C++,python,热爱算法和机器学习
全部博文(1214)
分类: Java
2017-11-27 23:55:06
今天来说下使用ES 5.0.1的API来进行编码。
开始之前,简单说下5.0.1跟之前的几个变化。之前的ES自身是不支持delete-by-query的,也就是通过查询来删除,可以达到批量的效果,是因为刷新的原因,应该够近实时的特性相关。一直是以一个插件的形式存在,到5.0.1时,倒腾了半天,还是官方文档说,已经废掉了这个插件,放到ES Core中来了。这是一个变化,另外,初始化ES client的方式也变化了,这个要吐槽一下,从1.7到2.X,初始化方式改了一遍,从2.X到5.X又变了,让人有点受不了啊!
闲话不提,开始。
本篇谈到初始化,增,删,改。对于查询,我们用单独一节来说。
ES的初始化:
Settings esSettings = Settings.builder()
.put("cluster.name", clusterName) //设置ES实例的名称
.put("client.transport.sniff", true) //自动嗅探整个集群的状态,把集群中其他ES节点的ip添加到本地的客户端列表中
.build();
client = new PreBuiltTransportClient(esSettings);//初始化client较老版本发生了变化,此方法有几个重载方法,初始化插件等。
//此步骤添加IP,至少一个,其实一个就够了,因为添加了自动嗅探配置
client.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName(ip), esPort));
对于ES Client,有两种形式,一个是TransportClient,一个是NodeClient。两个的区别为:
TransportClient作为一个外部访问者,通过HTTP去请求ES的集群,对于集群而言,它是一个外部因素。
NodeClient顾名思义,是作为ES集群的一个节点,它是ES中的一环,其他的节点对它是感知的,不像TransportClient那样,ES集群对它一无所知。NodeClient通信的性能会更好,但是因为是ES的一环,所以它出问题,也会给ES集群带来问题。NodeClient可以设置不作为数据节点,在elasticsearch.yml中设置,这样就不会在此节点上分配数据。
如果用ES的节点,大家仁者见仁智者见智,各按所需。
现在已经通过TransportClient连接到了集群。下一步就是创建索引,有一个常用的关系型数据库与ES的映射关系:
关系型数据库 -> 索引
关系型数据表 -> 类型
