分类: 系统运维
2010-12-29 18:51:25
采用了多项发明专利,例如,确保有很高适应性的FreeFormat技术, 当目标网页结构发生改变时,该技术能够尽可能确保以前定义好的网页抽取规则有效。但是,如果目标网站大规模改版,无法避免网页抽取规则失效。此 时,MetaSeeker还有最后一道防线:降低修改规则的复杂度,用可见即可得(WYSISYG)的方式修正以前的规则,就像操作MS Word编辑文字文档一样简单。
下面,我们用主题名是demo_JD_list_1的信息结构为例说明怎样修改失效的抽取规则。
注释1:demo_JD_list_1是在写作本文之前不久定义好的信息结构,详细步骤参见《抽取京东商城网页数据》,这说明引起加载失效的原因不是目标网页结构改变,而是因为网页语义信息块的定位不精确。但是,本文我们仍然以它为例,仅仅用以说明怎样编辑失效的网页抽取规则,所以,修正后的信息结构仍然可能因为定位不精确而不能被成功加载。关于怎样精确定位,请参见《抽取新蛋网页数据》。
注释2:本文非入门教程,所以,不会将操作步骤一步步分解开并用屏幕截图显示出来,如果需要入门知识,请参考《抽取当当网页数据》。
注释3:即使信息结构无法成功被MetaStudio加载,此信息结构生成的网页抽取规则可能仍然有效,因为MetaStudio和 DataScraper采用不同的定位规则。所以,不必急于用MetaStudio对其重新修改,可以直到DataScraper在运行期间显示出错日志 再采取行动。
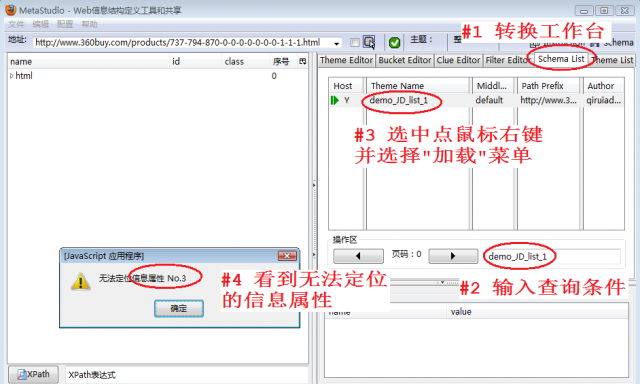
如图1,有下面的步骤:
即便如此,我们仍然点击确认按钮,将加载过程进行到底,以便修改信息结构。
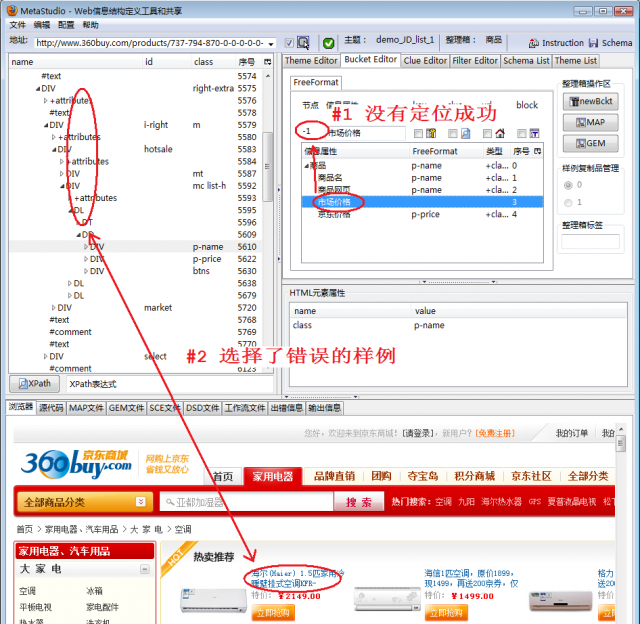
图2分析失败原因:
下面,我们将重新编辑信息结构。
MetaStudio通过网页内容映射方式描述网页抽取规则,您可以不用关心真正的抽取规则指令,由MetaStudio自动生成,您只需要告诉MetaStudio:网页上的哪块数据需要抽取。直观友好的图形界面利于快速定义和低成本管理网页抽取规则。
因为MetaStudio自动选择的样例不合适,所以,为所有信息属性定位到的网页数据都不合适,首先需要清除这些映射关系。
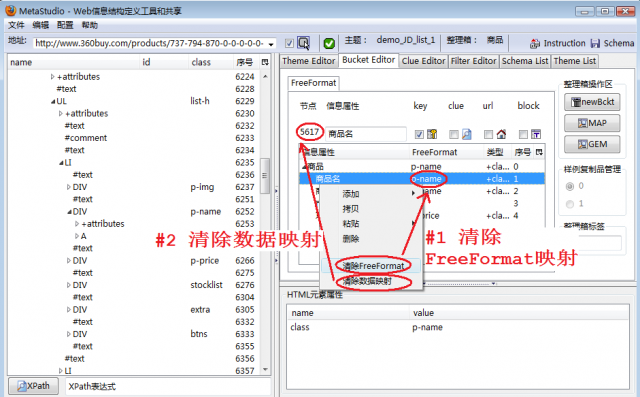
如图3,挨个选择信息属性,然后点击鼠标右键,看到弹出菜单,进行如下步骤:

如图4,选择正确的样例后重新做数据映射和FreeFormat映射,步骤如下:
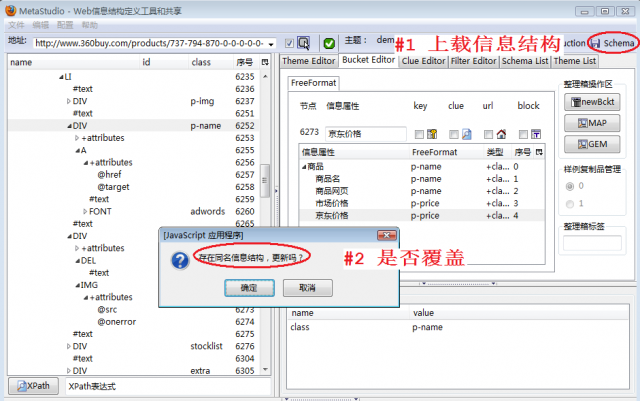
假设没有更改主题名,上载后,新信息结构覆盖老的,会有如图5的提示:
上载信息结构时,MetaStudio将自动生成的网页抽取规则同时上载到了MetaSeeker服务器,假设现在有DataScraper正在运行,会有什么影响呢?
根据《批量抽取当当网页数据》,DataScraper有两种批量抽取模式:
当DataScraper以第一种模式运行时,正在抽取的网页不会使用新规则,但是,当用户开始新一批抽取时,DataScraper会再次向服务器查询抽取规则,所以,会使用新规则。
相反,当DataScraper以第二种模式运行时,新规则永远不会被采用,只得重新运行DataScraper才行。
经过上面步骤以后,信息结构被修改了,但是,本例仅仅为了讲解修改信息结构的过程,并没有解决实际问题。实际问题是:本例的信息结构不能加载的原因是因为没有精确定位,而不是网页结构变化。请参考《抽取新蛋网页数据》彻底解决精确定位问题。
chinaunix网友2010-12-30 12:40:06
很好的, 收藏了 推荐一个博客,提供很多免费软件编程电子书下载: http://free-ebooks.appspot.com
