分类: Java
2022-11-09 14:01:05
本质是一种技术债务,产生原因一方面是业务原因:如业务本身场景繁多、流程复杂等;另一方面是技术原因:如代码不规范、设计不合理、祖传代码文档注释缺失等。它会影响我们的程序很多方面:如可读性、可修改性、可复用性、可维护性、可测试性等。
划分为梳理->重构/重写->替换/验证三个阶段
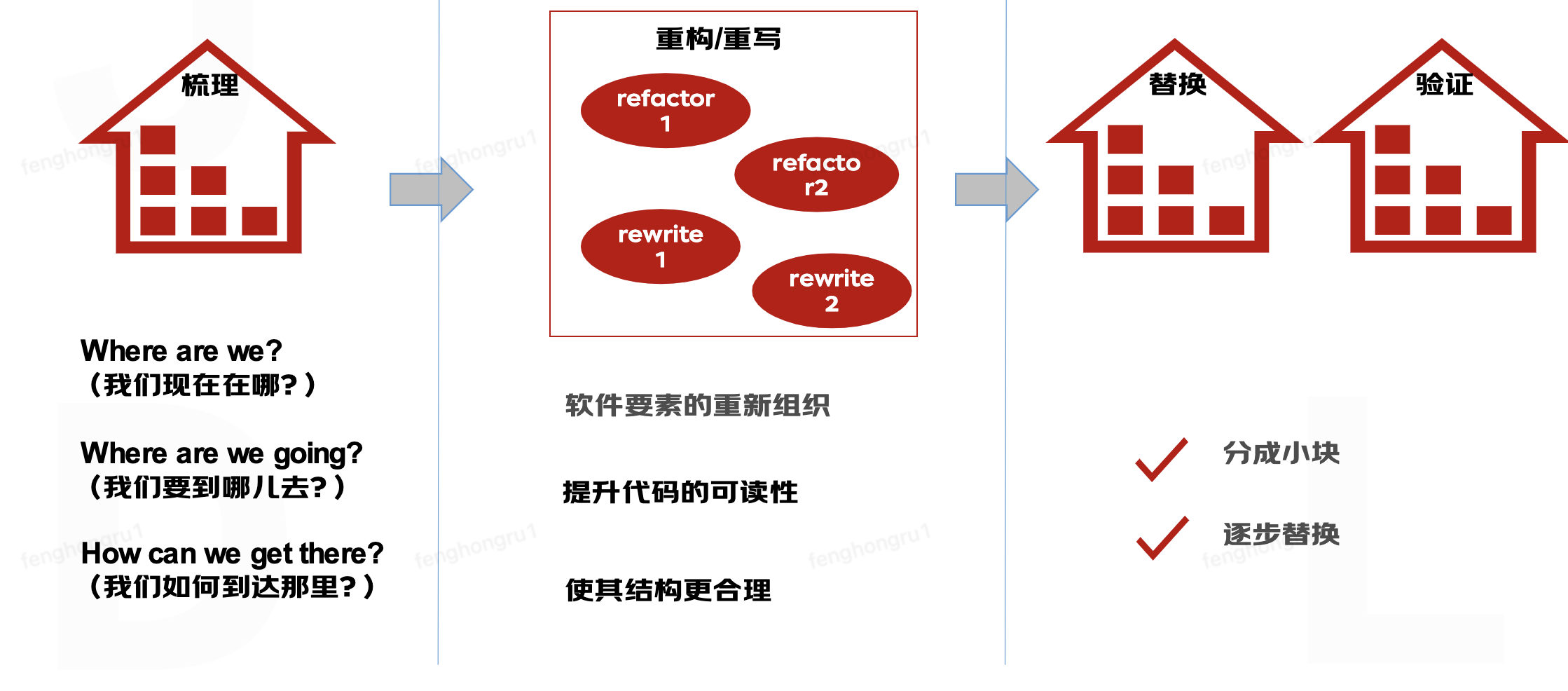