关系型数据项 -> 文档
字段 -> 字段
说到索引,简单说下分片(shard)。ES本身是分布式的,所以分片自然而然,它的分片并非将所有的数据都放在一起,以默认的5个主分片为例,ES会将数据均衡的存储到5个分片上,也就是这5个分片的数据并集才是整个数据集,这5个分片会按照一定规则分配到不同的ES Node上。这样的5个分片叫主分片。然后就是从分片,默认设置是一个主分片会有一个从分片,那么就有5个从分片,那么默认配置会产生10个分片(5主5从)就散布在所有的Node上。主分片的个数是索引新建的时候设置的,一经设置,不可改变,因为ES判断一条文档存放到哪个分片就是通过这个主分片数量来控制的。简单来讲,插入的文档号与5取余(实际不是这样实现的,但是也很简单)。检索结果的时候,也是通过这个来确认结果分布的,所以不能改。从分片的数量可以随便改,因为塔是跟主分片关联的。另外,Node节点也可以随时加,而且ES还会在新节点加入之后,重新调整数据分片的分布。
新建索引:
client.admin().indices().prepareCreate(indexName).get();
或者
client.admin().indices().prepareCreate(indexName).setSettings(settings).get();
ES是区分大小写的,索引所有数据在进到ES之前,最好都规格化。
setSettings挺有用,比如上面说的设置分片数就是通过这里设置的,参数可以是JSON,也有其他的重载;
这里说下在新建索引的时候配置默认的分词器IK
{"analysis":{"analyzer":{"ik":{"tokenizer":"ik_smart"}}}}
这是我用JSON序列化出来的,红底的ik是我为analyzer设置的名字,通过这个名字在索引和检索的时候,来调用ik分词器。当然,我们打算把IK设置为默认的分词器,可以将ik改为default,这样就不需要在索引和检索的时候指定了,默认的分词器为standardAnalyzer。
设置好之后,新建一个Index,可以用Kibana瞧瞧结果:
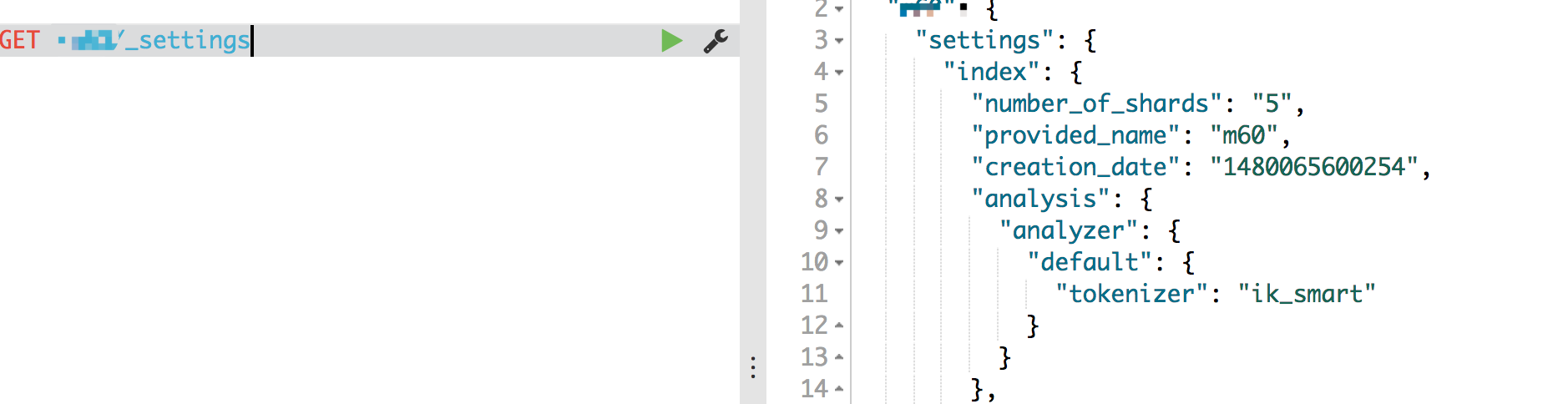
注意,Kibana有个坑,就是用它来分词中文,会有乱码,这个跟ES没关系,用Kibana的结果
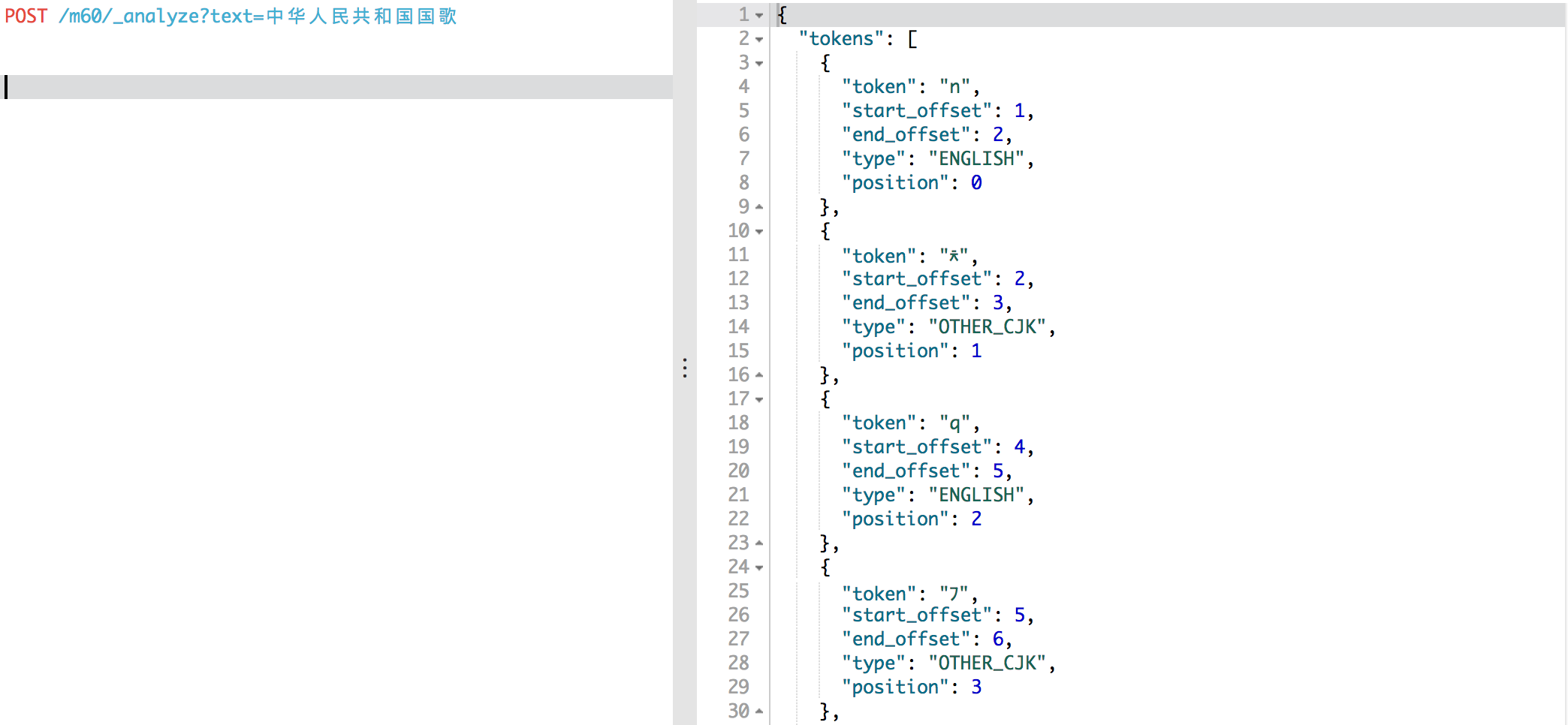
用FireFox的插件Request的结果,话说Request还是极好用的:
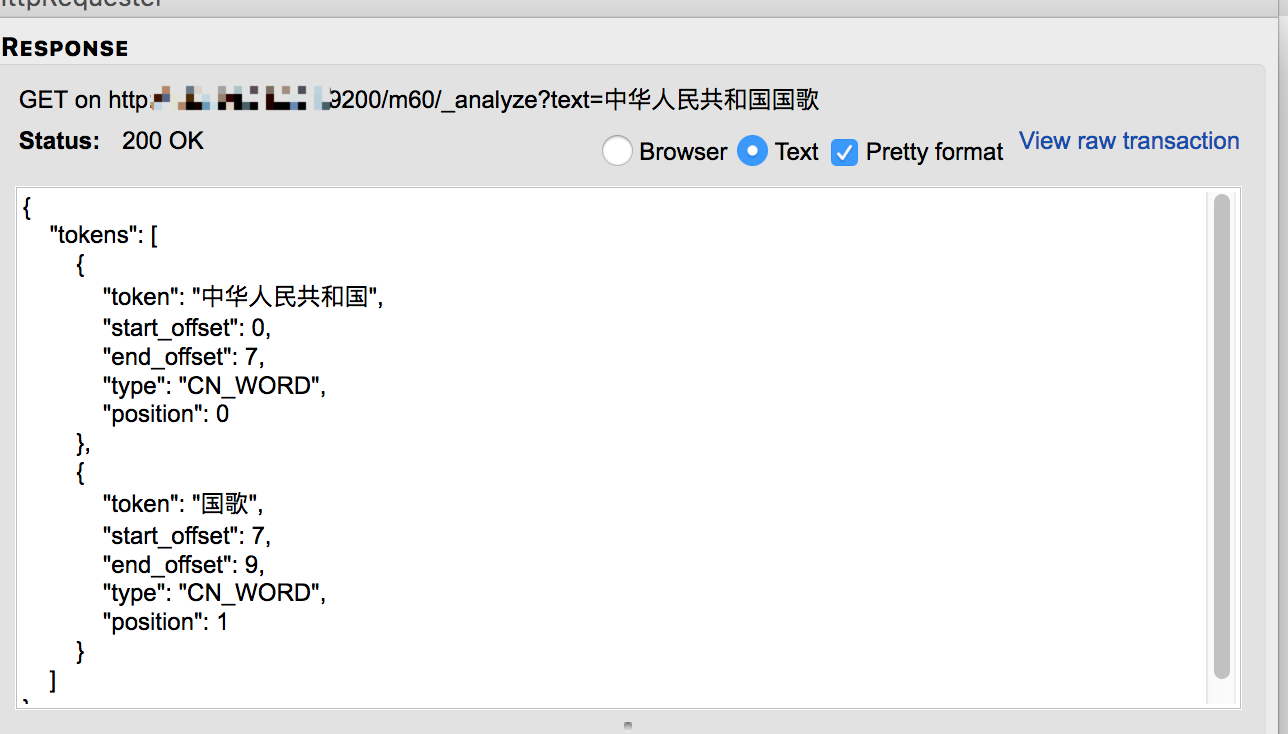
有遇到并知道为啥的给指点一下。
