2008年(8065)
分类: 服务器与存储
2008-05-28 15:06:53
性能调优有多重要呢?在一个Raid 5的阵列组中使用5-9块硬盘和使用默认的设置,CLARiiON光纤储系统能发挥极好的性能----这是EMC在性能测试实验室里测试自己的CLARiiON系统得出来的。
CLARiiON存储系统默认的设置是为实际环境中遇到的大部分工作情形所设计的。但是,有一些工作情景还是需要调优来实现存储系统的最佳配置。
为什么在阵列组里用5到9块硬盘?这个设置并没有任何神奇的地方,也不是因为这个配置有什么特殊的优化。然而,Raid 5使用这个数量的硬盘确实是最有效的利用了校验,同时也能在合理的时间能重建数据。更小的阵列组会有更高的校验开销,而大的阵列组则会花更长的时间来重建数据。
这份白皮书探讨了在设计优化系统方面的时设计到的许多要素。请注意这里提供的信息是非常有帮助的,尤其当你充分理解了你的阵列的工作情形。因此,EMC推荐你使用Navisphere Analyzer来分析你的阵列的工作情形,并且要定期的复习和回顾相关文档的基础知识。同时,请记住在配置一个阵列的时候很少有显而易见的选择,所以在有疑问的时候最好是按照默认的配置和保守的评估。
1.性能的定义
以下的名词在整个白皮书当中都会用到。如果你对他们不熟悉,请回顾一下 EMC CLARiiON Fibre Channel Storage Fundamentals
带宽
校验
读取
随机
响应时间
要求数据大小 Request size
顺序
条带
条带元素 Stripe element
吞吐量
Write-aside
二,.应用的设计
应用的设计对系统的表现影响很大。提升性能的最佳方法的第一步就是应用的优化。任何存储系统的调优都不可能建立一个非常差的应用设计上面。
A. 为顺序或者随机I/O的优化
非常典型的一个例子是,提升带宽在顺序访问的调优方面会起显著作用,因为存储系统在顺序I/O方面会更加有效率--尤其是在RAID5的时候。而为随机访问的调优则要改善吞吐量和更快的响应时间,因为这样会改善处理顾客响应所花的时间。
读和写的对比写比读更加耗费存储系统的资源,这是基于CLARiiON对数据保护的机制的应用。写到write cache是镜像到两个存储控制器的(SP)。写到带校验的Raid Group会碰到校验运算的要求,而这也要求把冗余的信息写到磁盘里面。写到镜像的Raid Group会需要两份数据的拷贝的写入。
读的开销相对会小一些,这是因为,从CLARiiON系统的读的吞吐量会比写的吞吐量要大一些。但是,对大部分工作情形来看,数据往往是写入write cache,这样会有更短的响应时间。读,在另一方面来说,可能命中cache,也可能不命中cache;而对大部分随机的工作情形来说,读比写会有更高的相应时间,因为数据还是需要从磁盘里面抓取。如果要达到高的随机读取吞吐量,需要更好的协作(concurrency)。
B. I/O 的大小
每一个的I/O都有一个固定的开销和一个变量的开销,后者决定于其他的一些事情,例如I/O的大小。
大的I/O能提供更少的固定开销因为有着更大的数据。因而,对CLARiiON而言大的I/O比小块的I/O能提供更大的带宽。如果有足够的硬盘,在执行大的I/O的时候后段总线的速度将会成为系统的性能瓶颈。小块的随机访问应用(例如OLTP)的瓶颈在于磁盘(的个数),而且很少达到后端总线速率。
当设计OLTP的时候,必须要使用基于磁盘(的个数)的IOP来衡量,而不是使用基于总线的带宽来衡量。
然而,在一个CLARiiON存储系统里面,当I/O到了某一个特定的大小的时候,包括write caching和prfetching都会被bypass掉。是决定用一个大的I/O请求还是把他分成几个顺序的请求,取决于应用程序和它跟cache之间的相互作用。这些相互作用在 “The Raid engine Cache”里会探讨到。
文件系统也可以影响到I/O的大小,这也在稍后的“Host file-system impact”中描述到。
C. 暂时的模式和峰值的表现(temporal patterns and peak activities)
应用的操作设计--如何去使用,什么时候去使用,什么时候需要去备份--都会影响到存储系统的负载。例如,用作随机访问的应用的存储系统,在备份和批量处理的时候,需要好的顺序性能。
一般来说,对OLTP和消息应用(任何跟大量随机访问I/O有关的),更高的并发处理能力(concurrency)会更好。当有更高的并发处理能力的时候,存储系统将会获得更高的吞吐量。使用异步I/O是一种获得更高的并发处理能力的通常的手法。对带宽而言,单线程的应用几乎不能有效地利用四块硬盘以上带来的好处,除非request size是非常大的(比2MB大)或者使用到volume manager.当最佳的顺序性能达到的时候,而此时如果顺序处理到磁盘的路径是唯一的时候,用户还是可以从有适度并发随机访问的光纤硬盘(每个硬盘的I/O在100以下)的设置中获得一个可接受顺序性能。
三.主机文件系统影响
在主机层次,通过指定最小最大的I/O request size,文件系统也影响了应用I/O的特性。
A.文件系统的缓冲和组合(coalesce)
跟在存储系统上的cache相似的是,缓冲是文件系统提高性能的一种主要方式。
缓冲
在大部分的情况下,文件系统的缓冲应该最大化,因为这能减少存储系统的负载。然而,还是会有一些意外。
一般来说,应用自己来调配缓冲,能避免文件系统的缓冲或者在文件系统的缓冲之外工作。这是基于应用能更加有效的分配缓冲的假设之上。而且,通过避免文件系统的coalesce,应用更能控制I/O的响应时间。但是,正如在64位的服务器里RAM的容量将会提升到32GB或者更多,这也就有可能把这个文件系统都放在缓冲里面。这就能使读操作在缓冲下,性能会有非常显著的提升。(写操作应该使用写透(write-through)的方式来达到数据的持续性。)
