【IT168技术分析评论】
摘要:本文分为三部分,主要站在oracle案例库角度来进行阐述,分别介绍oracle案例库的背景,实现思路和方法,并最后给出结论。
1. 背景概述
在企业数据库的生命周期过程中,会面临各种各样的问题,可以说,oracle数据库从摇篮到坟墓,会或多或少的遇到问题,或者潜在问题。问题千奇百怪,有的问题很简单,一眼便知道解决办法,有的问题很复杂,有的问题解决起来很危险,有的问题解决过程中不会有什么危险性。同样的问题可能会再次或者多次碰见,如果时间间隔很长,可能会忘记以前是怎么处理的。
Oracle有时候是一个非常命令精确型,诸多步骤中,可能一步也不允许出差错,否则功亏一篑,甚至带来风险。对于复杂的处理过程、步骤,作为宝贵的经验,应该加以和整理加工,作为典型案例,存储下来。
在现实工作中,我们中使用oracle数据库的时候,经常面临下属问题:
? 印象中碰到过这个问题,但是时间长了,我不知道放哪里了?
? 我知道如果我要努力的找一下,我会找到答案,但是现在时间来不及了。
? 一些问题重复出现,很多时候重复的操作使我很烦。
? 由于当时过于兴奋,忘记了记录一个重要问题的分析解决过程。
? 当时认为很简单的问题,一段时间后,始终想不起当初是怎么解决的。
? 等等。
案例作为个人和企业的宝贵财富,是实际的经验,这些既可以作为以后的培训教材,更是自己以后解决问题的宝贵经验,如果不对他们进行加工,实际上就是对经验的浪费。不懂得如何加工,就是你守着一堆宝,却浑然不知,懂得如何加工,就会变废为宝,或者让他们闪闪发光。这正是oracle服务型公司建立案例知识库的背景。
2. 实现思路
要实现oracle案例知识库,需要进行信息收集、整理、后处理以及提供查询等。
2.1 信息收集
需要考虑几个问题:
? 使用什么工具进行收集。
? 收集那些必要信息。
2.2信息整理
在信息收集的基础上,需要对信息进行加工。信息的加工,主要是将初次收集的信息进行整理,校验,格式化,润色等,使得条理性和可读性以及可操作性、可查询性增强,从而使得信息由零碎的文字描述或者混乱的代码、脚本,变成便于阅读、便于查询、可操作性好的素材。
一旦完成上述操作,案例将会作为次级素材,作为以后其他处理的基本材料,随时从库存中提取。
2.3信息的后处理
这里的处理,指发挥案例库的用途的途径和方法。
可以简单的总结如下:
? 解决问题的有力参考
? 学习训练的培训教材
? 在商业上可以提高企业的形象,能更好的满足客户对于历史知识的查询和借鉴。
实现上述目的的主要途径,就是建立知识库后,对知识库进行充分、及时有效的挖掘,达到信息充分共享和利用的目的,从而发挥效益。
2.4信息查询
查询信息,实际上是案例库产生和发挥作用的地方。一般情况,应该提供多一些的查询方式,比如分类查询方式,关键字查询的方式,每种方式相互补充,尽可能的在有限时间内,查询到对解决当前问题有用的案例,从而启发或者指导问题的解决。
【内容简介】
本书介绍了人类在一个奋斗领域中的创造性和灵活性:计算机系统的开发领域。在每章中的漂亮代码都是来自独特解决方案的发现,而这种发现是来源于作者超越既定边界的远见卓识,并且识别出被多数人忽视的需求以及找出令人叹为观止的问题解决方案。
本书33章,有38位作者,每位作者贡献一章。每位作者都将自己心目中对于“美丽的代码”的认识浓缩在一章当中,张力十足。38位大牛,每个人对代码之美都有自己独特的认识,现在一览无余的放在一起,对于热爱程序的每个人都不啻一场盛宴。 虽然本书的涉猎范围很广,但也只能代表一小部分在这个软件开发这个最令人兴奋领域所发生的事情。
【编辑推荐】
38位大师级的程序员,一步步讲解他们的项目架构,开发时的种种折中考虑(tradeoffs)以及何时必须打破常规,寻求突破。
全球38位顶尖高手、众多语言之父经典之作。
本书收录的是软件设计领域中的一组大师级作品。每一章都是由一位或几位著名程序员针对某个问题给出的完美的解决方案,并且细述了这些解决方案的巧妙之处。
本书既不是一本关于设计模式的书,也不是一本关于软件工程的书,它告诉你的不仅仅是一些正确的方式或者错误的方式。它让你站在那些优秀软件设计师的肩膀上,从他们的角度来看待问题。
本书给出了38位大师级程序员在项目设计中的思路、在开发工作中的权衡,以及一些打破成规的决策。
【作译者介绍】
本书提供作译者介绍
全球38位顶尖高手、众多语言之父经典之作
.. <<
【目录信息】
第1章 正则表达式匹配器
1.1 编程实践
1.2 实现
1.3 讨论
1.4 其他的方法
1.5 构建
1.6 小结
第2章 Subversion中的增量编辑器:像本体一样的接口
2.1 版本控制与目录树的转换
2.2 表达目录树的差异
2.3 增量编辑器接口
2.4 但这是不是艺术?