遗留代码的处理是一种逆向工程,从已有的代码+数据模型+文档倒推出业务模型、交互和规则,在保真的前提下再重新构建代码+数据模型+文档。
我们这里可以参考下DDD领域驱动设计里战略设计部分常用的工具(事件风暴法)来进行这部分梳理工作。
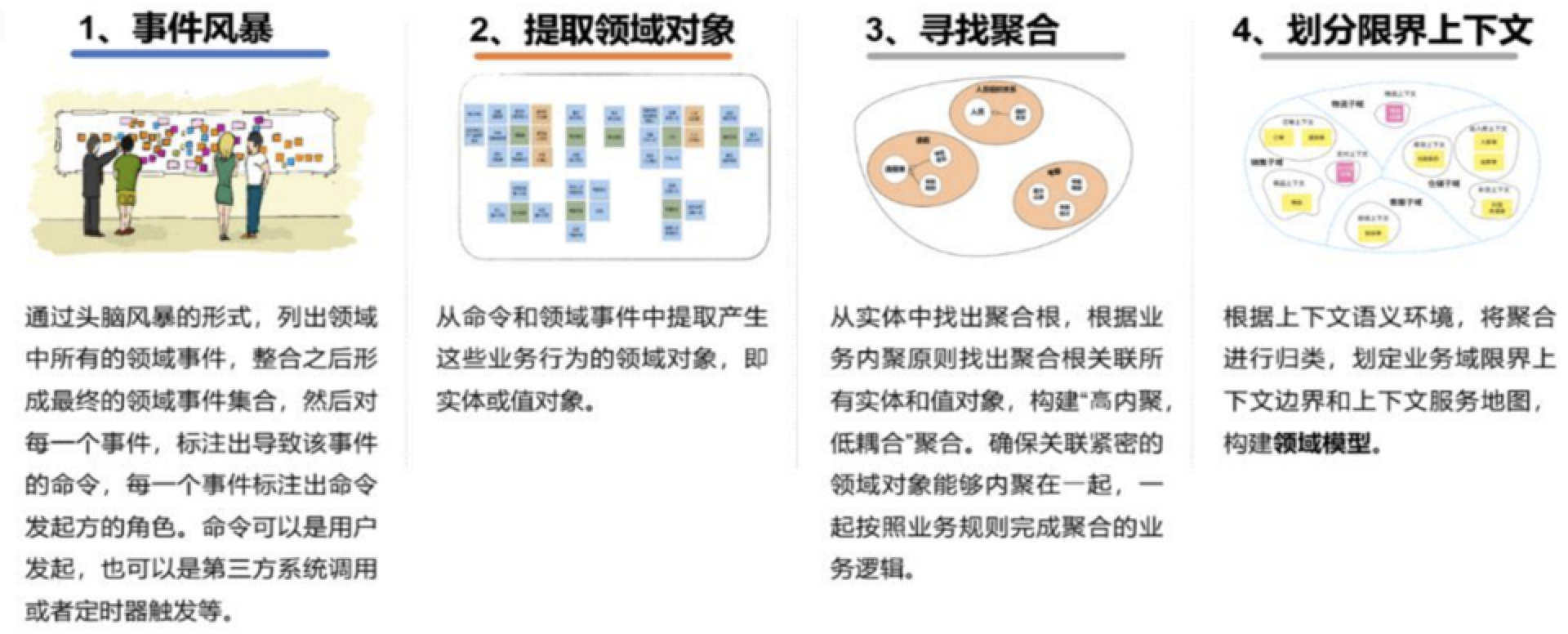
事件风暴本质上是一种系统建模的方法,与它处于对等位置的,会有“UML建模”、“事件驱动建模”等。事件风暴跟敏捷开发里的一些理念(如用户故事)的产生背景类似,都是在理性思考无法应