup CollNet
-
if (comm->collNetSupport > 0) ncclCollNetSetup(comm, parent, graphs);
-
} else {
-
for (int c=0; c<comm->nChannels; c++) {
-
NCCLCHECKGOTO(setupChannel(comm, c, rank, nranks, rings+c*nranks), ret, fail);
-
}
-
NCCLCHECKGOTO(ncclTransportRingConnect(comm), ret, fail);
-
-
// Connect Trees
-
NCCLCHECKGOTO(ncclTransportTreeConnect(comm), ret, fail);
-
-
// Setup NVLS
-
NCCLCHECKGOTO(ncclNvlsSetup(comm, parent), ret, fail);
-
NCCLCHECKGOTO(ncclNvlsBufferSetup(comm), ret, fail);
-
-
// And NVLS trees if needed
-
NCCLCHECKGOTO(ncclNvlsTreeConnect(comm), ret, fail);
-
-
// Check if we can setup CollNet
-
if (comm->collNetSupport > 0) {
-
ncclCollNetSetup(comm, parent, graphs);
-
NCCLCHECKGOTO(ncclCollNetChainBufferSetup(comm), ret, fail);
-
NCCLCHECKGOTO(ncclCollNetDirectBufferSetup(comm), ret, fail);
-
}
-
-
// Connect to local net proxy
-
tpProxyRank = comm->topParentRanks[comm->rank];
-
NCCLCHECKGOTO(ncclProxyConnect(comm, TRANSPORT_NET, 1, tpProxyRank, &proxyConn), ret, fail);
-
NCCLCHECKGOTO(ncclProxyCallBlocking(comm, &proxyConn, ncclProxyMsgSharedInit, &comm->p2pnChannels, sizeof(int), NULL, 0), ret, fail);
-
-
// Then to remote ones when using PXN
-
if (ncclPxnDisable(comm) == 0) {
-
int nranks;
-
NCCLCHECKGOTO(ncclTopoGetPxnRanks(comm, &pxnPeers, &nranks), ret, fail);
-
for (int r=0; r<nranks; r++) {
-
tpProxyRank = comm->topParentRanks[pxnPeers[r]];
-
NCCLCHECKGOTO(ncclProxyConnect(comm, TRANSPORT_NET, 1, tpProxyRank, &proxyConn), ret, fail);
-
NCCLCHECKGOTO(ncclProxyCallBlocking(comm, &proxyConn, ncclProxyMsgSharedInit, &comm->p2pnChannels, sizeof(int), NULL, 0), ret, fail);
-
}
-
}
-
-
if (ncclParamNvbPreconnect()) {
-
// Connect p2p when using NVB path
-
int nvbNpeers;
-
NCCLCHECKGOTO(ncclTopoGetNvbGpus(comm->topo, comm->rank, &nvbNpeers, &nvbPeers), ret, fail);
-
for (int r=0; r<nvbNpeers; r++) {
-
int peer = nvbPeers[r];
-
int sendRound=0, recvRound=0;
-
while (comm->p2pSchedule[sendRound].sendRank != peer) sendRound++;
-
while (comm->p2pSchedule[recvRound].recvRank != peer) recvRound++;
-
uint8_t sendBase = ncclP2pChannelBaseForRound(comm, sendRound);
-
uint8_t recvBase = ncclP2pChannelBaseForRound(comm, recvRound);
-
for (int c=0; c<comm->p2pnChannelsPerPeer; c++) {
-
int channelId;
-
channelId = ncclP2pChannelForPart(comm->p2pnChannels, sendBase, c);
-
if (comm->channels[channelId].peers[peer]->send[1].connected == 0) {
-
comm->connectSend[peer] |= (1UL<<channelId);
-
}
-
channelId = ncclP2pChannelForPart(comm->p2pnChannels, recvBase, c);
-
if (comm->channels[channelId].peers[peer]->recv[1].connected == 0) {
-
comm->connectRecv[peer] |= (1UL<<channelId);
-
}
-
}
-
}
-
-
NCCLCHECKGOTO(ncclTransportP2pSetup(comm, NULL, 1), ret, fail);
-
}
-
}
-
-
TRACE(NCCL_INIT, "rank %d nranks %d - CONNECTED %d RINGS AND TREES", rank, nranks, comm->nChannels);
然后,做{BANNED}最佳后的初始化操作。
-
// Compute time models for algorithm and protocol combinations
-
NCCLCHECKGOTO(ncclTopoTuneModel(comm, comm->minCompCap, comm->maxCompCap, graphs), ret, fail);
-
-
INFO(NCCL_INIT, "%d coll channels, %d collnet channels, %d nvls channels, %d p2p channels, %d p2p channels per peer", comm->nChannels, comm->nChannels, comm->nvlsChannels, comm->p2pnChannels, comm->p2pnChannelsPerPeer);
-
-
if (comm->intraRank == 0) { // Load ncclParamLaunchMode
-
const char* str = ncclGetEnv("NCCL_LAUNCH_MODE");
-
enum ncclLaunchMode mode, modeOld;
-
if (str && strcasecmp(str, "GROUP") == 0) {
-
mode = ncclLaunchModeGroup;
-
} else {
-
mode = ncclLaunchModeParallel;
-
}
-
// In theory we could be racing with other communicators not associated with
-
// this one if the user is connecting to multiple ncclUniqueId's concurrently.
