全部博文(354)
分类: 嵌入式
2010-06-22 16:00:19
仔细分析 单片机操作系统 RTX51 的原理,将其移植到单片机实验平台上,并要求编写一个简短的程序来验 证其运行的正确性(比如,编写两个具有显示不同内容的任务)。
注释:由于英文原文会比较好,所以我没有翻译过来(不过也写了部分的翻 译),直接提取出来一些英文,总结在一起。
( Task Management )
( Classes of Tasks )
n Contain especially short responses and interrupt disable times.
n Contain a separate register bank and a separate stack area (register banks 1, 2 and 3).(Figure 1)
n Contain the highest task priority (priority 3) and can therefore interrupt standard tasks.
n All contain the same priority and can therefore not be mutually interrupted.
n Can be interrupted by C51 interrupt functions.
n A maximum of three fast tasks can be active in the system.
n Require somewhat more time for the task switching compared to fast tasks.
n Share a common register bank and a common stack area (register bank 0).
n The current contents of registers and stack are stored in the external (XDATA) memory during a task change.
n Can be interrupted by fast tasks.
n Can interrupt themselves mutually.
n Can be interrupt by C51 interrupt functions.
n A maximum 16
standard tasks can be active in the system.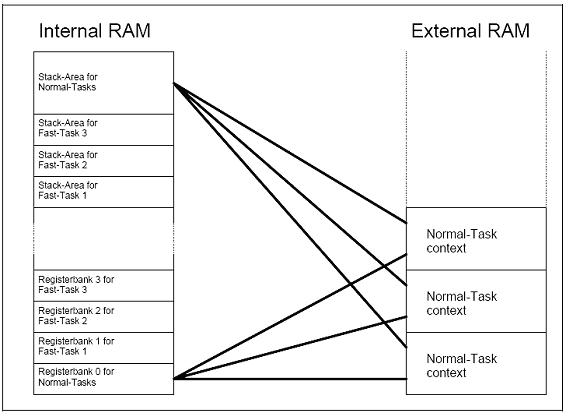
Figure 3: Task Classes
and Memory Allocation
每一
个标准进程都包含一个设备上下文在扩展内存(XDATA)中。在标准进程执行进程切换的时候,会把
它自己的Register和Stack存储
到相应的设备上下文中(在扩展内存中的一个区域)。之后,Register和Statck又从设备上下文中重新载入,继续执行。(交换技术)
相比而
言,快速进程则不用这么麻烦,因为它们有各自独立的Register和Stack,所以只要激活相应的Register(修改PSW)和指向Stack的指针(Mov SP,#XX)即可。
(Task states)
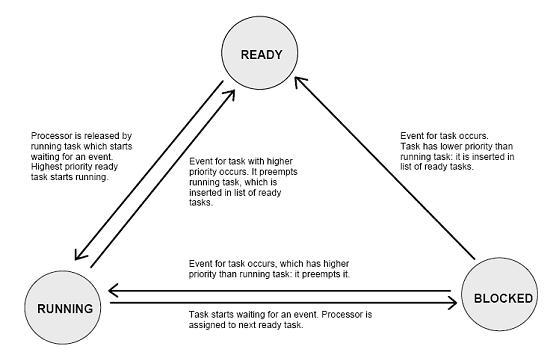
1. READY All tasks which can run are READY. One of these tasks is the RUNNING (ACTIVE)task.
2. RUNNING (ACTIVE) Task which is currently being executed bythe processor. Only one task (maximum) can be in this state at a time.
3. BLOCKED (WAITING) Task waits for an event.
4. SLEEPING All tasks which were not
started or which have terminated themselves are in this state.
(Task switch)
The RTX-51 system section which the processors assigns to the individual tasks is referred to as the scheduler (also dispatcher).
The RTX_51
scheduler works according to the following rules:
1. The task with the highest priority of all tasks in the READY state is executed.
2. If several tasks of the same priority are in the READY state,the task that has been ready the longest will be the next to execute.
