分类: 数据库开发技术
2022-10-09 11:21:44
我们平时会写各种各样或简单或复杂的sql语句,提交后就会得到我们想要的结果集。比如sql语句,”select * from t_user where user_id > 10;”,意在从表t_user中筛选出user_id大于10的所有记录。你有没有想过从一条sql到一个结果集,这中间经历了多少坎坷呢?
从MySQL、Oracle、TiDB、CK,到Hive、HBase、Spark,从关系型数据库到大数据计算引擎,他们大都可以借助SQL引擎,实现“接受一条sql语句然后返回查询结果”的功能。
他们核心的执行逻辑都是一样的,大致可以通过下面的流程来概括:

中间蓝色部分则代表了SQL引擎的基本工作流程,其中的词法分析和语法分析,则可以引申出“抽象语法树”的概念。
高级语言的解析过程都依赖于解析树(Parse Tree),抽象语法树(AST,Abstract Syntax Tree)是忽略了一些解析树包含的一些语法信息,剥离掉一些不重要的细节,它是源代码语法结构的一种抽象表示。以树状的形式表现编程语言的结构,树的每个节点ASTNode都表示源码中的一个结构;AST在不同语言中都有各自的实现。
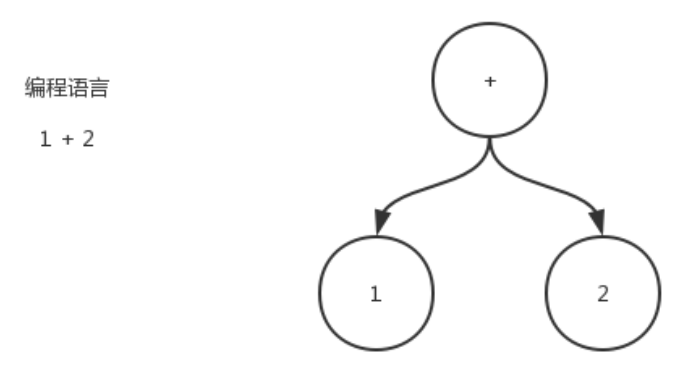
解析的实现过程这里不去深入剖析,重点在于当SQL提交给SQL引擎后,首先会经过词法分析进行“分词”操作,然后利用语法解析器进行语法分析并形成AST。
下图对应的SQL则是“select username,ismale from userInfo where age>20 and level>5 and 1=1”;
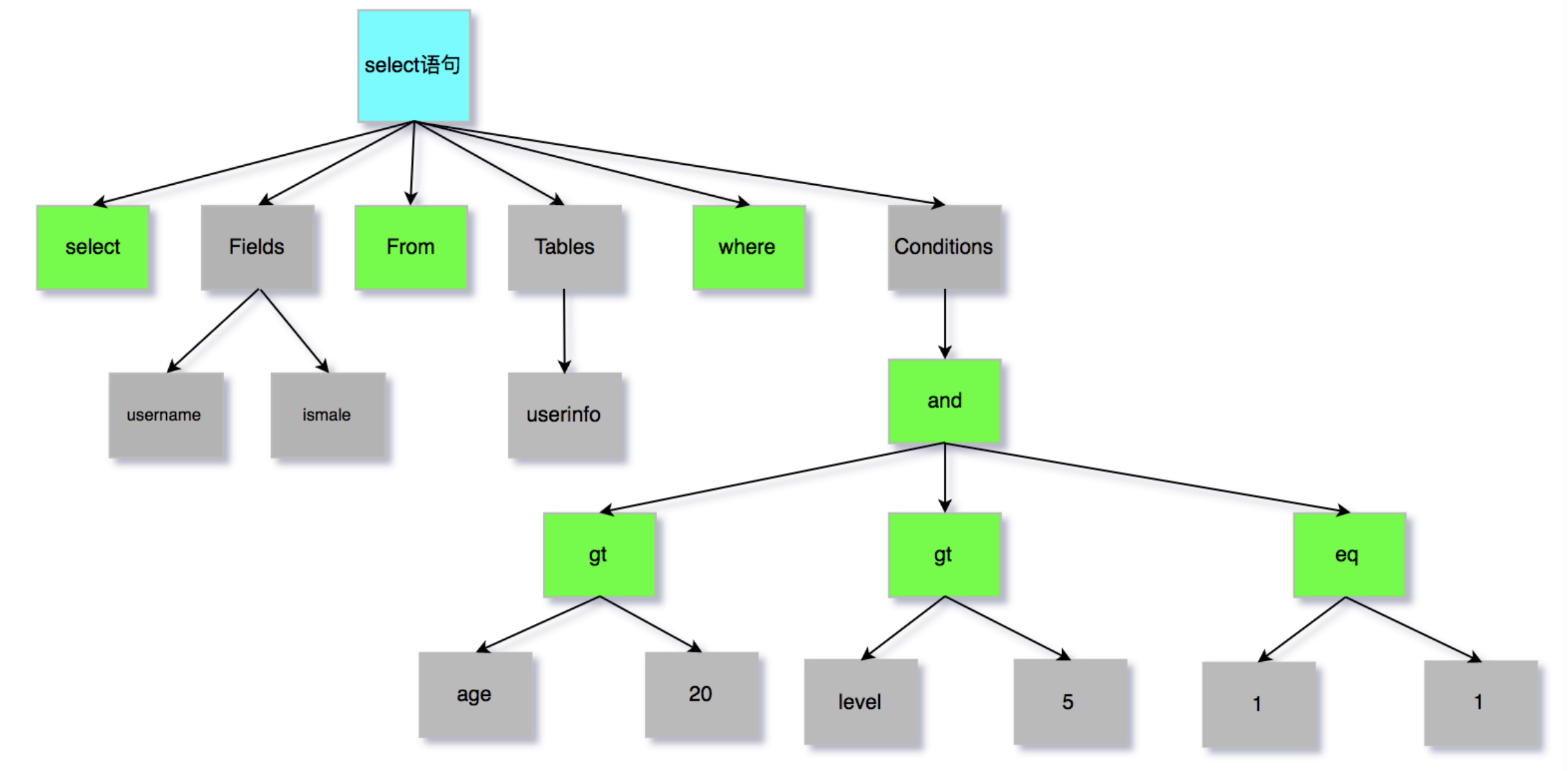
这棵抽象语法树其实就简单的可以理解为逻辑执行计划了,它会经过查询优化器利用一些规则进行逻辑计划的优化,得到一棵优化后的逻辑计划树,我们所熟知的“谓词下推”、“剪枝”等操作其实就是在这个过程中实现的。得到逻辑计划后,会进一步转换成能够真正进行执行的物理计划,例如怎么扫描数据,怎么聚合各个节点的数据等。{BANNED}最佳后就是按照物理计划来一步一步的执行了。
解析(词法和语法)这一步,很多SQL引擎采用的是ANTLR4工具实现的。ANTLR4采用的是构建G4文件,里面通过正则表达式、特定语法结构,来描述目标语法,进而在使用时,依赖语法字典一样的结构,将SQL进行拆解、封装,进而提取需要的内容。下图是一个描述SQL结构的G4文件。
在java中的实现一次SQL解析,获取AST并从中提取出表名。
首先引入依赖:
org.antlr antlr4-runtime 4.7
在IDEA中安装ANTLR4插件;
示例1,解析SQL表名。
使用插件将描述MySQL语法的G4文件,转换为java类(G4文件忽略)。
类的结构如下:
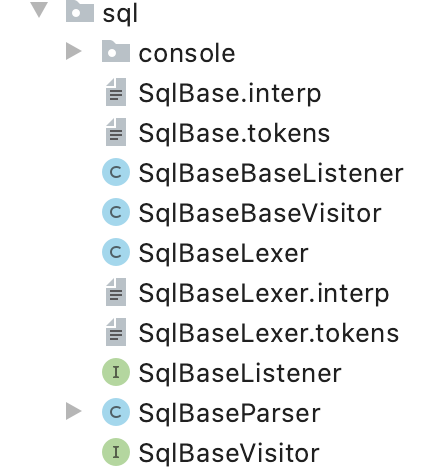
其中SqlBase是G4文件名转换而来,SqlBaseLexer的作用是词法解析,SqlBaseParser是语法解析,由它生成AST对象。