-
modeOld = __atomic_exchange_n(&ncclParamLaunchMode, mode, __ATOMIC_RELAXED);
-
if (modeOld == ncclLaunchModeInvalid && str && str[0]!='\0') {
-
INFO(NCCL_ENV, "NCCL_LAUNCH_MODE set by environment to %s", mode == ncclLaunchModeParallel ? "PARALLEL" : "GROUP");
-
}
-
}
-
-
// Call devCommSetup before the last barrier, making sure we don't have a thread running in front and starting to
-
// launch NCCL kernels before all cuda mem allocation is complete. That could cause a deadlock.
-
NCCLCHECKGOTO(devCommSetup(comm), ret, fail);
-
timers[TIMER_INIT_CONNECT] = clockNano() - timers[TIMER_INIT_CONNECT];
-
-
/* Local intra-node barrier */
-
NCCLCHECKGOTO(bootstrapIntraNodeBarrier(comm->bootstrap, comm->localRankToRank, comm->localRank, comm->localRanks, comm->localRankToRank[0]), ret, fail);
-
-
// We should have allocated all buffers, collective fifos, ... we can
-
// restore the affinity.
-
TRACE(NCCL_INIT, "rank %d nranks %d - DONE", rank, nranks);
到此为止initTransportsRank函数终于结束了。再介绍setupChannel和ncclTransportRingConnect前我们还是要把前面提到的NCCL的两种proxy线程再展开澄清一下。
NCCL为每个Rank创建一个proxyService线程,线程处理函数为:ncclProxyService,每个Rank上的线程名字分别为:NCCL Service 0,NCCL Service 1,NCCL Service 2,NCCL Service 3(4 GPU)。NCCL为每个Rank创建一个proxyProgress线程,线程处理函数为:ncclProxyProgress,线程名字一样,都为:NCCL Progress 4(4 GPU)
下面我们看ncclTransportRingConnect的逻辑,如下所示。
-
ncclResult_t ncclTransportRingConnect(struct ncclComm* comm) {
-
ncclResult_t ret = ncclSuccess;
-
if (comm && comm->nRanks > 1) {
-
for (int c = 0; c < comm->nChannels; c++) {
-
struct ncclChannel* channel = comm->channels + c;
-
NCCLCHECKGOTO(ncclTransportP2pConnect(comm, c, 1, &channel->ring.prev, 1, &channel->ring.next, 0), ret, fail);
-
}
-
NCCLCHECKGOTO(ncclTransportP2pSetup(comm, &comm->graphs[NCCL_ALGO_RING], 0), ret, fail);
-
INFO(NCCL_INIT, "Connected all rings");
-
}
-
exit:
-
return ret;
-
fail:
-
goto exit;
-
}
其中主要就是调用ncclTransportP2pConnect和ncclTransportP2pSetup,而ncclTransportP2pConnect也不是真的把P2P channel的两个rank之间连接起来,而是根据当前rank在每个channel中的prev和next,设置对应rank的mask,后续真正建立transport时根据这里的mask决定哪些rank之间需要创建,以及需要创建多少。
-
ncclResult_t ncclTransportP2pConnect(struct ncclComm* comm, int channelId, int nrecv, int* peerRecv, int nsend, int* peerSend, int connIndex) {
-
TRACE(NCCL_INIT, "nsend %d nrecv %d", nsend, nrecv);
-
struct ncclChannel* channel = &comm->channels[channelId];
-
uint64_t mask = 1UL << channel->id;
-
for (int i=0; i<nrecv; i++) {
-
int peer = peerRecv[i];
-
if (peer == -1 || peer >= comm->nRanks || peer == comm->rank || channel->peers[peer]->recv[connIndex].connected) continue;
-
comm->connectRecv[peer] |= mask;
-
}
-
for (int i=0; i<nsend; i++) {
-
int peer = peerSend[i];
-
if (peer == -1 || peer >= comm->nRanks || peer == comm->rank || channel->peers[peer]->send[connIndex].connected) continue;