3. Task switchings are only executed if the first rule would have been otherwise violated (exception: round-robin scheduling).
Time-slice task
change (round-robin scheduling) are executed if the following conditions
are satisfied:
1. Round-robin scheduling must be enabled (see configuration).
2. The RUNNING task has the priority of 0 and is currently not executing a floating-point operation (see section "Floating-Point Operations", page 28).
3. At least one task with the priority zero must be in the READY state.
4. The last task change must have occurred after the selected system time interval (see system function "os_set_slice"). The system time interval can be changed dynamically during program execution.
(Task Communication and
Synchronisation)
There three two
mechanisms:
Signals represent the
simplest and fastest form of task communication. These can always be
used when a pure task synchronisation is required without data exchange.
Each
active task contains its own signal flag with which the following
operations can be executed:
l Wait for a signal
l Send signal
l Clear signal
The task number (see
section section "Task Declaration") of the receiver task is used for
identifying the signals for the individual operations.
n By
means of the mailbox concept, messages can be exchanged free of
conflicts between the individual tasks.
n RTX-51
provides a fixed number of eight mailboxes. Messages can be exchanged
in words (2 bytes) via these mailboxes. In this case, a message can
represent the actual data to be transferred or the identification of a
data buffer(defined by the user). In comparison to the signals,
mailboxes are not assigned a fixed task, but can be freely used by all
tasks and interrupt functions. These are identified with a mailbox
number.
Mailboxes
allow the following operations:
l Send a message
l Read a message
Each mailbox is
internally consists of three wait lists.(Figure 2)
Figure 2
1. Message list
List of the messages
written in the mailbox. These comprise a maximum of eight messages.
2. Write wait list
Wait list for tasks
which want to write a message in the message list of the mailbox
(maximum 16 tasks).
3. Read wait list
Wait list for tasks
which want to read a message from the message list of the mailbox
(maximum 16 tasks).
n By
means of the semaphore concept, resources can be shared free of
conflicts between the individual tasks.
n A
semaphore contains a token that your code acquires to continue
execution. If the resource is already in use, the requesting task is
blocked until the token is returned to the semaphore by its current
owner.
n There
are two types of semaphores: binary semaphores and counting semaphores.
As its name implies, a binary semaphore can only take two values: zero
or one (token is in or out). A counting semaphore, however, allows
values between zero and 65535.
RTX-51
provides a fixed number of eight semaphores of the binary type.
Semaphores
allow the following operations:
l Wait for token
l Return (send) token
RTX-51 performs task synchronisation for external events by means of the interrupt system.
Two types of interrupt processing are basically supported in this case:
1. C51 Interrupt Functions (Interrupt are processed by C51 interrupt funcions)
l Very
sudden, periodically occurring interrupts without large coupling with
the rest of the system (only infrequent communication with RTX-51 tasks,
etc.).
l Very
important interrupts which must be served immediately independent of
the current system state.
2. Task Interrupts(Interrupt are processed by fast or standard tasks of RTX-51
l Fast Task Interrupts
Important or periodic
interrupts which must heavily communicate with the rest of the system
when they occur.
l Standard Task Interrupts
Only seldom occurring
interrupts which must not be served immediately.
RTX-51 shows considerable
different response times for fast and standard tasks.
u The INTERRUPT ENABLE registers of the 8051 are managed by
RTX-51 and must not be directly manipulated by the user!
u The
Interrupt Priority registers of the 8051 (not to be confused with the
softwaretask priorities) are not influenced by RTX-51.
RTX-51 uses a simple and
effective algorithm, which functions with memory blocks of a fixed size.
All memory blocks of the same size are managed in a socalled memory
pool. A maximum of 16 memory pools each a different block size can be
defined. A maximum of 255 memory blocks can be managed in each pool.
n Generate Memory Pool
The application can generate a
maximum of 16 memory pools with various block sizes. The application
must provide an XDATA area for this purpose. The pool is stored and
managed by RTX
n Request Memory Block from Pool
As soon as a pool has been
generated, the application can request memory
blocks. The individual pools
are identified by their block size in this case.
