分类: Oracle
2010-12-21 11:47:53
(一)内存结构和进程结构 Oracle数据库的总体结构如下图:
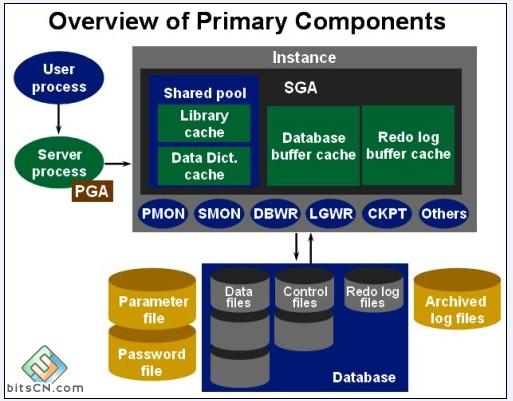
1:Oracle实例(Instance)
在一个服务器中,每一个运行的Oracle数据库都与一个数据库实例相联系,实例是我们访问数据库的手段。
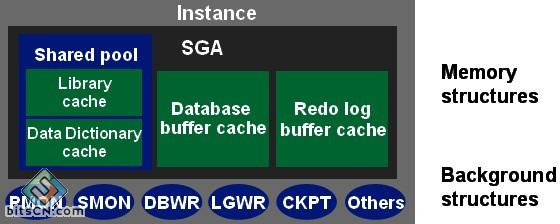
实例在操作系统中用ORACLE_SID来标识,在Oracle中用参数INSTANCE_NAME来标识,它们两个的值是相同的。数据库启动时,系统首先在服务器内存中分配系统全局区(SGA),构成了Oracle的内存结构,然后启动若干个常驻内存的操作系统进程,即组成了Oracle的进程结构,内存区域和后台进程合称为一个Oracle实例。
数据库与实例之间是1对1/n的关系,在非并行的数据库系统中每个Oracle数据库与一个实例相对应;在并行的数据库系统中,一个数据库会对应多个实例,同一时间用户只与一个实例相联系,当某一个实例出现故障时,其他实例自动服务,保证数据库正常运行。在任何情况下,每个实例都只可以对应一个数据库。
2:Oracle 10g动态内存管理
内存是影响数据库性能的重要因素,Oracle8i使用静态内存管理,Oracle 10g使用动态内存管理。所谓静态内存管理,就是在数据库系统中,无论是否有用户连接,也无论并发用量大小,只要数据库服务在运行,就会分配固定大小的内存;动态内存管理允许在数据库服务运行时对内存的大小进行修改,读取大数据块时使用大内存,小数据块时使用小内存,读取标准内存块时使用标准内存设置。
按照系统对内存使用方法的不同,Oracle数据库的内存可以分为以下几个部分:
2-1:系统全局区SGA(System Global Area)
SGA是一组为系统分配的共享的内存结构,可以包含一个数据库实例的数据或控制信息。如果多个用户连接到同一个数据库实例,在实例的SGA中,数据可以被多个用户共享。
当数据库实例启动时,SGA的内存被自动分配;当数据库实例关闭时,SGA内存被回收。
SGA是占用内存最大的一个区域,同时也是影响数据库性能的重要因素。
SGA的有关信息可以通过下面的语句查询,sga_max_size的大小是不可以动态调整的。
=====================================
SQL> show parameter sga
NAME TYPE VALUE
------------------------------------ ----------- --------
lock_sga boolean FALSE
pre_page_sga boolean FALSE
sga_max_size big integer 164M
sga_target big integer 0
SQL> alter system set sga_max_size=100m;
alter system set sga_max_size=100m
*
ERROR at line 1:
ORA-02095: specified initialization parameter cannot be modified
======================================
系统全局区按作用不同可以分为:
2-1-1:数据缓冲区(Database Buffer Cache)
如果每次执行一个操作时,Oracle都必须从磁盘读取所有数据块并在改变它之后又必须把每一块写入磁盘,显然效率会非常低。数据缓冲区存放需要经常访问的数据,供所有用户使用。修改数据时,首先从数据文件中取出数据,存储在数据缓冲区中,修改/插入数据也存储在缓冲区中,commit或DBWR(下面有详细介绍)进程的其他条件引发时,数据被写入数据文件。
数据缓冲区的大小是可以动态调整的,但是不能超过sga_max_size的限制。
======================================
SQL> show parameter db_cache_size
NAME TYPE VALUE
------------------------------------ ----------- -----------------
db_cache_size big integer 24M
SQL> alter system set db_cache_size=128m;
alter system set db_cache_size=128m
*
ERROR at line 1:
ORA-02097: parameter cannot be modified because specified value is invalid
ORA-00384: Insufficient memory to grow cache
SQL> alter system set db_cache_size=20m;
System altered.
SQL> show parameter db_cache_size;
NAME TYPE VALUE
------------------------------------ ----------- -----------------
db_cache_size big integer 20M
#此处我仅增加了1M都不行?
SQL> alter system set db_cache_size=25m;
alter system set db_cache_size=25m
*
ERROR at line 1:
ORA-02097: parameter cannot be modified because specified value is invalid
ORA-00384: Insufficient memory to grow cache
#修改显示格式,方便查看。
SQL> column name format a40 wrap
SQL> column value format a20 wrap
#下面语句可以用来查看内存空间分配情况,注意SGA各区大小总和。
SQL> select name,value from v$parameter where name like '%size' and value <> '0';
#先将java_pool_size调小,然后再修改db_cache_size
SQL> show parameter java_pool_size;
NAME TYPE VALUE
------------------------------------ ----------- -----
java_pool_size big integer 48M
SQL> alter system set java_pool_size=20m;
System altered.
SQL> alter system set java_pool_size=30m;
System altered.
#上面说明SGA中各区大小总和不能超过sga_max_size。
=====================================
数据缓冲区的大小对数据库的存区速度有直接影响,多用户时尤为明显。有些应用对速度要求很高,一般要求数据缓冲区的命中率在90%以上。
下面给出一种计算数据缓冲区命中率的方法:
•使用数据字典v$sysstat
=====================================
SQL> select name, value from v$sysstat
2 where name in('session logical reads',
3 'physical reads',
4 'physical reads direct',
5 'physical reads direct (lob)')
NAME VALUE
------------------------------- ----------
session logical reads 895243
physical reads 14992
physical reads direct 34
physical reads direct (lob) 0
======================================
命中率=1-(14992-34-0)/895243
可以让Oracle给出数据缓冲区大小的建议:
======================================
SQL> alter system set db_cache_advice=on;#打开该功能
System altered.
SQL> alter system set db_cache_advice=off;#关闭该功能
System altered.
======================================
2-1-2:日志缓冲区(Log Buffer Cache)
日志缓冲区用来存储数据库的修改信息。该区对数据库性能的影响很小,有关日志后面还会有详细的介绍。
查询日志缓冲区大小:
SQL> show parameter log_buffer
NAME TYPE VALUE
---------- ----------- -------
log_buffer integer 262144
2-1-3:共享池(Share Pool)
共享池是对SQL,PL/SQL程序进行语法分析,编译,执行的内存区域。
它包含三个部分:(都不可单独定义大小,必须通过share pool间接定义)。
共享池的大小可以动态修改:
======================================
SQL> show parameter shared_pool_size
NAME TYPE VALUE
------------------------------------ ----------- ------
__shared_pool_size big integer 80M
shared_pool_size big integer 80M
SQL> alter system set shared_pool_size=78m
System altered.
======================================
#上面的__shared_pool_size一行奇怪?
2-2:程序全局区PGA(Programe Global Area)
程序全局区是包含单个用户或服务器数据和控制信息的内存区域,它是在用户进程连接到Oracle并创建一个会话时由Oracle自动分配的,不可共享,主要用于用户在编程存储变量和数组。
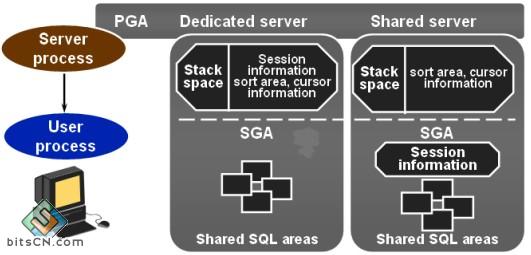
如上图:
注意Session information(用户会话信息)在独占服务器中与在共享服务器中所处的内存区域是不同的。
2-3:排序区,大池,Java池
排序区(Sort Area)为有排序要求的SQL语句提供内存空间。系统使用专用的内存区域进行数据排序,这部分空间就是排序区。在Oracle数据库中,用户数据的排序可使用两个区域,一个是内存排序区,一个是磁盘临时段,系统优先使用内存排序区进行排序。
如果内存不够,Orcle自动使用磁盘临时表空间进行排序。为提高数据排序的速度,建议尽量使用内存排序区,而不要使用临时段。
参数sort_area_size用来设置排序区大小。(好象不能动态修改?)
大池(Large Pool)用于数据库备份工具--恢复管理器(RMAN:Recovery Manager)。
Large Pool的大小由large_pool_size确定,可用下面语句查询和修改:
=========================================
SQL> show parameter large_pool_size
NAME TYPE VALUE
----------------- ----------- -------
large_pool_size big integer 8M
SQL> alter system set large_pool_size=7m;
System altered.
=========================================
Java池主要用于Java语言开发,一般来说不低于20M。其大小由java_pool_size来确定,可以动态调整。
2-4:Oracle自动共享内存管理(Automatic Shared Memory(SGA) Management)
在Oracle 8i/9i中数据库管理员必须手动调整SGA各区的各个参数取值,每个区要根据负荷轻重分别设置,如果设置不当,比如当某个区负荷增大时,没有调整该区内存大小,则可能出现ORA-4031:unable to allocate ...bytes of shared memory错误。
在Oracle 10g中,将参数STATISTICS_LEVEL设置为TYPICAL/ALL,使用SGA_TARGET指定SGA区总大小,数据库会根据需要在各个组件之间自动分配内存大小。
下面是系统自动调整的区域:
注意:如果不设置SGA_TARGET,则自动共享内存管理功能被禁止。
==========================================
SQL> show parameter statistics_level
NAME TYPE VALUE
--------------------- ----------- ------------
statistics_level string TYPICAL
SQL> alter system set statistics_level=all;
System altered.
#typical和all有什么区别?
SQL> alter system set statistics_level=typical;
System altered.
SQL> show parameter sga_target
NAME TYPE VALUE
------------- ----------- ----------
sga_target big integer 0
SQL> alter system set sga_target=170m;
alter system set sga_target=170m
*
ERROR at line 1:
ORA-02097: parameter cannot be modified because specified value is invalid
ORA-00823: Specified value of sga_target greater than sga_max_size
SQL> alter system set sga_target=20m;
System altered.
#不过后来又发现sga_target的值变成了140M? 下面是语句执行情况。
SQL> show parameter sga_target
NAME TYPE VALUE
------------- ----------- -------
sga_target big integer 140M
SQL> alter system set sga_target=0;
System altered.
SQL> show parameter sga_target
NAME TYPE VALUE
------------------------------------ ----------- ------
sga_target big integer 0
#改为20M
SQL> alter system set sga_target=20m;
System altered.
#显示的是140M
SQL> show parameter sga_target
NAME TYPE VALUE
------------------------------------ ----------- ------
sga_target big integer 140M
#不可缩减?
SQL> alter system set sga_target=130m;
alter system set sga_target=130m
*
ERROR at line 1:
ORA-02097: parameter cannot be modified because specified value is invalid
ORA-00827: could not shrink sga_target to specified value
#不可增加
SQL> alter system set sga_target=141m;
alter system set sga_target=141m
*
ERROR at line 1:
ORA-02097: parameter cannot be modified because specified value is invalid
ORA-00823: Specified value of sga_target greater than sga_max_size
3:Oracle实例的进程结构(Process Structure)
Oracle包含三类进程:
3-1:用户进程和服务器进程
当数据库用户请求连接到Oracle的服务时启动用户进程(比如启动SQLPlus时)。
3-2:后台进程(Backgroung Process)
数据库的物理结构与内存结构之间的交互要通过后台进程来完成。数据库的后台进程包含两类,一类是必须的,一类是可选的:
可以用下面的语句查看正在运行的后台进程:
=========================================
SQL> select * from v$bgprocess where paddr<>'00';
PADDR PSERIAL# NAME DESCRIPTION
-------- ---------- ----- -------------------------------
6B0ED064 1 PMON process cleanup
6B0ED4E4 1 MMAN Memory Manager
6B0ED964 1 DBW0 db writer process 0
6B0EDDE4 1 LGWR Redo etc.
6B0EE264 1 CKPT checkpoint
6B0EE6E4 1 SMON System Monitor Process
6B0EEB64 1 RECO distributed recovery
6B0EEFE4 1 CJQ0 Job Queue Coordinator
6B0F01E4 1 QMNC AQ Coordinator
6B0F0664 1 MMON Manageability Monitor Process
6B0F0AE4 1 MMNL Manageability Monitor Process 2
========================================
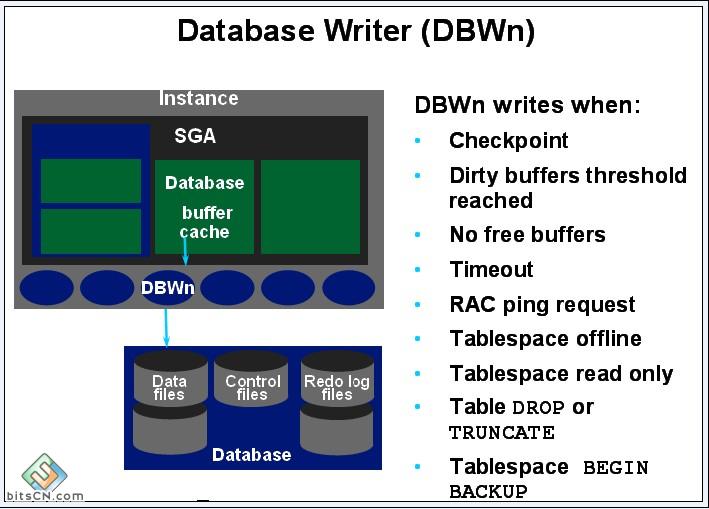
3-2-1:DBWR(Database Writer,数据写入进程)
将数据缓冲区的数据写入数据文件,是负责数据缓冲区管理的一个后台进程。
当数据缓冲区中的一数据被修改后,就标记为dirty,DBWR进程将数据缓冲区中“脏”数据写入数据文件,保持数据缓冲区的”干净“。由于数据缓冲区的数据被用户修改并占用,空闲数据缓冲区会不断减少,当用户进程要从磁盘读取数据块到数据缓冲区却无法找到足够的空闲数据缓冲区时,DBWR将数据缓冲区内容写入磁盘,使用户进程总可以得到足够的空闲数据缓冲区。
DBWR的作用:
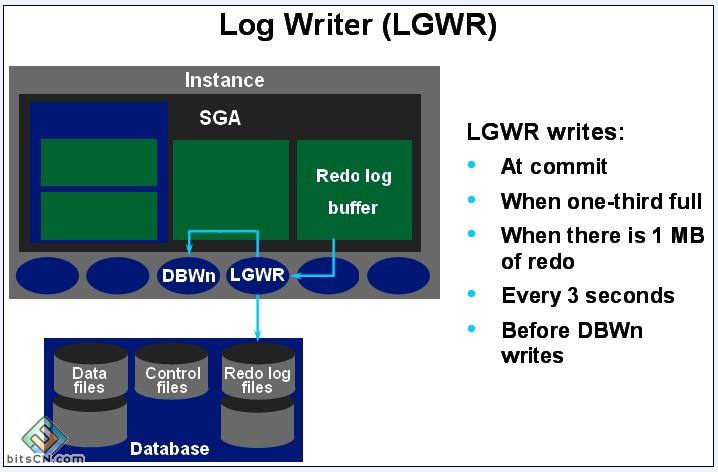
3-2-2:LGWR(Log Writer,日志写入进程)
将日志数据从日志缓冲区写入磁盘日志文件组。数据库在运行时,如果对数据库进行修改则产生日志信息,日志信息首先产生于日志缓冲区。当日志达到一定数量时,由LGWR将将日志数据写入到日志文件组,再经过日志切换,由归档进程(ARCH)将日志数据写入归档进程(前提是数据库运行在归档模式下)。数据库遵循写日志优先原则,即在写数据之前先写日志。
简单介绍
Oracle数据库有两种运行模式,归档(ARCHIVELOG),非归档(NOARCHIVELOG)模式。
以非归档模式运行时日志在切换时被直接覆盖,不产生归档日志,这是数据库默认的运行模式。数据库运行在归档模式时,在日志切换之前,由ARCH进程将日志信息写入磁盘,也就是自动备份在线日志。
Oracle数据库的Redo文件数量是有限的,所以Oracle以循环的方式向它们中写入。它顺序写满每一个Redo文件,当达到最后一个时,再循环回去开始填写第一个Redo文件。如果为了能恢复数据库而想保存日志文件,那么在它们被重新使用之前需要对其进行备份,归档进程管理此工作。
运行CKPT时,系统对全部数据文件及控制文件文件头的同步信号进行修改,以保证数据库的同步。检查点出现在以下情况:
|--在每个日志切换时产生。
|--上一个检验点之后又经过了指定时间。
|--从上一个检验点之后,当预定义数量的日志块被写入磁盘之后。
|--数据库关闭。
|--DBA强制产生。
|--当表空间设置为OFFLINE时。
