全部博文(135)
2010年(135)
分类: LINUX
2010-04-12 14:36:36
Java中的变量分为两类:局部变量和类变量。局部变量是指在方法内定义的变量,如在run方法中定义的变量。对于这些变量来说,并不存在线程之间共享的问题。因此,它们不需要进行数据同步。类变量是在类中定义的变量,作用域是整个类。这类变量可以被多个线程共享。因此,我们需要对这类变量进行数据同步。
数据同步就是指在同一时间,只能由一个线程来访问被同步的类变量,当前线程访问完这些变量后,其他线程才能继续访问。这里说的访问是指有写操作的访问,如果所有访问类变量的线程都是读操作,一般是不需要数据同步的。
那么如果不对共享的类变量进行数据同步,会发生什么情况呢?让我们先看看下面的代码会发生什么样的事情:
看到这个结果,可能很多读者会感到奇怪。这个程序明明是启动了100个线程,然后每个线程将静态变量n加1。最后使用join方法使这100个线程都运行完后,再输出这个n值。按正常来讲,结果应该是n = 100。可偏偏结果小于100。
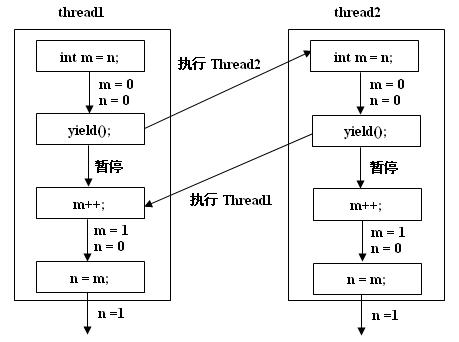
其实产生这种结果的罪魁祸首就是我们经常提到的“脏数据”。而run方法中的yield()语句就是产生“脏数据”的始作俑者(不加yield语句也可能会产生“脏数据”,但不会这么明显,只有将100改成更大的数,才会经常产生“脏数据”,在本例中调用yield就是为了放大“脏数据”的效果)。yield方法的作用是使线程暂停,也就是使调用yield方法的线程暂时放弃CPU资源,使CPU有机会来执行其他的线程。为了说明这个程序如何产生“脏数据”,我们假设只创建了两个线程:thread1和thread2。由于先调用了thread1的start方法,因此,thread1的run方法一般会先运行。当thread1的run方法运行到第一行(int m = n;)时,将n的值赋给m。当执行到第二行的yield方法后,thread1就会暂时停止执行,而当thread1暂停时,thread2获得了CPU资源后开始运行(之前thread2一直处于就绪状态),当thread2执行到第一行(int m = n;)时,由于thread1在执行到yield时n仍然是0,因此,thread2中的m获得的值也是0。这样就造成了thread1和thread2的m获得的都是0。在它们执行完yield方法后,都是从0开始加1,因此,无论谁先执行完,最后n的值都是1,只是这个n被thread1和thread2各赋了一遍值。这个过程如下图如示:
也许有人会问,如果只有n++,会产生“脏数据”吗?答案是肯定的。那么n++只是一条语句,又如何在执行过程中将CPU交给其他的线程呢?其实这只是表面现象,n++在被Java编译器编译成中间语言(也叫做字节码)后,并不是一条语言。让我们看看下面的Java代码将会被编译成什么样的Java中间语言。
Java源代码
被编译后的中间语言代码
大家可以看到在run方法中只有n++一条语句,而在编译后,却有7条中间语言语句。我们并不需要知道这些语句的功能是什么,只看一下第005、007和008行语句。在005行是getfield,根据它的英文含义可知是要得到某个值,因为这里只有一个n,所以毫无疑问,是要得到n的值。而在007行的iadd也不难猜测是将这个得到的n值加1。在008行的putfield的含义我想大家可能已经猜出来了,它负责将这个加1后的n再更新回类变量n。说到这,可能大家还有一个疑惑,执行n++时直接将n加1不就行了,为什么要如此费周折。其实这里涉及到一个Java内存模型的问题。
Java的内存模型分为主存储区和工作存储区。主存储区保存了Java中所有的实例。也就是说,在我们使用new来建立一个对象后,这个对象及它内部的方法、变量等都保存在这一区域,在MyThread类中的n就保存在这个区域。主存储区可以被所有线程共享。而工作存储区就是我们前面所讲的线程栈,在这个区域里保存了在run方法以及run方法所调用的方法中定义的变量,也就是方法变量。在线程要修改主存储区中的变量时,并不是直接修改这些变量,而是将它们先复制到当前线程的工作存储区,在修改完后,再将这个变量值覆盖主存储区的相应的变量值。
在了解了Java的内存模型后,就不难理解为什么n++也不是原子操作了。它必须经过一个拷贝、加1和覆盖的过程。这个过程和在MyThread类中模拟的过程类似。大家可以想象,如果在执行到getfield时,thread1由于某种原因被中断,那么就会发生和MyThread类的执行结果类似的情况。要想彻底解决这个问题,就必须使用某种方法对n进行同步,也就是在同一时间只能有一个线程操作n,这也称为对n的原子操作。