对变化频繁且文字难以描述的情况下,通过一些辅助性的提示卡片、视觉手段,辅以相关人员的集中、高频沟通来完成对于业务的准确把握和抽象建模。
事件风暴的过程:
事件风暴的产物:
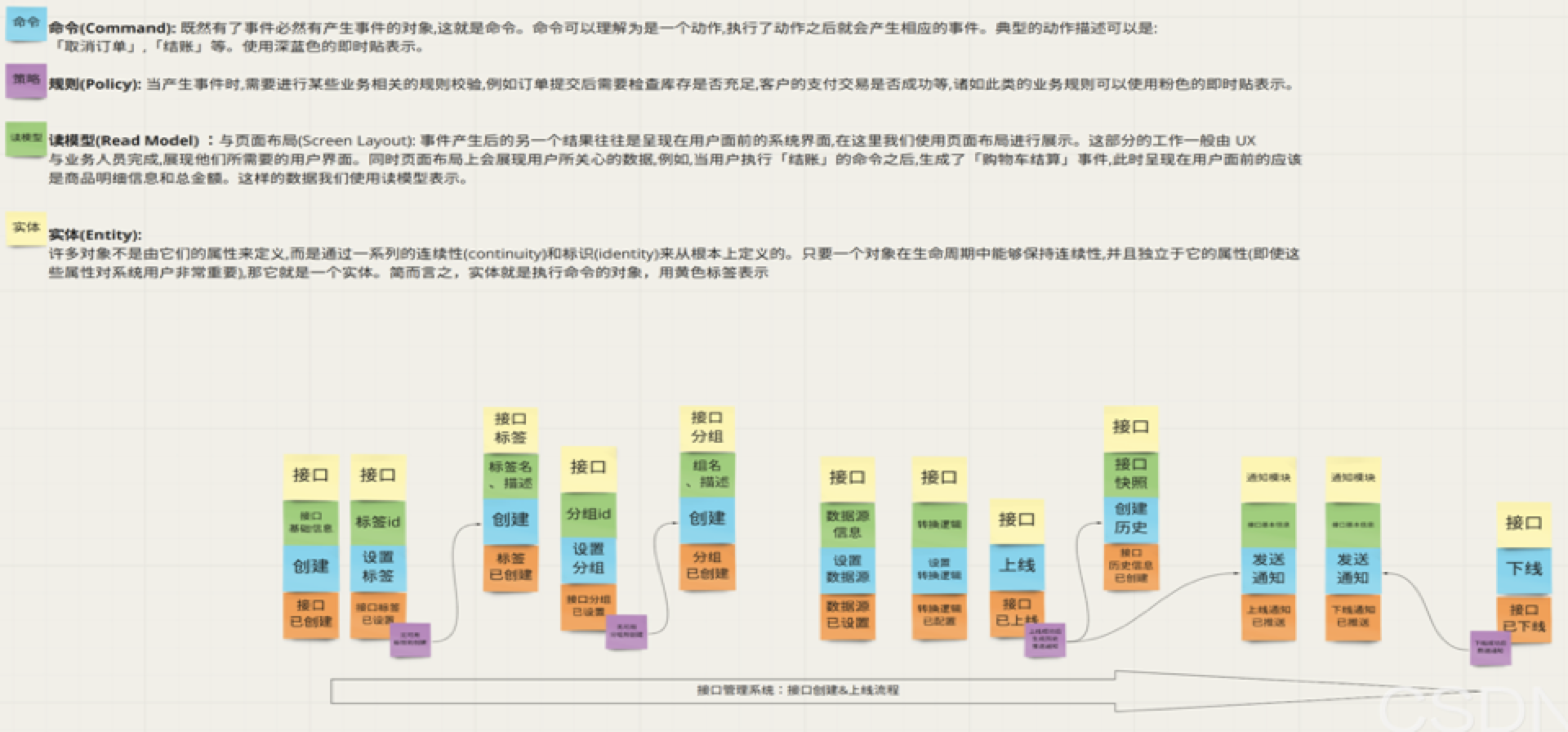
梳理结果示例:
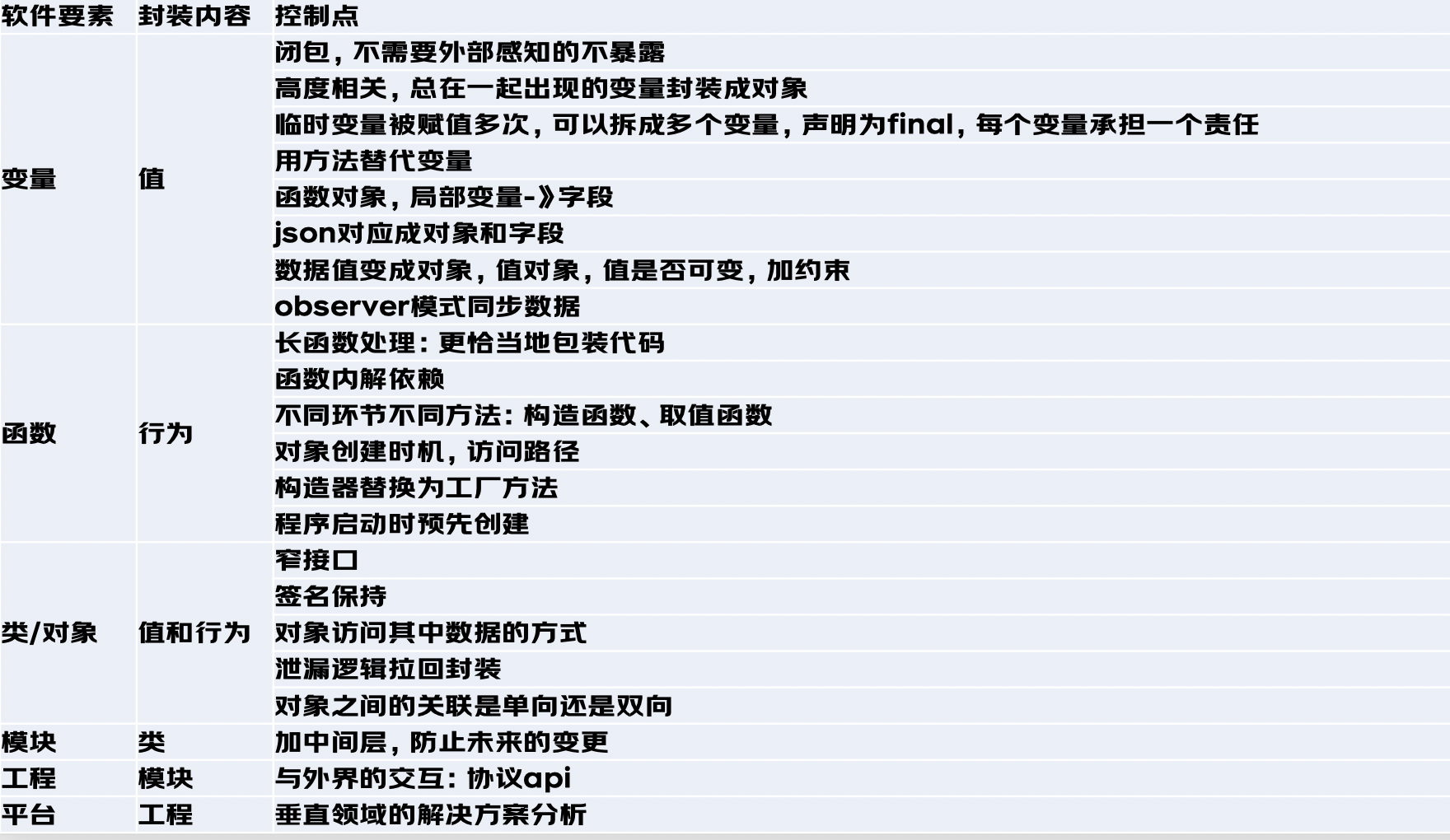
通过重构/重写对软件要素进行重新组织,使其不改变外部行为的情况下,提升代码的可读性或使其结构更合理。

针对不同层次的软件要素要做不同的处理和控制:
并且整个重构/重写过程有些需要遵照的原则:
其中有两点落地细节我们具体分析下:
大概分为以下几个要点:
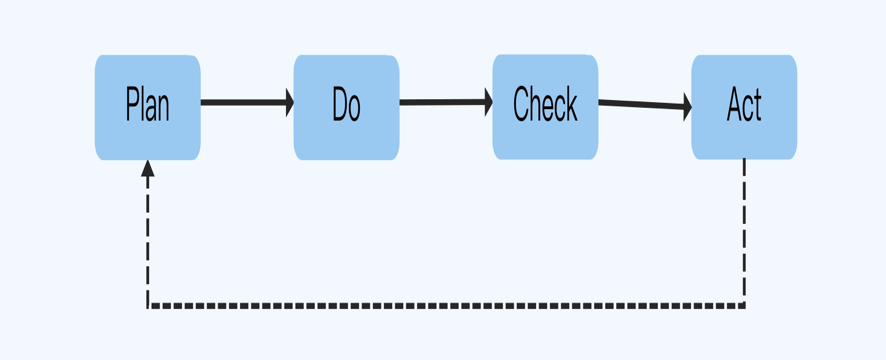
可借助过程管理工具如PDCA法进行管理
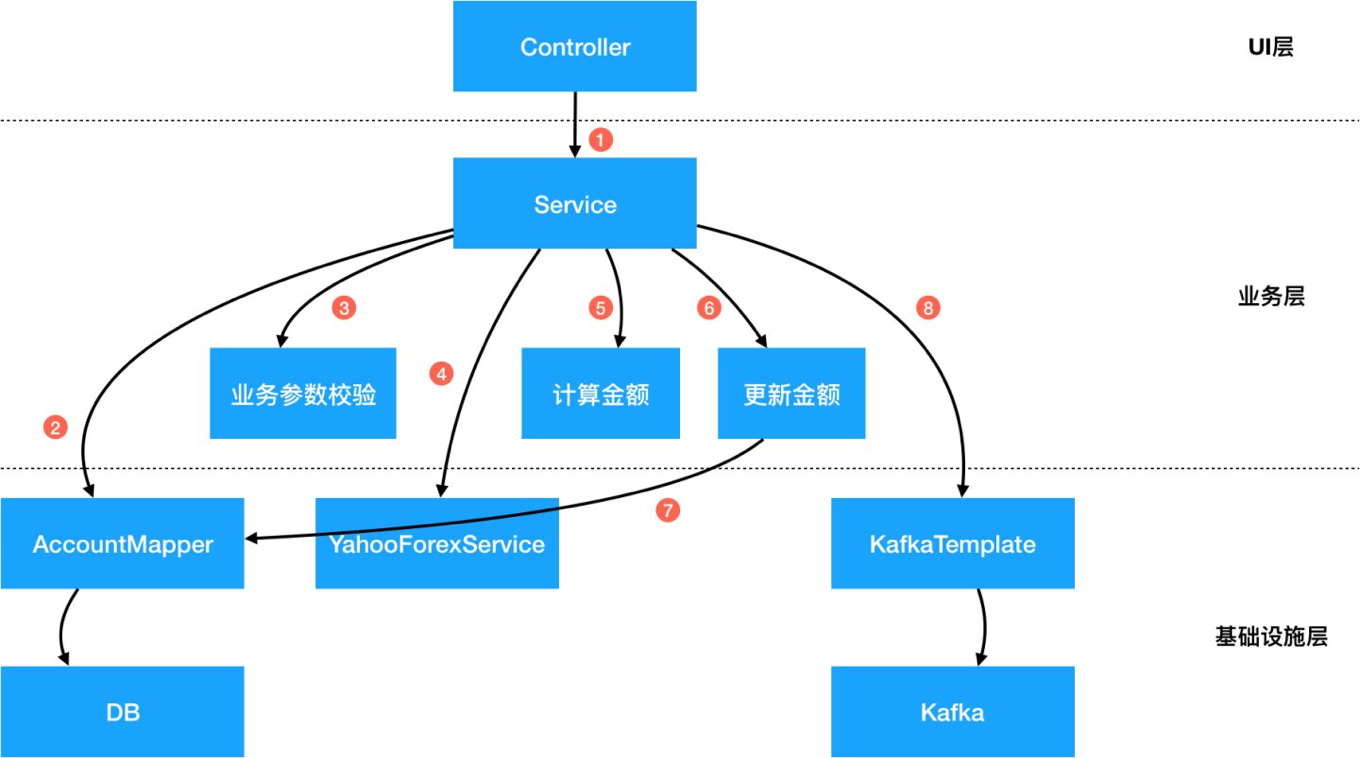
原始需求:案例为一个转账服务,用户可以通过银行网页转账给另一个账号,支持跨币种转账。同时因为监管和对账需求,需要记录本次转账活动。
原始架构:是一个传统的三层分层结构:UI层、业务层、和基础设施层。上层对于下层有直接的依赖关系,导致耦合度过高。在业务层中对于下层的基础设施有强依赖,耦合度高。我们需要对这张图上的每个节点做抽象和整理,来降低对外部依赖的耦合度。
重构关键设计点:

重构后代码特征:
业务逻辑清晰,数据存储和业务逻辑完全分隔。
Entity、Domain Primitive、Domain Service都是独立的对象,没有任何外部依赖,但是却包含了所有核心业务逻辑,可以单独完整测试。
原有的转账服务不再包括任何计算逻辑,仅仅作为组件编排,所有逻辑均delegate到其他组件。
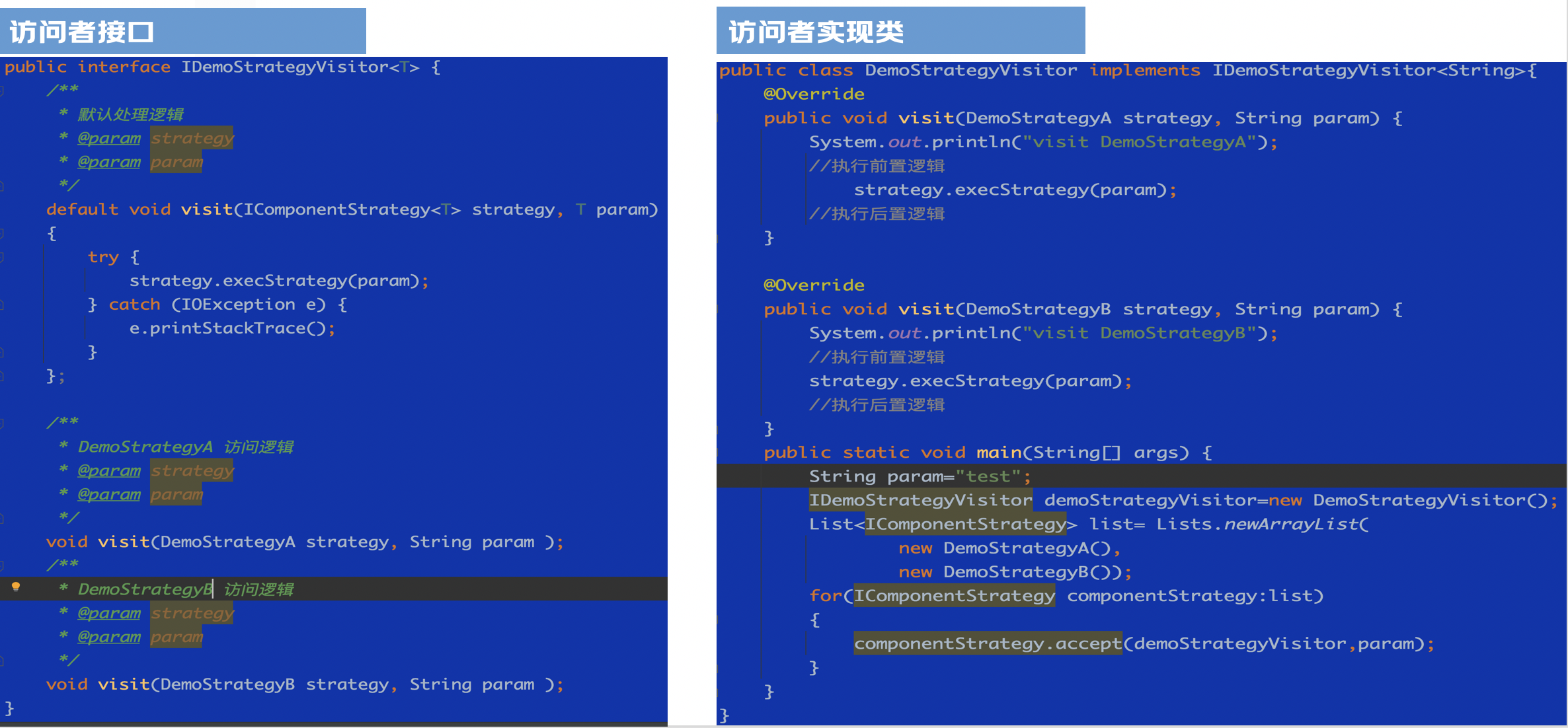
原始需求:现有几个策略实现类,被很多代码使用。现在需要根据不同的业务方在每个策略执行前做不同的前置逻辑处理。
解法分析:尽量避免把逻辑耦合到已有的实现类中。引入外部类进行控制反转。这里我们使用访问者模式。
访问者模式把数据结构和作用于结构上的操作解耦合,使得操作集合可相对自由地演化。访问者模式适用于数据结构相对稳定算法又易变化的系统。因为访问者模式使得算法操作增加变得容易。若系统数据结构对象易于变化,经常有新的数据对象增加进来,则不适合使用访问者模式。访问者模式的优点是增加操作很容易,因为增加操作意味着增加新的访问者。访问者模式将有关行为集中到一个访问者对象中,其改变不影响系统数据结构。其缺点就是增加新的数据结构很困难。
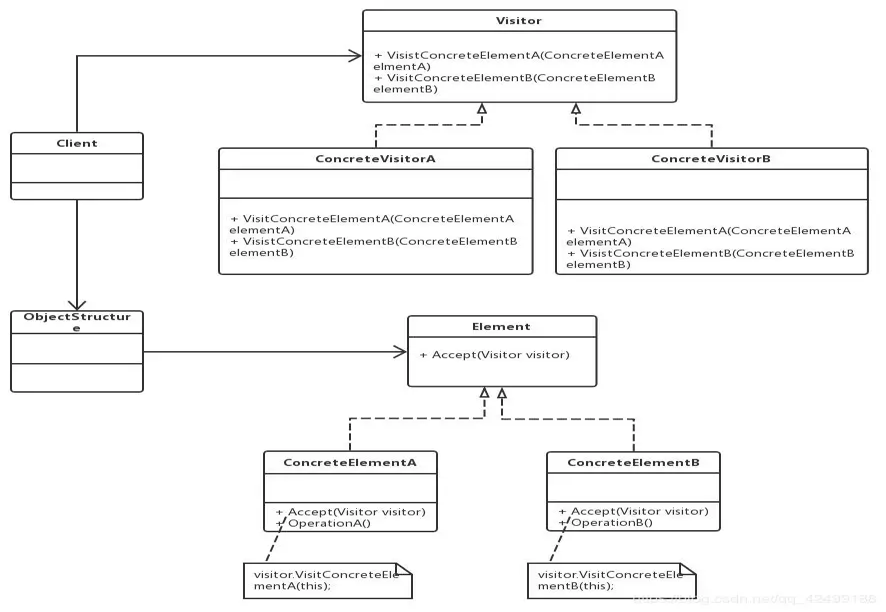