If an additional block is
still free in the pool, RTX-51 supplies the start address
of this block to the
application. If no block is free, a null pointer is returned (see
system function
"os_get_block").
n Return Memory Block to Pool
If the application no longer
needs a requested memory block, it can be returned
to the pool for additional use
(see system function "os_free_block").
RTX-51 maintains an internal
time counter, which measures the relative time passed since system
start. The physical source of this time base is a hardware timer that
generates an interrupt periodically. The time passed between these
interrupts is called a system time slice or a system tick.
This time base is used to
support time dependent services, such as pause or timeout on a task
wait.
Three
time-related functions are supported:
n Set system time slice
The period between the
interrupts of the system timer sets the "granularity" of the time base.
The length of this period, also called a time slice, can be set by the
application in a wide range (see system function "os_set_slice").
n Delay a task
A task may be delayed for a
selectable number of time slices. Upon calling this system function the
task will be blocked (sleep) until the specified number of system ticks
has passed (see system function "os_wait").
n Cyclic task activation
For many real-time
applications it is a requirement to do something on a regular basis. A
periodic task activation can be achieved by the RTX interval wait
function (see system function "os_wait"). The amount of time spent
between two execution periods of the same task is controlled, using
os_wait, and is measured in number of system ticks and may be set by the
application.
(FULL)函数纵览(Functions Overview)
os_start_system
(task_number)
os_create_task
(task_number)
os_delete_task
(task_number)
os_
running_task_id ()
os_attach_interrupt
(interrupt)
os_detach_interrupt
(interrupt)
os_enable_isr
(interrupt)
os_disable_isr
(interrupt)
os_wait
(event_selector, timeout, 0)
oi_set_int_masks
(ien0, ien1, ien2)
oi_reset_int_masks
(ien0, ien1, ien2)
os_send_signal
(task_number)
os_wait
(event_selector, timeout, 0)
os_clear_signal
(task_number)
isr_send_signal
(task_number)
os_send_message
(mailbox, message, timeout)
os_wait
(event_selector, timeout, *message)