-
comm->connectSend[peer] |= mask;
-
}
-
return ncclSuccess;
-
}
{BANNED}最佳关键的还是ncclTransportP2pSetup这个函数,这个函数是创建transport的核心。
-
ncclResult_t ncclTransportP2pSetup(struct ncclComm* comm, struct ncclTopoGraph* graph, int connIndex, int* highestTransportType/*=NULL*/) {
-
// Stream used during transport setup; need for P2P pre-connect + CUDA Graph
-
ncclResult_t ret = ncclSuccess;
-
int highestType = TRANSPORT_UNDEFINED; // track highest transport type
-
struct ncclConnect** data; // Store intermediate send/recvData structs for connect
-
struct ncclConnect** recvData; // Points to entries inside data for given recv connection within a channel
-
struct ncclConnect** sendData; // Points to entries inside data for given send connection within a channel
-
int done = 0;
-
-
int maxPeers = ncclParamConnectRoundMaxPeers();
-
NCCLCHECK(ncclCalloc(&data, maxPeers));
-
NCCLCHECK(ncclCalloc(&recvData, maxPeers));
-
NCCLCHECK(ncclCalloc(&sendData, maxPeers));
-
-
struct timeval timeStart, timeLast;
-
gettimeofday(&timeStart, NULL);
-
timeLast = timeStart; // struct copy
-
bool timeReported = false;
-
-
NCCLCHECKGOTO(ncclStrongStreamAcquireUncaptured(&comm->sharedRes->hostStream), ret, fail);
-
// First time initialization
-
for (int i=1; i<comm->nRanks; i++) {
-
int bootstrapTag = (i<<8) + (graph ? graph->id+1 : 0);
-
int recvPeer = (comm->rank - i + comm->nRanks) % comm->nRanks;
-
int sendPeer = (comm->rank + i) % comm->nRanks;
-
uint64_t recvMask = comm->connectRecv[recvPeer];
-
uint64_t sendMask = comm->connectSend[sendPeer];
-
-
/*
-
data[i] 包含了与特定对等体的所有发送和接收连接的相关信息。
-
这些信息根据与该对等体连接的发送通道(sendChannels)和接收通道(recvChannels)的数量进行组织。
-
数组的前 N 个条目存储接收连接的信息(recvData),接下来的 M 个条目存储发送连接的信息(sendData)。
-
每个 data 条目中的总连接数或特定的发送/接收连接数可能不同。
-
*/
-
int p = i-(done+1);
-
if (recvMask || sendMask) NCCLCHECK(ncclCalloc(data+p, 2*MAXCHANNELS));
-
recvData[p] = data[p];
-
int sendChannels = 0, recvChannels = 0;
-
int type;
-
TIME_START(0);
-
for (int c=0; c<MAXCHANNELS; c++) {
-
if (recvMask & (1UL<<c)) {
-
NCCLCHECKGOTO(selectTransport<0>(comm, graph, recvData[p]+recvChannels++, c, recvPeer, connIndex, &type), ret, fail);
-
if (type > highestType) highestType = type;
-
}
-
}
-
TIME_STOP(0);
-
TIME_START(1);
-
sendData[p] = recvData[p]+recvChannels;
-
for (int c=0; c<MAXCHANNELS; c++) {
-
if (sendMask & (1UL<<c)) {
-
NCCLCHECKGOTO(selectTransport<1>(comm, graph, sendData[p]+sendChannels++, c, sendPeer, connIndex, &type), ret, fail);
-
if (type > highestType) highestType = type;
-
}
-
}
-
TIME_STOP(1);
首先,我们知道ncclTransportP2pSetup这个函数首先就是在一个循环中对每个channel调用的,然后ncclTransportP2pSetup里面开始也有一个for循环,遍历每个rank的前后相邻的两个rank,根据之前设置的channel mask记录的什么情况下创建send transport以及什么情况下创建recv transport,创建几个transport,进行transport的创建。