结合Coalescing
文件系统的coalesce能帮助我们从存储系统里获得更高的带宽。在大部分顺序访问的操作里面,用最大邻近和最大物理的文件系统设置来最大?文件系统的coalescing.例如,这种处理方式可以和备份程序一起把64KB的写操作结合(coalesce)成一个完全stripe的写操作,这样在write cache被bypass的情况下,对于带校验的Raid会更加有效果。
B.最小化I/O的大小:文件系统的request size
文件系统通常都被配置成一个最小的范围大小,例如4KB,8KB或者64KB,这是提供给阵列的最小的不可分割的请求。应用使用的I/O在比这个范围大小要小的时候,会导致很多不必要的数据迁移和/或read-modify-write的情形出现。这也是考虑应用和文件系统文件的最佳设置的最好办法。(it is best to consult application and file system documentation for the optimal settings)而request size没有被文件系统限制的Raw partitions,则没有受到这个约束。
C.最大化的I/O大小
如果想要快速的移动大量的数据,那么一个大的I/O(64KB或更大)会更加有帮助。在整合(coalescing)顺序的写操作成Raid Group整个的stripe的时候,阵列将会更加有效率,正如预读取大的顺序读操作一样。大的I/O对从基于主机的stipe获得更好的带宽而言也是很重要的,因为他们将会被基于srtipe的toplogy打散成更小的大小。
D.文件系统的fragmentation
避免fragmentation和defragementation在一起,这是一个基础的原则。注意NTFS文件系统可能被分区成任何形式除了默认的范围大小,他们不能被大部分的工具所defragement:这个API(程序的接口)并不能允许这样做。执行一个文件级别的拷贝 (到另一个LUN或者执行一个文件系统的备份和恢复)是defragement的一个有效的实现。
文件系统的对齐
文件系统的不对齐会在以下两个方面影响性能:
1.不对齐造成了跨硬盘的访问:一个I/O跨越了两个硬盘(正常来说是只会访问到一个硬盘)
2.不对齐会让大的没有cache的写操作,变得难以条带对齐(strip-align)
第一个情形是更加容易碰到的。就算磁盘上的操作使用了cache的缓冲,也会对(性能)产生负面的影响,因为这会使cache的flushing变慢。随机的读操作(通过正常要求的磁盘访问产生的),也会受到相应的影响,不管是直接的(等待两个磁盘的响应以便返回数据)还是间接的(使磁盘的操作比正常更加忙)。
一个通常的例子如下图所示。基于intel架构的系统是不对齐的,这是因为元数据(Metadata)是被BIOS所写的。在一个对齐的系统,64KB的写操作会由单独一个硬盘来服务。
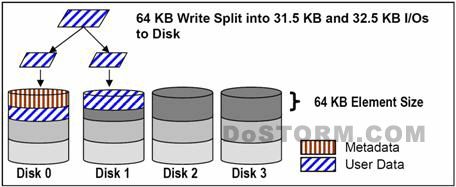
跨越磁盘的小I/O在一些主机的类型里显得更加重要,而我们接下来将会探讨为什么会导致这种状况。
当以下情况发生的时候,跨越磁盘将会对响应时间有一个显而易见的影响:
a)有大比例的block size大于16KB的随机I/O
b)Navisphere Analyzer报告的硬盘的平均等候队列长度比4大的时候对齐4KB或者8KB边界的时候(例如Exchange和Oracle),工作负载将会从对齐中获得一些优势。但因为I/O当中,小于6%(对于4KB)或者12%(对于8KB)的I/O都会造成跨盘操作(碰巧的是他们可能会以并行的方式来完成)。这种额外的收益可能很难在实践中注意到。但如果当一个特定的文件系统和/或应用鼓励使用对齐的地址空间并且位移(offset)被注明,EMC推荐使用操作系统的磁盘管理来调整分区。Navisphere LUN的绑定位移(offset)工具应该要小心的使用,因为它可能反而会影响分层的应用同步速度。
在intel架构系统中的文件对齐
intel架构的系统,包括windows2000/windows2003,都会受到在LUN上元数据的位置的影响,这也会导致磁盘分区的不对齐。这是因为遗留的BIOS的代码问题,BIOS里面用的是磁柱,磁头和扇区地址来取代LBA地址。
(这个问题一样影响了使用intel架构的linux操作系统,正如windowsNT,2000,和2003。这个问题也一样影响了运行在intel硬件上的VMWare系统)
fdisk 命令,正如windows的Disk Manager,把MBR(Master Boot Record)放在每一个SCDI设备上。MBA将会占用设备上的63个扇区。其余可访问的地址是紧接着这63个隐藏分区。这将会后续的数据结构跟CLARiiONRAID的stripe变得不对齐。
在linux系统上,这个隐藏扇区的多少取决于boot loader和/或磁盘管理软件,但63个扇区是一个最常遇到的情况。对于VMware,位移(offset)是63。
在任何情况下,这个结果都为确定的比例的I/O而导致不对齐。大的I/O是最受影响的。例如,假设使用CLARiiON默认的stripe element 64KB,所有的64KB的I/O都会导致跨盘操作。对于那些比这个stripe element的小的I/O,会导致跨盘操作的I/O的比例,我们可以通过以下公式来计算:
Percentage of data crossing=(I/O size)/(stripe element size)
这个结果会给你一个大致的概念,在不对齐的时候的开销状况。当cache慢慢被填充的时候,这种开销会变得更大。