创建好了索引,接下来就是类型了,创建类型很简单,直接插入一个文档,如果文档所属的类型不存在,则会新建,如果存在,就直接插入。但是在插入文档之前,我们可以对一些预料到的字段或者其他属性进行一个预定义的设置,比如,我在插入文档之前,想让所有的id都是long类型,并且id是要存储并且不需要分析的。(关于字段存储和分析,下回再说)。可以用MappingRequest这个类帮我们达到目的。直接上代码
XContentBuilder builder = XContentFactory.jsonBuilder()
.startObject()
.startObject(type)
.startObject("properties");
JSONObject object = mapping.getJSONObject(i);
builder.startObject(object.getString("fieldName"));
builder.field("type", object.getString("fieldType"));
builder.field("index", "not_analyzed");
builder.field("store", "yes");
builder.endObject();
builder.endObject().endObject().endObject();
PutMappingRequest mappingRequest = Requests.putMappingRequest(index).type(type).source(builder);
client.admin().indices().putMapping(mappingRequest).actionGet();
这样就指定好了mapping。
那接下来我们添加文档,添加文档可以单条添加,也可以批量添加:
单条添加:
client.prepareIndex(indexName, type)
.setSource(jsonData)
.setId(jsonData.getString(KEY))//自己设置了id,也可以使用ES自带的,但是看文档说,ES的会因为删除id发生变动。
.execute()
.actionGet();
批量添加:
BulkRequestBuilder bulkRequestBuilder = client.prepareBulk();
for (int i = 0; i < docData.size(); i++){
bulkRequestBuilder.add(client.prepareIndex(indexName, type).setId(docData.getJSONObject(i).getString("id")).setSource(docData.getJSONObject(i)));