接下来我们注意到会调用一个模版函数selectTransport,如下,根据代码可知type为0表示recv,type为1比表示send。
-
template <int type>
-
static ncclResult_t selectTransport(struct ncclComm* comm, struct ncclTopoGraph* graph, struct ncclConnect* connect, int channelId, int peer, int connIndex, int* transportType) {
-
struct ncclPeerInfo* myInfo = comm->peerInfo+comm->rank;
-
struct ncclPeerInfo* peerInfo = comm->peerInfo+peer;
-
struct ncclConnector* connector = (type == 1) ? comm->channels[channelId].peers[peer]->send + connIndex :
-
comm->channels[channelId].peers[peer]->recv + connIndex;
-
for (int t=0; t<NTRANSPORTS; t++) {
-
struct ncclTransport *transport = ncclTransports[t];
-
struct ncclTransportComm* transportComm = type == 1 ? &transport->send : &transport->recv;
-
int ret = 0;
-
NCCLCHECK(transport->canConnect(&ret, comm->topo, graph, myInfo, peerInfo));
-
if (ret) {
-
connector->transportComm = transportComm;
-
NCCLCHECK(transportComm->setup(comm, graph, myInfo, peerInfo, connect, connector, channelId, connIndex));
-
if (transportType) *transportType = t;
-
return ncclSuccess;
-
}
-
}
-
WARN("No transport found for rank %d[%lx] -> rank %d[%lx]", myInfo->rank, myInfo->busId, peerInfo->rank, peerInfo->busId);
-
return ncclSystemError;
-
}
然后selectTransport会遍历NCCL库中所有的transport。我们当前版本(v2.22.3-1)定义了以下四种transport。我们后面主要以netTransport为例进行分析。
-
struct ncclTransport* ncclTransports[NTRANSPORTS] = {
-
&p2pTransport,
-
&shmTransport,
-
&netTransport,
-
&collNetTransport
-
};
首先尝试便利每种transport的canConnect,如果成功则使用这个transport的setup函数进行transport的设置。所以优先级也是按照定义顺序决定的。例如机内intra的rank之前如果可以创建P2Ptransport,则不会去创建netTransport。
netTransport定义如下:
-
struct ncclTransport netTransport = {
-
"NET",
-
canConnect,
-
{ sendSetup, sendConnect, sendFree, proxySharedInit, sendProxySetup, sendProxyConnect, sendProxyFree, sendProxyProgress, NULL },
-
{ recvSetup, recvConnect, recvFree, proxySharedInit, recvProxySetup, recvProxyConnect, recvProxyFree, recvProxyProgress, NULL }
-
};
而transport的setup函数主要就是和自己的proxyService线程通信,通过proxyService线程为创建用于传送数据的transport通道做时代的准备,以netTransport为例就是sendSetup和recvSetup,sendSetup和recvSetup具体就不再展开,其中会通过ncclProxyConnect连接proxyService,并调用ncclProxyCallBlocking向proxyService发送对于命令,如ncclProxyMsgInit,ncclProxyMsgSetup等,而proxyService收到命令后就会执行相应的函数。
如proxyService在收到ncclProxyMsgInit后会调用proxyConnInit函数。这个函数会判断当前transport如果定义了proxyProgress函数,则调用proxyProgressInit创建proxyProgress线程,proxyProgress主要是在inter-node通信过程中,处理kernel和IB之间的数据交互用的。后面章节再具体展开。
-
static ncclResult_t proxyConnInit(struct ncclProxyLocalPeer* peer, struct ncclProxyConnectionPool* connectionPool, struct ncclProxyState* proxyState, ncclProxyInitReq* req, ncclProxyInitResp* resp, struct ncclProxyConnection** connection) {
-
//...
