
GooSeeker研发中心发布的本身就是一款抓取网页内容并将其结构化存储的工具,GooSeeker网站有大量文档资料介绍MetaSeeker的原理,GooSeeker虽然也密切关注的发展动向,但是公开发布的MetaSeeker在线版更关注实用价值,相反国外的更多类似产品在网页内容结构化方面更进一步,本文介绍,它是语义网络项目Simile中的一个部件,Solvent与MetaSeeker的最大区别是前者采用XQuery而非XPath,结构化后的数据采用RDF而非XML进行存储,从而具有更多语义网络的色彩。
Solvent与MetaSeeker的详细对比
界面对比
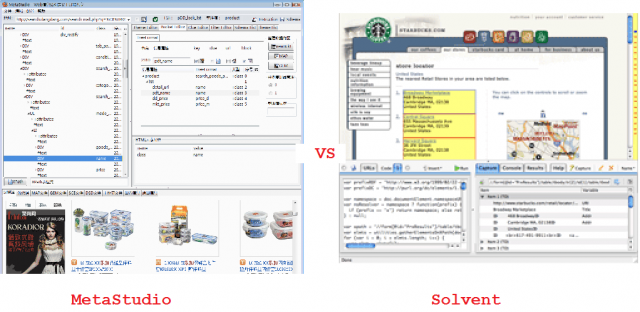
相同点
- 都是Firefox扩展(Firefox entension,有时俗称插件,这是不严格的说法)
- 都是网页抓取规则的生成工具,确切地说,Solvent应该与MetaSeeker中的MetaStudio对应。
不同点
- 生成的网页抓取规则
- Solvent:采用XQuery
- MetaSeeker:采用XPath和XSLT
- 网页抓取结果存储格式
- Solvent:采用RDF
- MetaSeeker:采用XML
- 执行效率
- Solvent:具有实验性质,Javascript代码居多
- MetaSeeker:成熟的商业软件(在线版免费),核心全部用C++代码写成
- 网页抓取结果进一步加工处理
- Solvent:主要为提供数据,Piggy Bank也是一个火狐扩展,将抓取到的网页内容。实际上,Piggy Bank拥有很多专用的网页抓取工具,参见其,Solvent只是其中一个。
- MetaSeeker:很多信息处理服务器都可以使用MetaSeeker抓取的数据,例如,SliceSearch是一个结构化对象 搜索引擎,并提供普通的垂直搜索功能;MetaCorpora是一个通用的语料库管理器;SliceProfile是一个通用的中文自动分类和舆情监测引 擎;是电子商城价格监测和竞争分析平台;是一个实时机票价格监测和比价平台,如果加上MetaSeeker客户开发的各式各样的信息处理服务器,产品不下万种。
其它信息
据《Solvent – Firefox Extension for Screen Scraping and XQuery Generator》称,Solvent生成的网页抓取规则可以提供给开源Java网页抓取工具使用。