分类: 系统运维
2011-03-15 20:46:47
采用AJAX技术的网站越来越多,我们有必要通过更多案例讲解怎样准确地抓取Javascript/JS动态生成的内容。这一次我们要抓取 cnbeta网站上的数码产品新闻。进入这个网站的首页,能够看到一个新闻列表,列表中有多条新闻,每条包括标题、基本信息和摘要等部分。用浏览器访问这 个网页,发现新闻列表第一页与普通网页一样,翻页到第二页以后,用浏览器的查看源代码功能可以看出来HTML源代码没有改变,无论现在看到第几个分 页,HTML源代码仍然是第一页的。原来该网站在翻页时使用Javascript动态刷新新闻列表,这种情形将阻碍普通网络爬虫和普通网页抓取器的工作, 因为这类网页抓取器一般通过向目标服务器发送HTTP GET消息,获得HTML文档,然后采用正则表达式或者DOM解析的方法将网页上的内容提取出来,当需要翻到其它分页时,由于其它分页没有独立的URL网 页地址,无法发送HTTP GET消息,只能通过人工干预的方式,嗅探Javascript向网站发送了什么消息,通过模拟消息以获得其它分页的内容。采用网页抓取器,可以完全丢弃嗅探方法,跟抓取普通网页一样抓取AJAX网站内容。
本文还将讲解另一个抓取技巧:翻页抓取新闻列表时,假设某个分页中的新闻都是以前抓取过的,则停止向下翻页,也就是说只抓取最新新闻,这是跟踪论坛、博客、微博、新闻网站等等最常用技巧,也是建设的必备功能。
抓取目标分析:
注释1:可以用MetaStudio加载信息结构demo_cnbeta_list,对照着阅读更容易理解。请注意,目标网页结构可能会变化,也许会造成信息结构加载不成功,请参照《修改失效的信息结构》对信息结构进行修改。
注释2:本文不是入门教程,如果对MetaSeeker不熟悉,建议按照章节顺序阅读《MetaSeeker速成手册》。

首先需要定义数据抓取规则,所谓数据抓取规则,就是规定怎样从网页上将新闻列表数据抓取下来。图1显示了数据映射和FreeFormat映射的过程,主要有以下步骤:

我们在《分级抓取》一文已经讲过怎样为第二级主题抓取线索,图2再次显示抓取下一级线索的方法,设定clue特性后,在Clue Editor工作台上自动创建了一个Info类线索,在Clue Editor工作台上,将下一级的主题命名为demo_cnbeta_detail(如图3)所示。
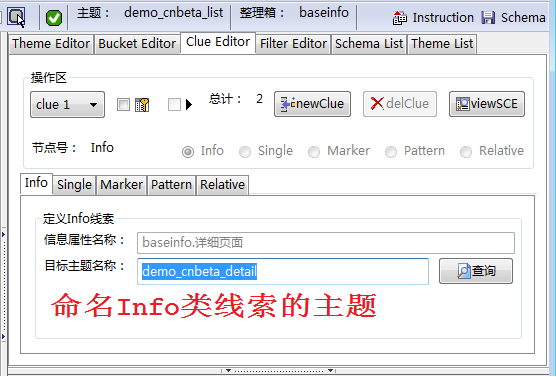
定义Info类线索的目的有二:
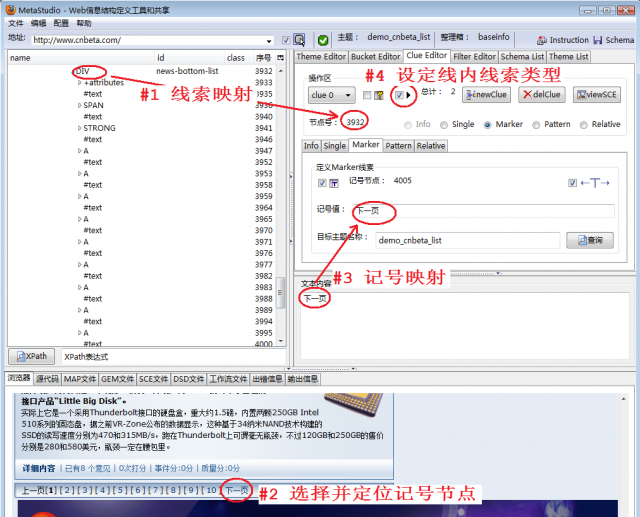
为了翻页抓取所有分页,需要创建一条线索,图4显示了主要步骤,详细说明参见《抓取当当商品价格》:

如图5所示,选择MetaStudio的菜单“配置”-〉“积极模式”,设置AJAX抓取模式。
在《分页抓取卓越亚马逊》一文,我们同时设置“积极模式”和“延长模式”,两个模式不是绑定在一起的。本目标网站每翻一页并没有另加载一个网页,而是局部修改网页内容,所以,设置“延长模式”是没有意义的。
通常我们会每隔一定时间(例如,一天)抓取新闻列表,如果发现有新的新闻,则将其URL抓取下来并创建下一级的线索,以便将最新的新闻内容抓取下来。如果发现新闻列表中全部都是以前抓取过的新闻,则停止翻页抓取。这需要采用周期性自动抓取方法。需要编辑。此文件必须命名成crontab.xml,并且存放在$HOME/.datascraper目录中。目录结构的详细说明参见《抓取当当商品价格》。下面是crontab.xml文件的内容:
true
5
3600
false
demo_cnbeta_list
demo_cnbeta_list
false
80
-1
-1
false
0
true
23
1800
false
demo_cnbeta_detail
false
80
-1
-1
false
0
所有参数的含义在中解释,跟“只抓取最新新闻”有关的是抓取主题demo_cnbeta_list的dupRatio参数,80表示80%,也就是说如果翻页抓取时发现连续3页抓取到的URL地址有80%是以前已经抓取过的,则终止翻页抓取。
注意1:MetaSeeker现版本只能判断抓取到的下一级线索的重复率,而不能判断抓取到的数据的重复率。
注意2:请不要直接使用上述crontab.xml,因为在MetaSeeker服务器上暂时还没有定义信息结构demo_cnbeta_detail,会导致周期性抓取失败。