-
(*connection)->tcomm = (*connection)->send ? &ncclTransports[(*connection)->transport]->send : &ncclTransports[(*connection)->transport]->recv;
-
// If we need proxy progress, let's allocate ops and start the thread
-
if ((*connection)->tcomm->proxyProgress) {
-
NCCLCHECK(proxyProgressInit(proxyState));
-
struct ncclProxyProgressState* state = &proxyState->progressState;
-
strncpy(resp->devShmPath, state->opsPoolShmSuffix, sizeof(resp->devShmPath));
-
}
-
//...
-
}
回到ncclTransportP2pSetup函数,如下逻辑,前面setup完成必要的transport设置,如内存注册等,后面在收发两端就开始调用transport的connect函数。
-
if (i-done == maxPeers || i == comm->nRanks-1) {
-
// Loop until all channels with all ranks have been connected
-
bool allChannelsConnected;
-
allChannelsConnected = false;
-
while (!allChannelsConnected) {
-
allChannelsConnected = true;
-
for (int j=done+1; j<=i; j++) {
-
int recvPeer = (comm->rank - j + comm->nRanks) % comm->nRanks;
-
int sendPeer = (comm->rank + j) % comm->nRanks;
-
uint64_t recvMask = comm->connectRecv[recvPeer];
-
uint64_t sendMask = comm->connectSend[sendPeer];
-
-
int p = j-(done+1);
-
int sendDataOffset = 0;
-
int recvDataOffset = 0;
-
for (int c=0; c<MAXCHANNELS; c++) {
-
TIME_START(3);
-
if (sendMask & (1UL<<c)) {
-
struct ncclConnector* conn = comm->channels[c].peers[sendPeer]->send + connIndex;
-
// This connector hasn't completed connection yet
-
if (conn->connected == 0) {
-
NCCLCHECKGOTO(conn->transportComm->connect(comm, sendData[p] + sendDataOffset++, 1, comm->rank, conn), ret, fail);
-
if (ret == ncclSuccess) {
-
conn->connected = 1;
-
/* comm->channels[c].devPeers[sendPeer]->send[connIndex] is a device memory access. */
-
CUDACHECKGOTO(cudaMemcpyAsync(&comm->channels[c].devPeersHostPtr[sendPeer]->send[connIndex], &conn->conn, sizeof(struct ncclConnInfo), cudaMemcpyHostToDevice, comm->sharedRes->hostStream.cudaStream), ret, fail);
-
} else if (ret == ncclInProgress) {
-
allChannelsConnected = false;
-
}
-
}
-
}
-
TIME_STOP(3);
-
-
// Start with recv channels
-
TIME_START(4);
-
if (recvMask & (1UL<<c)) {
-
struct ncclConnector* conn = comm->channels[c].peers[recvPeer]->recv + connIndex;
-
// This connector hasn't completed connection yet
-
if (conn->connected == 0) {
-
NCCLCHECKGOTO(conn->transportComm->connect(comm, recvData[p] + recvDataOffset++, 1, comm->rank, conn), ret, fail);
-
if (ret == ncclSuccess) {
-
conn->connected = 1;
-
/* comm->channels[c].devPeers[recvPeer]->recv[connIndex] is a device memory access. */
-
CUDACHECKGOTO(cudaMemcpyAsync(&comm->channels[c].devPeersHostPtr[recvPeer]->recv[connIndex], &conn->conn, sizeof(struct ncclConnInfo), cudaMemcpyHostToDevice, comm->sharedRes->hostStream.cudaStream), ret, fail);
-
} else if (ret == ncclInProgress) {
-
allChannelsConnected = false;
-
}
-
}
-
}
-
TIME_STOP(4);
-
}
-
if (sendMask || recvMask) {
-
free(data[p]);
-
data[p] = NULL;
-
}
-
}
以上调用逻辑实际一个rank的多个线程,为了方便理解,画了一个调用关系图,具体如下所示: