2008年(8065)
分类: 服务器与存储
2008-07-17 14:08:31
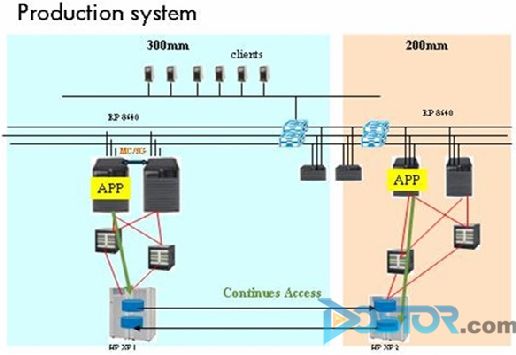
由于是芯片企业,系统可靠性是第一位的,一旦停机损失惨重(每小时的损失高达100万美金,主要是停产的产品销售额和高昂机器设备的折旧),所以在IT系统上是非常舍得投入的。虽然采用了RAC,但负载全部集中在其中一台机器上,采购两台一样配置的机器加RAC就是为了在down机时,能零时间切换到另外一台机器上。
从上图可以看出,200mm和300mm的MES系统互相隔离,两个SAN也没有连接起来。客户的应用部门认为,万一300mm的存储XP12000坏掉,虽然在200mm的XP12000系统上仍然有数据,但是应用并不能自动切换来访问,所以提出了系统容灾的项目。由于系统大部分是HP的,当然HP被邀请提交解决方案。另外客户在其他的系统上还使用了EMC的Symmetrix,有竞争才能获得更好的价格,同时EMC也对这样一个大客户虎视眈眈,所以EMC也参与了方案提交。最后总共提交了三个方案:
方案 1:HP Campuscluster + RAC
方案 2:HP Metrocluster+CA
方案 3:Oracle data guard