具体实现:
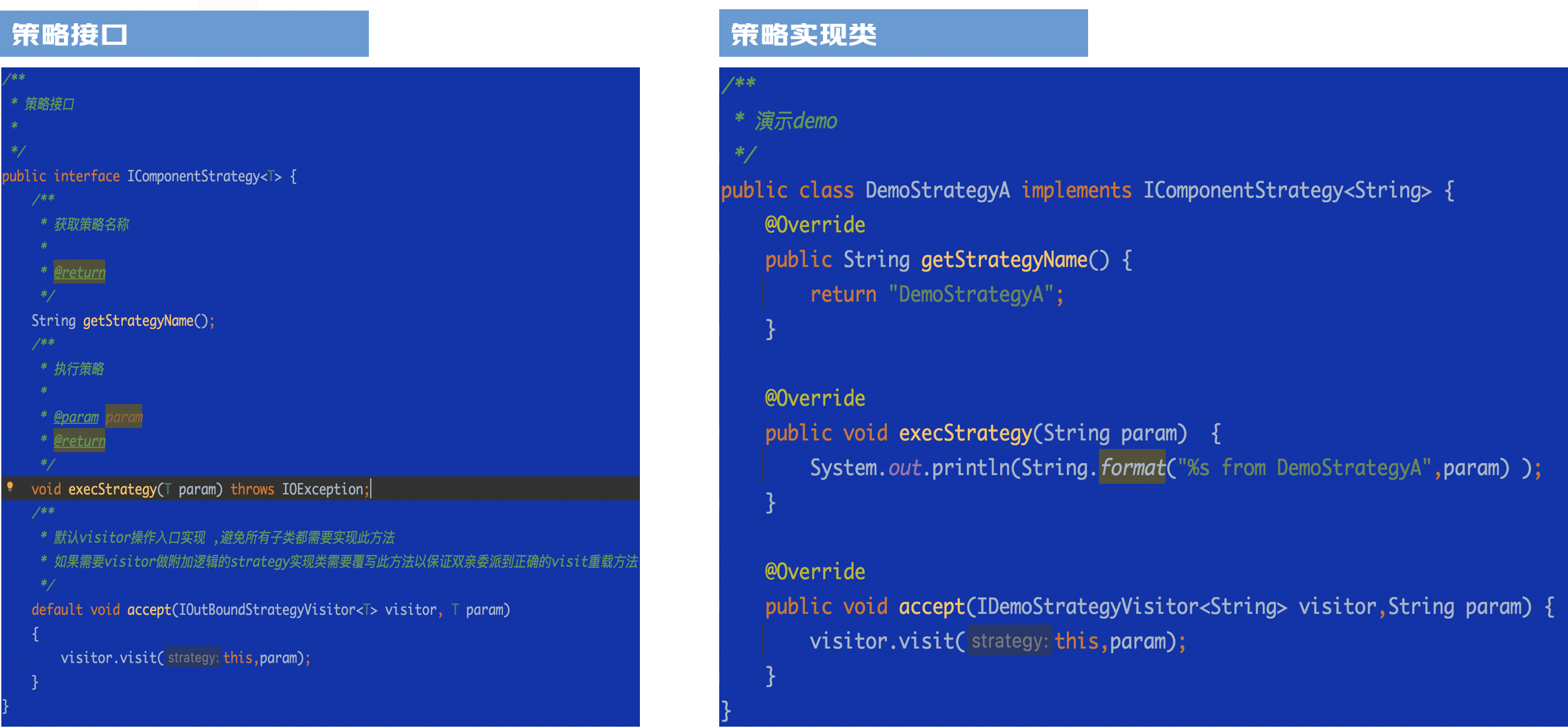
重构后代码特征:
可以通过访问者对老代码逻辑进行编排,将修改外置,减少对老逻辑的影响
通过java8默认接口实现提供默认访问行为,避免大量策略子类的感知,只需要需要提供自己实现行为的子类对默认实现进行覆写
遗留代码的处理能力一方面是对技术的要求,另一方面也是对业务掌握的挑战。希望我们可以跨越荆棘、穿过迷雾,顺利到达成功的彼岸!
