分类: Mysql/postgreSQL
2018-07-11 15:32:02
转自:https://www.cnblogs.com/pyspark/p/7763241.html
前言
本篇博客将在上一篇的基础上,继续为大家梳理约束相关的知识,前面我们学习了Primary key和unique key方面的知识,本节我们专注于解决使用外键来定义表和表之间的三种关系:多对一,多对多,一对一。本次博客的内容比较重要,希望大家好好理解和记忆。
一.总体原则
判断表与表之间的关系,我们主要通过三个步骤:
【001】1.解读两张表中的每条记录代表什么意思,例如员工表中的一条记录代表一个员工的信息,例如姓名,性别,年龄,所属部门;
而部门表中的一条记录代表某一个部门的信息,例如部门ID,部门名称等;
【002】2.判断左表的多条记录是否可以关联右表的一条记录,同时判断右表的多条记录是否可以关联左表的一条记录
【003】3.如果判断是多对一的关系,那么需要在这个基础上考虑是否是一对一的关系,因此一对一实际上多对一的变种。
二.多对一:单向的foreign key
所谓多对一是指左表的多条记录可以关联右表的一条记录;但是右表的多条记录却不能关联左表的一条记录。例如教师表和课程表,多个老师可以关联一门课程,这就表示多个老师都可以教同一门课程,例如alex可以教Python,tom可以教Python,carson也可以教Python;但是多门课程却不能关联一个老师,毕竟术业有专攻嘛,不可能alex又教Python,又教Linux。所以教师表和课程表是多对一之间的关系。这个多指的是某张表中的多条记录,既然是多条记录,我们就需要使用foreign key来修饰。我们一起来实现刚才的例子:

# 创建课程表 多门课程不能关联一个老师 CREATE TABLE course ( cid INT PRIMARY KEY AUTO_INCREMENT, cname VARCHAR(6) NOT NULL UNIQUE )AUTO_INCREMENT = 100; # 创建老师表 多个老师可以关联一门课程,属于多对一的关系 CREATE TABLE teacher ( tid INT PRIMARY KEY AUTO_INCREMENT, tname CHAR(10) NOT NULL , cid INT NOT NULL , (必须要定义,对应课程表中的cid) FOREIGN KEY(cid) REFERENCES course (cid) ON UPDATE CASCADE ON DELETE CASCADE )AUTO_INCREMENT = 10; 在上面教师表的定义中,我们使用foreign key定义了教师表和课程表之间的关系,最后使用 update cascade和delete cascade 定义了两张表之间的更新和删除关系:级联更新和级联删除 这表明教师表中的cid字段跟随着课程表中的cid字段所对应的记录的更新而更新,删除而删除。 试想一下,例如alex教授Python这门课程,但是有一天课程表中讲这条记录删除了,如果不设置 级联删除,那么课程表中不存在Python这门课程了,但是教师表中还存在,这岂不是很矛盾。同理 如果对课程表中的课程进行了修改,如果不设置级联修改的话,那么教师表中的课程也不会有相应的更新 所以为了保证表与表之间的同步,必须设置级联删除和级联修改。 另外还有一点要注意:既然两表示多对一之间的关系,教师表中的cid字段关联课程表中的cid字段 我们肯定要先创建课程表,然后再创建教师表进行关联。 再例如员工表和部门表,多个员工记录可以关联部门表中的一条记录,表示多个员工属于相同的一个部门;但是多个部门记录却不能 关联同一个员工,因为不可能一个员工你属于多个部门;因为虽然有些人可能做的事跨部门,但是它毕竟还是属于某一个部门。这里的 员工表和部门表之间的关系是多对一的关系。 在上面的例子中,我们判断出教师表和课程表是多对一的关系,在此基础上考虑两者是否存在一对一之间的关系。由于教师表中的课程ID 不可能是唯一的,因为不可能存在每个老师教授的课程都是唯一的,只能是这样的情况。例如alex,tom,carson教授python,Eva,Egon教授 云计算,老男孩老师教授Linux;所以在教师表中的CID就对应多个课程ID。因此两者不可能是一对一之间的关系。
三.一对一
在上面的例子中,我们谈到如果两张表的关系是多对一的关系,我们就要考虑两者是否可能是一对一之间的关系。所谓一对一是指左表的一条记录唯一对应右表的一条记录。采用foreign key+unique实现。我们来看下面的例子:
以老男孩的教学为例,现在给定学生表和客户表,学生表记录着所以已经成为老男孩正式学员的学生,而客户表意味着有潜在机会成为老男孩正式学员的人,就是说学生表中的人肯定都是由客户演变过来的 。我们来尝试分析下两张表之间的关系,学生表中的多条记录不能关联客户表中的一条记录,因为不可能说客户表中的一条记录能够演变为多个正式学员,只能是演变为一个学员;而客户表中的多条记录却可以关联 学生表中的一条记录,因为可能存在说这5个客户,最后只有一个成为老男孩的正式成员,其他四个由于各种原因都没有成为老男孩的学员。分析到这里,我们可以断定客户表和学生表是多对一之间的关系。那我们接着分析 两者是否可能是一对一的关系。对于客户表而言,它里面的学生表ID是唯一的,不可能存在任意两个学生的ID是相同的,所以分析到这里,两者应该是一对一之间的关系。我们来看看它们的一个关系图
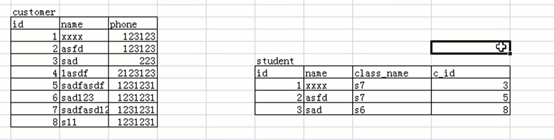
如上图所示,一个客户演变为一个学生,然后在学生表的记录中添加一个c_id即可。既然两者是一对一之间的关系,那么具体在SQL语句上怎么设计呢?如下:
create table student(
id int primary key auto_increment,
name char(6),
class_name char(10),
c_id int unique, #保证学生表中的c_id是唯一的,由客户演变为学生,所以是学生foreign key 客户表 使用unique关键字来修饰外键,只有这样才能保证是一对一之间的关系 foreign key(s_id) references student(id)
on update cascade
on delete cascade
);
create table customer( # 客户表只需要正常创建即可
id int primary key auto_increment,
name char(6),
phone int,
qq char(11),
mail varchar(20),
);
四.多对多
所谓多对多是指双向的foreign key,具体而言是说左表的多条记录对应右表的一条记录,而右表的多条记录也能对应左表的一条记录。我们还是通过实际的例子来说明:
需求:给定角色表和用户表,因为每个用户都有相应的角色,例如角色可以是管理员,教学主管,班主任等等。角色表中的多条记录可以
关联用户表中的一条记录,这就类似于一个人拥有多种角色,例如它既可以是管理员,又可以是教学主管;而用户表中的多条记录也可以
关联角色表中的一条记录,这就意味着多个用户都可以是同一种角色,例如Alex,Egon,Tom这些人可以都是教学主管。这样就形成了一个
双向多对多的关系,所以两者的关系是一个多对多的关系。
现在我们来考虑如何创建两者表,前面我们说过当两张表之间的关系是多对一时,例如教师表和课程表,肯定需要先创建多对一中的一,即
肯定需要先创建课程表,然后教师表中的cid才能foreign key到课程表中。但是现在是多对多之间的关系,这就陷入了一个双向死循环,怎么办?
我们的思路是创建一个第三方表来表示两张表之间的关系,然后这两张表直接按照正常创建即可,看如下的例子:
【001】创建用户角色表:
CREATE TABLE role (
id INT PRIMARY KEY AUTO_INCREMENT,
name CHAR(10),
permission CHAR(3),
COMMENT VARCHAR(10)
);
【002】创建用户表
CREATE TABLE user (
id INT PRIMARY KEY AUTO_INCREMENT,
name CHAR(6),
password VARCHAR(20)
);
【003】既然是多对多的关系,双方彼此关联对方,因此需要创建一个第三张表来关联这两张表,如下所示:
CREATE TABLE user2role (
id INT PRIMARY KEY AUTO_INCREMENT,
user_id INT, # 对应用户表中的ID,相当于是外键 role_id INT, # 对应角色表中的ID,相当于是外键 FOREIGN KEY (user_id) REFERENCES user (id)
ON UPDATE CASCADE
ON DELETE CASCADE,
FOREIGN KEY (role_id) REFERENCES role (id)
ON UPDATE CASCADE
ON DELETE CASCADE
);
五.案例解析
前面我们详细分析了使用外键来关联两张表之间的关系,这里我们通过几个实际的例子来强化上面的知识点,一起来看看下面的几个例子:
【001】
# 6.表结构设计(20分)
# a)设计表
# 用户表与部门表(一个用户只能属于一个用户组)(6分)
# 部门表与主机表(一个部门可以管理多台主机)(6分)
# b)查询
# 查询技术部门的员工总数(2分)
# 查询技术部门管理的主机数(2分)
# 查询员工李平所在部门管理的主机信息(2分)
# 查询ip为192.168.45.10的主机所在部门的员工信息(2分)
# 创建三张表:1.用户表,2.部门表,3.主机表
# 多个用户可以对应一个部门记录,多个部门记录不能关联一个用户,属于多对一的关系
# 多台主机可以对应一个部门,多个部门可以关联一台主机 属于多对多的关系
我们一起来分析下用户表,部门表,主机表三张表之间的关系:
【001】部门表的整体记录可以看作是一个用户组,多个用户可以关联部门表中的一条记录,即这多个用户属于同一个部门,在同一个用户组里面;
而部门表中的多条记录却不能关联一个用户,因为一个用户它只能属于一个用户组,所以用户表和部门表示多对一的关系;
【002】再来分析部门表和主机表之间的关系。部门表中的多条记录可以关联主机表中的一条记录,因为一台主机是可以被多个部门使用的,这样
做到了资源共享;主机表中的多条记录是可以关联部门表中的一条记录的,即一个部门在使用主机表中的这些主机。因此部门表和主机表是
多对多的关系。明确了两者之间的关系,我们可以开始来创建表:
# 创建用户表
CREATE TABLE monthexam.user_info (
uid INT PRIMARY KEY AUTO_INCREMENT,
username VARCHAR(20) NOT NULL,
password VARCHAR(50) NOT NULL,
d_id int,
FOREIGN KEY(d_id) REFERENCES department(dept_id) ON UPDATE CASCADE ON DELETE CASCADE
);
# 创建部门表
create table department(
dept_id int PRIMARY KEY AUTO_INCREMENT,