}
BulkResponse bulkResponse = bulkRequestBuilder.execute().actionGet();
bulkRequestBuilder.request().requests().clear();
if (bulkResponse.hasFailures()){
//TODO:
}
删除:
client.prepareDelete(indexName, type, docId).execute().actionGet();
更新
UpdateRequest updateRequest = new UpdateRequest();
updateRequest.index(indexName).type(type).id(jsonData.getString("id")).doc(jsonData);
client.update(updateRequest);
以上代码都很简单,但都有不少重载,可以先通过一个方法进去,然后研究各个重载是应对什么情况的。
通过上面的编码,就可以在我们的程序中实现ES的初始化,添加文档,删除文档,和更新文档。最后,再说下delete-by-query。
ES提供接口,可以直接删除整个索引
client.admin().indices().delete(new DeleteIndexRequest(indexName)).actionGet();
上面也提到了删除一个文档,但是如果删除整个type呢?es是没有提供整个东西的。因为ES是基于Lucene的,Lucene的核心是文档,一个索引就是一个文件夹,里面存储都是文档,所以没有type的物理概念。ES里面提供了这样一个概念。是一组Field定义相同的文档的集合。那么我们要删除特定的集合的文档,比如一个type下的,怎么做的?Lucene提供了delete by query的能力,那么,我们就按照这个去做就是了:
QueryBuilder builder = QueryBuilders.typeQuery(type);//查询整个type
DeleteByQueryAction.INSTANCE.newRequestBuilder(client).source(indexName).filter(builder).execute().actionGet();
好了,最后再提一点,所有的操作之后,都至少要等待1s,因为ES/Lucene是近实时,而不是准实时,索引才做之后,会有默认的刷新时间,之后才可以将更新真正生效。一定要注意这点。