isr_send_message
(mailbox, message)
isr_recv_message
(mailbox, *message)
os_send_token
(semaphore)
os_wait
(event_selector, timeout, 0)
os_create_pool
(block_size, *memory, mem_size)
os_get_block
(block_size)
os_free_block
(block_size, *block)
os_set_slice
(timeslice)
os_wait
(event_selector, timeout, 0)
os_check_tasks
(*table)
os_check_task
(task_number, *table)
os_check_mailboxes
(*table)
os_check_mailbox
(mailbox, *table)
os_check_semaphores
(*table)
os_check_semaphore
(semaphore, *table)
os_check_pool
(block_size, *table)
本试验是用的RTX的Tiny版本。也就是说没有优先级之分,没有邮箱机制,没有动态内存的管
理。移植它很简单,就是配置一下它带的配置文件,然后和写好的程序一起编译连接,连接的时候加一个rtxtny参数,意思是说当我连接的时候,我把RTXtiny的库文件连接上,也就等于是程序和操作系统编译在一起了。该配置
文件可以在安装目的rtxtiny2底下找到。文件名称为Conf_tny.A51,例如,在我的电脑中,路径为:D:\Keil\C51\RtxTiny2\SourceCode\ Conf_tny.A51。如下图所示:
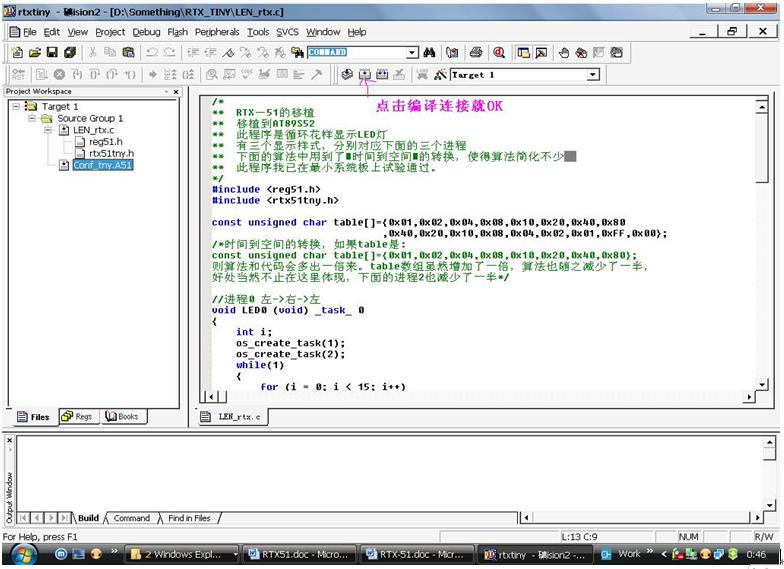
由于试验箱里面的芯片是AT
源程序代码如下,说明请看代码里面的注释。
/*
** RTX-51的移植
** 移植到AT89S52
** 此程序是循环花样显示LED灯
** 有三个显示样式,分别对应下面的三个进程
** 下面的算法中用到了“时间到空间”的转换,使得算法简化不少
** 此程序我已在最小系统板上试验通过。
*/
#include
#include
const unsigned char
table[]={0x01,0x02,0x04,0x08,0x10,0x20,0x40,0x80
,0x40,0x20,0x10,0x08,0x04,0x02,0x01,0xFF,0x00};
/*时间到空间的转换,如果table是:
const unsigned char
table[]={0x01,0x02,0x04,0x08,0x10,0x20,0x40,0x80};
则算法和代码会多出一倍来。table数组虽然增加了
一倍,算法也随之减少了一半,
好处当然不止在这里体现,下面的进程2也减少了一半*/
//进程0 左->右->左
void LED0 (void) _task_ 0
{
int
i;
os_create_task(1);//创建进程1
os_create_task(2);//创建进程2
while(1)
{
for
(i = 0; i < 15; i++)
{
P1 = table[i];
os_wait(K_TMO,30,0);//等待30*10000微妙 = 0.3秒
}
os_send_signal(1); //发送Signal信号,激活
进程1
os_wait(K_SIG,0,0); //等待信号
}
}
//进程1 全亮->全灭->全亮
void LED1 (void) _task_ 1
{
int
i;
while(1)
{
os_wait(K_SIG,0,0);
for
(i = 0; i < 3; i++)
{
P1 = table[15]; //全亮
os_wait(K_TMO,30,0);
P1 = table[16]; //全灭
os_wait(K_TMO,30,0);
}
os_send_signal(2);
}
}
//进程2 两边->中间中间->两边
void LED2 (void) _task_ 2
{
int
i;
while(1)
{
os_wait(K_SIG,0,0);
for
(i = 0; i < 8; i++)
{
P1 = table[i] | table[i+7];
//由于table长度多一倍,省去了一个循环,而且
算法也简化了。
os_wait(K_TMO,30,0);
}
os_send_signal(0);
}
}
本试验用的RTX 的Tiny 版本。许多比较高级的功能没有去实现。目的主要是理解RTX的原理,然后移植它到某个单片机上面, 编写个小程序来测试一下。通过阅读RTX附带的英文文档,我对此操作系统有了深刻的认识,感到此操作系统有很多优点,也有很多不足的地方。比 如支持的任务较少,不过由于是单片机,“承受”能力也有限,也可以理解。总的来说,对于单片机来说是个不错的操作系统。
[1]《RTX-51 官方英文文档》(包括FULL版,和Tiny版)
[2]《Keil
Software –Cx51 编译器用户手册》中文版
文档内容版权所有;代码开源,可以复制应用。