2.5 像体育比赛一样的抽象
2.6 结论
第3章 我从未编写过的最漂亮代码
3.1 我编写过的最漂亮代码
3.2事倍功半
3.3 观点
3.4 本章的中心思想是什么?
<<
【译者序】
去年8月份,我正在为自己的第—篇国际会议论文热身,机械工业出版社华章分社的陈冀康先生把《Beautiful Code》的电子版发给我,问我能否接下这本书的翻泽工作。在粗略阅读之后,我的第一个感觉就是这本书绝对是一本“重量级”的好书,这一点从各个章节作者的名气就可以看出来,未鹏在之前已经解释得比较清楚了。第二个感觉就是这本书凭借个人力量是难以完成的,书中的每一章节都涉及某个领域中较深的研究主题,如果没有相关的知识,很堆把作者意图完整无误地表达出来。于是,我建议冀康征集一些有实力的译者或者有经验的开发人员,组成一个团队来完成这本书的翻译工作。.
然而,团队的组建并不顺利。冀康在一..
<<
【前言】
《Beautiful Code》是由Greg Wilson在2006年构思的,本书的初衷是希望从优秀的软件开发人员和计算机科学家中提炼出一些有价值的思想。他与助理编辑Andy Oram一起走访了世界各地不同技术背景的专家。.
本书章节内容的组织
第1章,正则表达式匹配器,作者Brian Kernighan,介绍了对一种语言和一个问题的深入分析以及由此产生的简洁而优雅的解决方案。
第2章,Subversion中的增量编辑器:像本体一样的接口,作者Karl Fogel,首先介绍了一个精心设计的抽象,然后证明了这种抽象能够在系统将来的开发中带来一致性。
第3章,我编写过的最漂亮代码,作者Jon Bentley,介绍了如何在无需执行函数的..
<<
【序言】
我在1982年夏天获得了第一份程序员工作。在我工作了两个星期后,一位系统管理员借给了我两本书:Kernighan和Plauger编写的《The Elements of Programming Style》(McGraw—Hill出版社)和Wirth编写的《Algorithms+Data Structures=Programs》(Prentice Hall出版社)。这两本书让我大开眼界——我第一次发现程序并不仅仅只是一组计算机执行的指令。它们可以像做工优良的橱柜一样精致,像悬索吊桥一样漂亮,或者像George Orwell的散文一样优美。.
自从那个夏天以来,我经常听到人们感叹我们的教育并没有教会学生看到这一点。建筑师们需要观摩建筑物,作曲家们需要研习他人的作品,而程序员——他们只有在需要修改..