name varchar(20) NOT NULL
);
# 创建主机表
CREATE TABLE host (
host_id int PRIMARY KEY AUTO_INCREMENT,
ip CHAR(16) NOT NULL UNIQUE DEFAULT '127.0.0.1' )AUTO_INCREMENT=100;
# 建立主机表和部门表多对多的关系
CREATE TABLE hostTodept(
id INT PRIMARY KEY AUTO_INCREMENT,
host_id INT NOT NULL ,
dept_id INT NOT NULL ,
FOREIGN KEY (host_id) REFERENCES host(host_id) ON UPDATE CASCADE ON DELETE CASCADE,
FOREIGN KEY (dept_id) REFERENCES department(dept_id) ON UPDATE CASCADE ON DELETE CASCADE
);
接下来我们插入数据:
# 为用户表插入数据
INSERT INTO user_info (username, password, d_id) VALUES
('root', '123', 200),
('carson', '456', 201),
('李平', 'cisco',200),
('eva', '123456', 203),
('王五', '45678', 202),
('赵六', '666', 201),
('王依', '678910', 200),
('tom', '1234', 202);
#为部门表插入数据
insert into department values
(200,'技术'),
(201,'人力资源'),
(202,'销售'),
(203,'运营');
# 为主机表插入数据
INSERT INTO host (ip) VALUES
('172.16.41.3'),
('172.16.28.10'),
('172.16.44.3'),
('172.16.32.11'),
('172.10.45.3'),
('172.10.45.4'),
('192.168.45.10'),
('192.168.11.22'),
('192.168.21.23'),
('192.168.11.223'),
('192.168.11.24');
最后我们来完成上面的查询需求:
# 查询技术部门的员工总数
SELECT d.name as '部门', count(u.uid) as '员工总数' FROM department d LEFT JOIN user_info u ON d.dept_id = u.d_id where d.name='技术' GROUP BY d.dept_id;
#查询技术部门管理的主机数
SELECT d.name as '部门' , count(h.host_id) as '主机数' FROM department d INNER JOIN hostTodept h ON d.dept_id = h.dept_id
WHERE d.name='技术';
# 查询员工李平所在部门管理的主机信息
SELECT host_id as '主机ID', ip as '主机IP' FROM host where host_id IN
(
SELECT host_id
FROM hostTodept
WHERE dept_id IN
(SELECT d.dept_id
FROM user_info u INNER JOIN department d ON u.d_id = d.dept_id where u.username='李平')
);
# 查询ip为192.168.45.10的主机所在部门的员工信息
SELECT * FROM user_info where d_id IN(
SELECT ht.dept_id
FROM host h INNER JOIN hostTodept ht ON h.host_id = ht.host_id
WHERE h.ip='192.168.45.10' );
六.选课系统之表关系
我们首先来看如下这张选课系统之间的图,我们尝试来理清它们之间的关系:
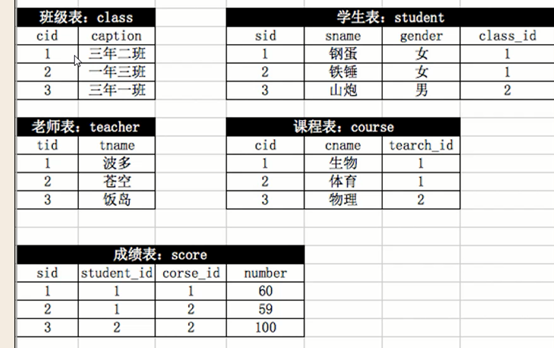
上面主要存在五张表:学生表,班级表,老师表,课程表,成绩表 学生和班级之间的关系:多个班级可以关联一个学生(即一个学生可以参加不同的班级学习多门不同的课程,例如carson即可参加Linux班
的学习,又可以参加Python班级的学习);
多个学生可以关联一个班级,这表示一个Python班级里面有多名学生;这又是一个多对多的关系 老师和课程之间的关系:多个老师可以教一门课程,多个课程不可以被一个老师教(术业有专攻)即一个老师不能教多门课程。
这个关系是多对一的关系,是老师关联课程,意味着teacher表要添加一个字段:cid 班级和课程之间的关系:多个班级可以对应一门课程,例如7期python,6期python
多门课程不可以对应一个班级,即7期Python不能又教Python,还教Linux课程。因此这个属于多对一的关系。即班级foreign key 课程 学生和课程之间的关系:多个学生可以选择一门课程,多个课程可以关联一个学生,这是一个多对多的关系
这里我们有点小问题,学生和课程之间不应该直接发生关系,而应该采用成绩表来关联。虽然学生表和课程表实际上是多对多的关系,但是
为了按照实际的需求,例如统计某个学生某门课程的分数,我们是应该创建一张成绩表。
在本篇博客的最后,我们来一起复习下前面的set知识点:
