分类: 服务器与存储
2008-12-18 15:29:33
然而,正如任何系统一样,没有什么是完美的。当系统故障发生,沮丧的我们应该认识到这是生活的一部分。任何复杂如Amazon网络服务的系统,没有人能保证不会发生一点问题。正因为如此,单一、偶然发生的故障问题并不能衡量服务的质量。
那么,云计算真的就不好么?事实当然并非如此,相反,它具有强大的生命力以及美好的前景。
“云”与LAMP
网络服务起源于L.A.M.P的组合(linux、Apache、MySQL、Perl),直至今日依然强大有效,因此仍是许多流行网站的选择。LAMP贵在简洁之美,这使得上手非常容易。但它却存在扩展性差的问题:其一为Apache网站服务器的线程与scoket的连接少,因此当面临负载增加又未合理配置的情况时,网站的运转就有可能出现故障;其二就是MySQL的关系型数据库规模有限,因此成了整个系统最大的瓶颈,这个问题尤为突出。
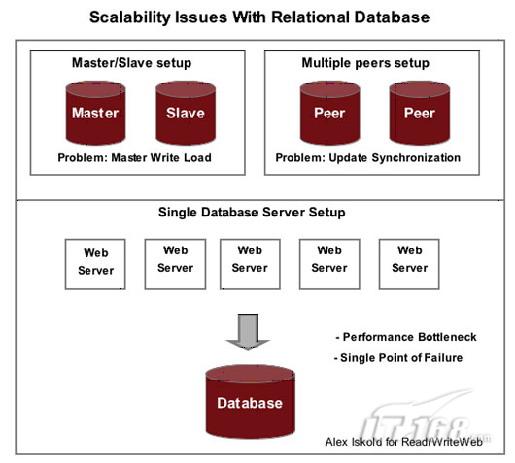
关系型数据库因为信息表征方式导致了容量的受限。并且,当达到一定规模时,管理还会变得困难。右下图明显可见,单一的关系型数据库与网络服务器间存在着明显的性能瓶颈以及单点失效的风险。为解决这一问题,一种名为数据分区的技术可以使关系型数据库的数据划分到N个独立集中去。如果这样行不通的话,唯一的方法就是放弃关系型数据库,改用分布式数据库,而这恰恰就进入了“云”的范畴。
云计算的概念
云计算的想法并不难理解,就是要将应用程序分散布置在由众多硬件盒组成的一个大型网格中。每个盒子内部系统相同,且规格均一。起平衡整个系统负载作用的负载均衡器发出的指令可以在各个盒间流水般无阻碍的通行,因此看似分散的盒子能运作如一体,迅速做出反应,宛如分散的小水滴在大气压作用下凝聚成一体终成浮动的白云,这就是“云”的概念。“云”之美还在于它的扩展性,你可以很容易地向“云”中添加更多的盒子。
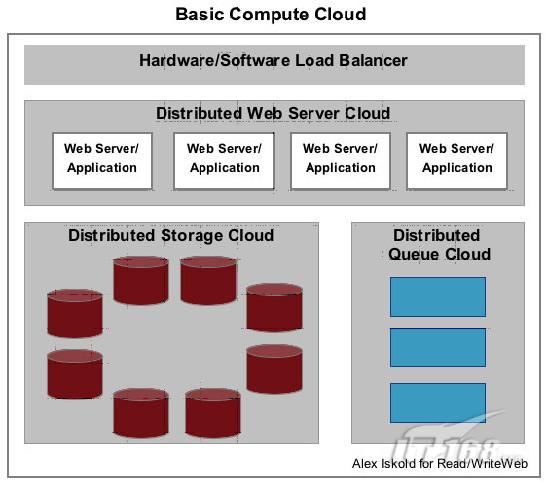
在上图中可以看出,计算云包括了三个最基本的组分:一个网站服务/应用层,一个分布式存储层,以及一个分布式队列层。每一个层都可作为“云”本身,也就是说层的每一组分在功能和结构上完全一致。在这最简单的模型中,web tier就当于LAMP中的bit概念,在“云”中,网络服务器同样可以采用Apache,同样可以运行应用程序的PHP代码,但与LAMP根本不同的是数据库不再是MySQL,而采用了分布式存储系统系统,如Amazon S3, Amazon SimpleDB或Amazon Dynamo。分布式队列层除了在无法实时操作的情况下需要外,并不是必须的。
“云”最大的优势是它支持按需变化的运算商务模式。比如说,一个建立在“云”上的能支持1,000~10,000位客户的网络服务如果需要将客户容量提高到10,000,000,那么仅仅只需向“云”中添加盒子的数量。从商业前景来说,这是非常具有吸引力的,因为采用“云”之后很容易计算出系统扩展所需要的成本。
云计算的现状
“云”计算最好的例子无疑是Google。这个网络世界的巨头搭建和控制了数以百计、千计甚至于百万计的硬件盒,构成了一朵庞大的“云”。但为了应对不断增长的网络用户的服务请求,Google还在一刻不停地扩展着“云”的规模。
当然,Google并不是唯一的实践者,而是几乎所有大型的网站包括Amazon, eBay, Yahoo! 和Facebook都采用了各种形式的云计算。尤其是Amazon,凭借着它在分布式计算领域的领先地位,在过去的15年一直完善着这项技术,所以不难理解它要将未来的赌注压在垂直网站服务上。他们相信未来属于云计算,掌握了云计算的核心就掌握了生财之道,这一点上没人比他们做的更好。
云计算的可靠性
对于Amazon的服务崩溃,也许有业内人士会想:如果换成是我做的话,我一定能做的更好。这种设想一直存在于软件业的发展史中,如计算机语言种类的重复发明、API不断地推翻重写,我们总认为比前人更聪明、更富有创新性,但99.9%的事实证明我们是错的。所以说这次错不在于Amazon,在我们之前,他们已经投入了巨大的财力和人力来试图解决这些问题。大规模的运算服务是一个异常复杂和庞大的问题,即使对最具智慧和前途的工程师来说,也需花费数年来弄懂和解决它。
就目前来说,搭建云计算平台可以通过独立设计和技术购买两种手段来实现。除非特定云计算结构需要独立设计外,大部分情况下,采用Amazon网络服务的云计算结构能满足需要。如果要击败对手,必须要明白和突出自己的产品的独特性,否则走重新设计的路线,你会发现你已失去时间和资源。
也许Amazon服务崩溃不仅仅是“云”的问题,是否还应该考虑一下SLA(Service Level Agreements,服务品质协议)? 明明SLA上保证的是99.99%的网络服务可用率,可当服务使用3小时后就陷于瘫痪的情况该如何解释呢?我们应该知道,无论SLA上怎样的承诺,它不可能保证电力供应系统和“云”结构的完美无瑕地运作。
所以我们不能盲目相信SLA,而是要动用自己的大脑。评价一个系统性能的稳定性不是看它是否会崩溃,而是预测它出现崩溃现象的频率。如果Amazon的网络服务一年内只有3小时的停工期,那么可以认为是完美无缺的;如果是每个月,那么就是不可接受的;如果是每天,那将是令人抓狂的。
未来的发展
Amazon事件不会影响它的网络服务计划,更不会阻碍云计算发展的步伐。Amazon一直是云计算的先行者,它建立的大规模平行网站式计算服务正为世界上越来越多的人所接受。我们有理由相信这仅仅只是云计算的开始,它正在从根本上改变着人类运算的方式。
云计算解决了扩展性的问题,供应商们就能把精力集中到自己产品和服务中去。随着硬件成本、带宽和服务费用不断降低,云计算不再缥缈,而是触手可得,人类将乘着云计算来到了另一个天空。