<<
【媒体评论】
重新擦亮思考的火花
《代码之美》这本书已经成为经典。关于它本身的赞美之辞已经不少了,不过到底从这本书里该读些什么东西,我倒是有些思考。
上世纪九十年代初期,当时正在加州大学埃尔文分校攻读博士学位的Douglas Schmidt在观察了他所参与的软件项目开发实践之后,得出一个结论,即未来的软件开发将越来越多地体现为整合(integration),而不是传统意义上的编程(programming)。换言之,被称为 “软件开发者” 的这个人群,将越来越明显地分化:一部分人开发核心构件和基础平台,而更多地人将主要是配置和整合现有构件以满足客户的需求,类似现代汽车、机床和家用电器制造业的产业格局即将到来。面对这一前景,博士生Schmidt一方面写文章对于其进步意义大加赞扬,另一方面毫不犹豫地投入到核心构件及平台的开发阵营中去。他很清楚,在这样一种分工体系中,由于软件整合产业很难出现垄断局面,因此大多数利润总是被截留在上游,人当然要往高处走,整合是好事,但他老兄宁可让别人来做这个好事。
事实上,软件产业中大多数看上去挺靠谱的预测都被历史的发展无情地抛到垃圾堆里了,然而Schmidt博士生的这个预测却惊人的准确,其后十几年软件工业的发展完美地印证了他当年的判断。因此,他本人基于这一预测所选择的人生道路也一帆风顺。如今已经是教授的Douglas Schmidt先后创造了ACE、TAO、CIAO等一系列分布式计算基础件,先后主导了美国学界和国防领域内若干重大科研与实际开发项目,称为世人公认的分布式计算架构领导者。
抛开他个人的辉煌不说,“整合化”趋势实际上已经深刻地改变了世界软件工业的面貌,从而也影响了身为晚进者的我们的命运。如今大部分的程序员实际上是在整合与配置现有资源以满足需求,而不是真正意义上的“编程”。这当然是一件好事,整合同样需要深刻的洞察力和创新精神,优秀的整合者与天才的程序员一样不可多得,甚至更加罕见。然而我们也不能不承认,大多数整合性的工作是机械的,简单的,重复的,欠缺创意的,深入的思考往往不必要。因此,在这个整合为王的时代里,思考的精神在钝化。更有甚者,互联网和搜索引擎的出现大大加速了这种钝化,几乎所有的问题都有人解决并且张贴在互联网上了,因此独自思考和解决问题已经成了不必要的、降低效率的行为,不但不时髦,而且不经济。软件开发迅速成为一个强调搜索和短期记忆力的技能,我想这是50年前第一代程序员们做梦也没有想到的。
老实讲,就整体而言,我仍然认为这是一种进步。任何一个产业的成熟,无不伴随着分工的明晰、技能的简化和从业门槛的降低。与少数人享受思考乐趣的需求相比,大多数人享受便宜而无处不在的软件服务的需求显然远为重要。但是,对于身处软件行业中的个体来说,思考力的削弱和丧失却是不折不扣的悲剧。这一点不必过多解释,正在苦苦寻找自己核心竞争力的开发者们都知道我说的是什么意思。几年来对中国开发者社群的近距离观察使我确信,尽管作为一个产业,中国软件一直享受着比较快的成长,但是总体而言,中国的软件开发者越来越迷惘、焦躁和不自信。这一情况当然是由多种原因导致的,但开发者们每念及此,多抱怨体制、产业、市场等身外之物,实在也有失偏颇。评心而论,这几年中国软件技术界的生存环境还是有了很大改善,对于那些真正出类拔萃的程序员来说,过上一种充实自信的生活并不困难。摆在每一个个体面前的主要问题还是在于能否出类拔萃,而这就需要我们重新找回思考的能力。具备强悍思考能力的人,也就具备强悍的解决问题的能力,而这样的开发者永远都是产业中的稀缺资源。
我认为这正是《代码之美》这本书的一个重要价值。合作的诸位大师级作者,给我们一个很好的机会,让我们能够一边阅读,一边思考,找回深思熟虑的智慧火花。这本书里所讲的每一个问题,可以说都是程序员在工作中会遇到或者至少会擦边的问题,既没有故弄玄虚的文字游戏,也没有携带了领域知识的私货,只有朴实而实际的一个个问题。虽然不是以提问的方式给出,但在整个阅读的过程中,我们还是能够找到很多机会与大师互动,不断地发现问题和解决问题。我在阅读中经常感到,看上去一个很简单的问题,却被这些大师们一层一层挖掘的如此深入,到最后阶段不由得令人感到战栗和震撼。看着这些智慧的光芒,我们不但可以领略大师之所谓称为大师的秘密,而且也认识到思考的真谛。因此,千万不要想看小说一样一带而过,那样会错过本书95%的价值!我们不是要阅读这些文字,而是要与文字背后的作者交流学习,一点一点把自己的心得记下来,对于作者提出的新问题,先自己思考,直接写程序尝试,争取跟上大师的思路,甚至可能需要反复几遍,才能真正读通这本书。这样的精力不会是白费的,读者应当认识到,当我们拥有这本书的时候,我们获得了怎样宝贵的机会,可以在相对比较短的时间里有效地提升自己的思考能力。这是一个机会,也是一次考验,我绝对相信,通过了这次考验的读者,会在思考和解决问题的能力上有一个大的进步。
我希望自己能够以这样的态度读这本了不起的书,以此文与其他读者朋友共勉之。
——孟岩
【书摘】
第3章 我从未编写过的最漂亮的代码
Jon Bentley
我曾经听一位大师级的程序员这样称赞到,“我通过删除代码来实现功能的提升。”而法国著名作家兼飞行家Antoine de Saint-Exupéry的说法则更具代表性,“只有在不仅没有任何功能可以添加,而且也没有任何功能可以删除的情况下,设计师才能够认为自己的工作已臻完美。” 某些时候,在软件中根本就不存在最漂亮的代码,最漂亮的函数,或者最漂亮的程序。
当然,我们很难对不存在的事物进行讨论。本章将对经典Quicksort(快速排序)算法的运行时间进行全面的分析,并试图通过这个分析来说明上述观点。在第一节中,我将首先根据我自己的观点来回顾一下Quicksort,并为后面的内容打下基础。第二节的内容将是本章的重点部分。我们将首先在程序中增加一个计数器,然后通过不断地修改,从而使程序的代码变得越来越短,但程序的功能却会变得越来越强,最终的结果是只需要几行代码就可以使算法的运行时间达到平均水平。在第三节将对前面的技术进行小结,并对二分搜索树的运行开销进行简单的分析。最后的两节将给出学完本章得到的一些启示,这将有助于你在今后写出更为优雅的程序。
3.1 我编写过的最漂亮代码
当Greg Wilson最初告诉我本书的编写计划时,我曾自问编写过的最漂亮的代码是什么。这个有趣的问题在我脑海里盘旋了大半天,然后我发现答案其实很简单:Quicksort算法。但遗憾的是,根据不同的表达方式,这个问题有着三种不同的答案。
当我撰写关于分治(divide-and-conquer)算法的论文时,我发现C.A.R. Hoare的Quicksort算法(“Quicksort”,Computer Journal 5)无疑是各种Quicksort算法的鼻祖。这是一种解决基本问题的漂亮算法,可以用优雅的代码实现。我很喜欢这个算法,但我总是无法弄明白算法中最内层的循环。我曾经花两天的时间来调试一个使用了这个循环的复杂程序,并且几年以来,当我需要完成类似的任务时,我会很小心地复制这段代码。虽然这段代码能够解决我所遇到的问题,但我却并没有真正地理解它。
我后来从Nico Lomuto那里学到了一种优雅的划分(partitioning)模式,并且最终编写出了我能够理解,甚至能够证明的Quicksort算法。William Strunk Jr.针对英语所提出的“良好的写作风格即为简练”这条经验同样适用于代码的编写,因此我遵循了他的建议,“省略不必要的字词”(来自《The Elements of Style》一书)。我最终将大约40行左右的代码缩减为十几行的代码。因此,如果要回答“你曾编写过的最漂亮代码是什么?”这个问题,那么我的答案就是:在我编写的《Programming Pearls, Second Edition》(Addison-Wesley)一书中给出的Quichsort算法。在示例3-1中给出了用C语言编写的Quicksort函数。我们在接下来的章节中将进一步地研究和改善这个函数。
【示例】 3-1 Quicksort函数
void quicksort(int l, int u)
{int i, m;
if (l >= u) return;
swap(l, randint(l, u));
m = l;
for (i = l+1; i <= u; i++)
if (x[i] < x[l])
swap(++m, i);
swap(l, m);
quicksort(l, m-1);
quicksort(m+1, u);}
如果函数的调用形式是quicksort(0, n-1),那么这段代码将对一个全局数组x[n]进行排序。函数的两个参数分别是将要进行排序的子数组的下标:l是较低的下标,而u是较高的下标。函数调用swap(i,j)将会交换x〔i〕与x〔j〕这两个元素。第一次交换操作将会按照均匀分布的方式在l和u之间随机地选择一个划分元素。
在《Programming Pearls》一书中包含了对Quicksort算法的详细推导以及正确性证明。在本章的剩余内容中,我将假设读者熟悉在《Programming Pearls》中所给出的Quicksort算法以及在大多数初级算法教科书中所给出的Quicksort算法。
如果你把问题改为“在你编写那些广为应用的代码中,哪一段代码是最漂亮的?”我的答案还是Quicksort算法。在我和M. D. McIlroy一起编写的一篇文章("Engineering a sort function," Software-Practice and Experience, Vol. 23, No. 11)中指出了在原来Unix qsort函数中的一个严重的性能问题。随后,我们开始用C语言编写一个新排序函数库,并且考虑了许多不同的算法,包括合并排序(Merge Sort)和堆排序(Heap Sort)等算法。在比较了Quicksort的几种实现方案后,我们着手创建自己的Quicksort算法。在这篇文章中描述了我们如何设计出一个比这个算法的其他实现要更为清晰,速度更快以及更为健壮的新函数——部分原因是由于这个函数的代码更为短小。Gordon Bell的名言被证明是正确的:“在计算机系统中,那些最廉价,速度最快以及最为可靠的组件是不存在的。”现在,这个函数已经被使用了10多年的时间,并且没有出现任何故障。
考虑到通过缩减代码量所得到的好处,我最后以第三种方式来问自己在本章之初提出的问题。“你没有编写过的最漂亮代码是什么?”。我如何使用非常少的代码来实现大量的功能?答案还是和Quicksort有关,特别是对这个算法的性能分析。我将在下一节给出详细介绍。
哎,看来又是一本靠炒作火起来的书,翻译质量真是不敢恭维,这么好的书又被糟蹋了。刚开始时我只看中文,只是觉得有些话说得不太地道,翻译痕迹重,但也 没有太计较。后来越看越累,于是我把电子版找出来对照着看,越看越伤心,越看越失望。别的不说,我们在第24章中随便挑几处看看。 1.第1段原文:The free lunch is over.[*] We have grown used to the idea that our programs will go faster when we buy a next-generation processor, but that time has passed. While that next-generation chip will have more CPUs, each individual CPU will be no faster than the previous year's model. If we want our programs to run faster, we must learn to write parallel programs.[] 译文:免费午餐已经结束[1]。以往我们习惯于通过购买新一代CPU来加快程序的运行速度,但现在,这样的好时光已经一去不复返了。虽说下一代芯片会带有多 个CPU,但每个单独的CPU的速度却不会再变快了。所以,如果想让程序跑得更快的话,你就必须得学会编写并行程序[2]。 如果不看英文,只会觉得翻译有些别扭。比如“虽说下一代芯片会带有多个CPU,但每个单独的CPU的速度却不会再变快了”这句话,这样说不是更好吗?“虽然 下一代芯片会有多个CPU,但单个CPU的速度却不会再变快了。”如看看了原文,会发现这句话有2处翻译错误。我们再来对照英文看看“We have grown used to the idea that our programs will go faster when we buy a next-generation processor, but that time has passed”这句话,它表面上看不出来太大问题,但是译者完全改变了作者的意思。“We have grown used to the idea that”这个短语译者的理解不到位,译者 翻译为“我们习惯于贩贩贩”,表示后面的动作已经发生了。但是原文中这句话后面有“idea”和“will”,译者把这2个看似不重要的词给去掉了,于是改变了整个 句子的结构。”Processor“就是指CPU吗?如果是这样,那干嘛不都叫process,为什么还要提出”Central Processing Unit“的概念?真搞不懂译者为什么要 把这里的”process“强制翻译为CPU。这段话的第一句翻译为”我们以前习惯性地认为可以通过购买新一代的处理器来提高程序的运行速度,但是这样的时光已 经不再了”是不是更好? 我们再来看看“While that next-generation chip will have more CPUs, each individual CPU will be no faster than the previous year's model”这句话。译者居然把“more”翻译为“多个”,那作者干嘛不用“many”呢?我想作者想表达的应该是“下一代的芯片会有更多的CPU”这层意思,这刚好与现状相符。 “each individual”这是英文的表达习惯,翻译为“每个单独的”不算错,但我认为不符合中文的表达习惯,翻译为“单个的”不是更好吗?这一句翻译为“虽 然下一代芯片会有越来越多的CPU,但是单个CPU的处理速度不会再提高了”会不会更好些呢? 接下来看看第3句:If we want our programs to run faster, we must learn to write parallel programs。译者将“run”翻译为“跑”,虽然不算错,但是不“ 雅”。这句话建议译为:“所示,如果想让程序的运行速度更快,我们就必须学会编写并行程序。” 类似这段话的问题不胜枚举,整本书都存在,这样的翻译质量确实让人有被忽悠了的感觉,哎贩贩贩
(
1条评论--

)
您觉得呢?

(得
6支)

(得
0个)
正在读取本评论的讨论,请稍侯……
 三级评论员
三级评论员


发表于:2008-12-26 9:19:00
《代码之美》应该怎样读我看到有些读者认为《代码之美》讲解了10多种编程语言,我只会使用了1或者2种编程语言,恐怕看不懂。还有些读者认为《代码之美》并没有讲解很多关于代码的事情,也没有发现“美”。 在这里我想谈谈,我对《代码之美》的看法:《代码之美》是一本怎样图书? 在本书第32章开头写道:“作者将要讨论的东西大多数是关于软件的设计和架构,而不是单纯的代码。”所以,不要将《代码之美》看成一本讲解代码或者讲解编程语言的图书。这本书的原意是讲解软件设计及架构,同时,也探讨了通过怎样的设计及架构将项目做得更佳漂亮。本书的精华是展现38位作者遇到问题后,是怎样解决这些问题的。同时,我也发现:代码只是描述这些作者思想的方法。代码的“美”需要慢慢地培养,虽然,目前我做不出“美”,但是我必须要了解什么是“美”,其实,这本书是适合各个层级的程序员看,而且是越是初级的程序员越要看,要知道写出“漂亮”的代码是一种习惯。《代码之美》能带给我什么?我把《代码之美》当成一本休闲的图书来看,没事的时候可以翻看,我知道自己不可能很快的了解内容,也没有关系。我想主要是自己还没有遇到相关的问题,如果哪一天遇到像作者那样的问题,就会与作者产生共鸣想到办法啦。
您觉得呢?
(得
0支)
(得
0个)
正在读取本评论的讨论,请稍侯……
浅析基于oracle案例知识库设计
作者:IT168 hxcqu 2009-01-21
文本Tag:
3. 实现方法
实现oracle案例知识库的方式,不会太复杂。最主要的是素材的分类,关键字提炼,以及内容的组织,有了这些原始素材,将它们存放到数据库中,设计录入和查询的界面。
下图简要说明知识库搭建的示意图:
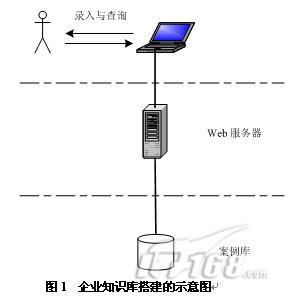
据了解,有些服务型企业现在有这方面的打算,但是效果不是很理想,最关键的原因是,对案例知识库的建设并不重视,或者操作起来并不方便。要想很顺利的推进知识库的建设,下面几个因素是很重要的:
? 有友好的录入界面和用户查询界面。
? 有专门的人员对知识库进行维护,比如录入的格式维护,案例分类,关键字提炼等。
? 有适当的奖惩措施。知识库的建设应该带有半强制性性质,是企业行为,具有约束性效力。
? 对员工进行使用培训。
? 让大家参与使用,并根据实际情形,修改完善,逐步建成适应企业发展的知识资源。
4. 结论
用过metalink的人,一定有非常深刻的印象,metalink是解决问题的非常重要的帮手,metalink产生的效益是巨大的,这也许是oracle能够取得如此辉煌成功的一个重要因素,metalink就是一个强大的知识库。
互联网也可以看作一个知识库,而且有互动的成分在里面,但是,互联网就是信息太复杂,正确和错误俱在,有时候可能会有帮助,有时候可能会有误导。
既然有了这么好的知识库,企业还有必要花费人力财力物力去建立自己的小型知识库吗?当然有必要,因为这些是自己的经验,自己碰到过的问题解决思路,可以根据自己的需要,灵活设计,并且可以为自己特定的目标服务。