HelloVisitor和HelloListener:进行抽象语法树的遍历,一般都会提供这两种模式,Visitor访问者模式和Listener监听器模式。如果想自己定义遍历的逻辑,可以继承这两个接口,实现对应的方法。

读取表名过程,是重写SqlBaseBaseVisitor的几个关键方法,其中TableIdentifierContext是表定义的内容;
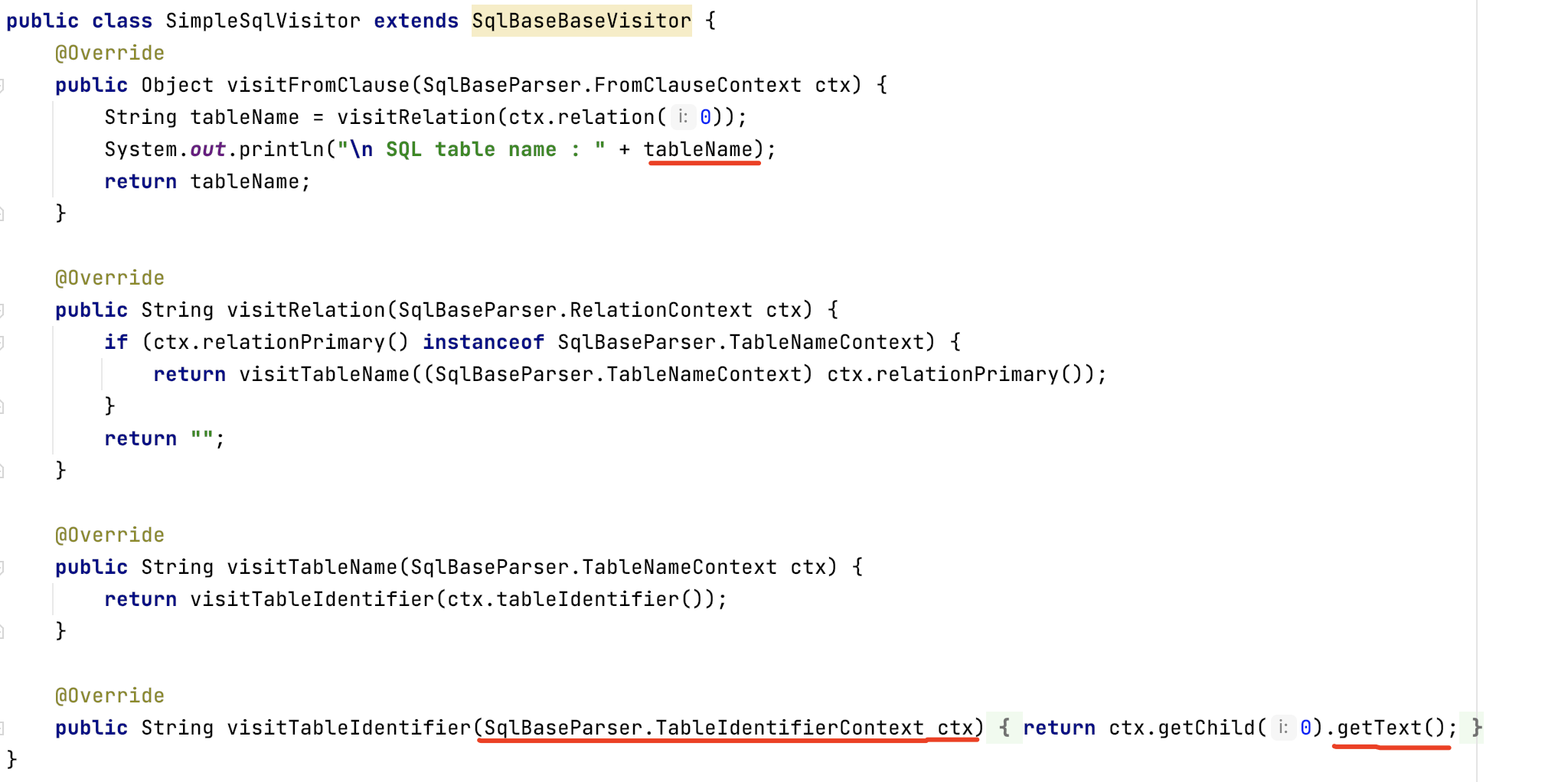
SqlBaseParser下还有SQL其他“词语”的定义,对应的就是G4文件中的各类描述。比如TableIdentifierContext对应的是G4中TableIdentifier的描述。
3.2.2 字符串解析上面的SQL解析过程比较复杂,以一个简单字符串的解析为例,了解一下ANTLR4的逻辑。
1)定义一个字符串的语法:Hello.g4

2)使用IDEA插件,将G4文件解析为java类
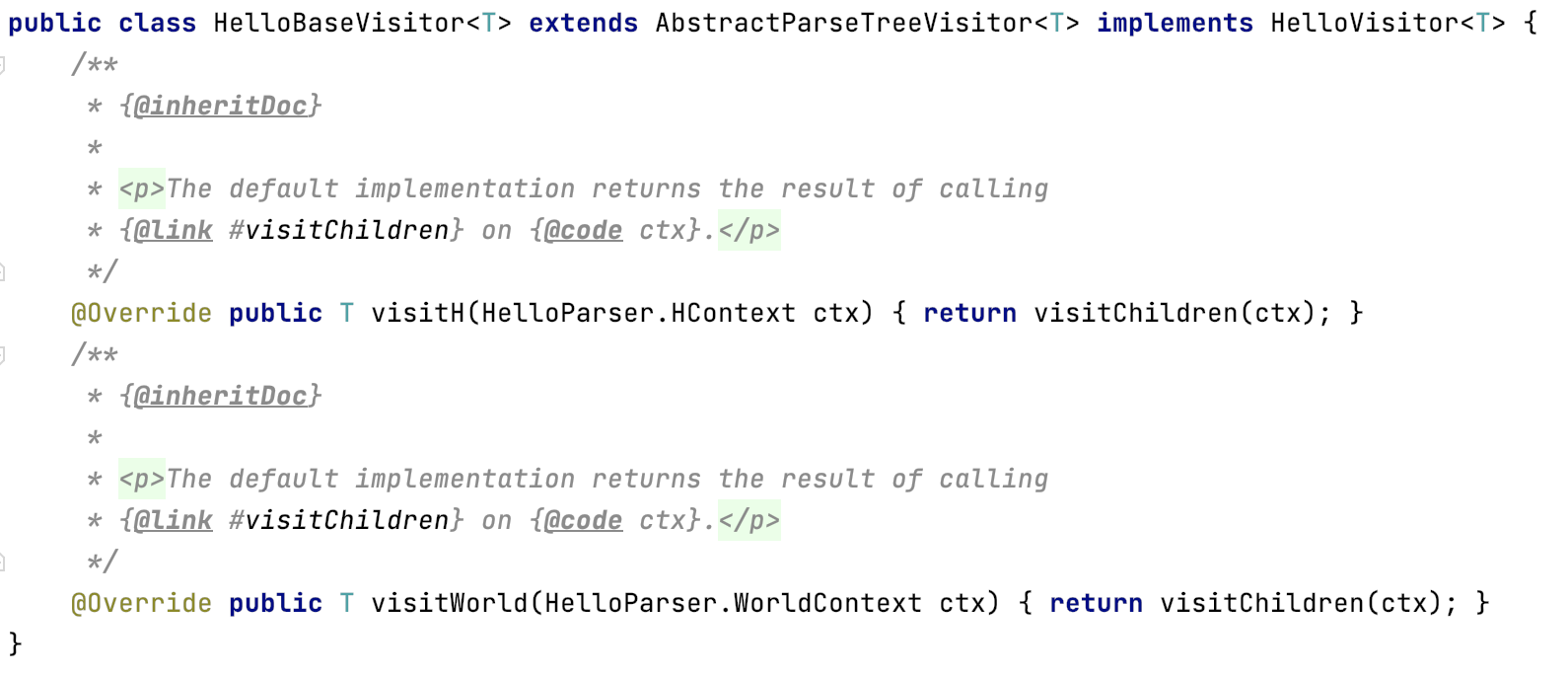
3)语法解析类HelloParser,内容就是我们定义的h和world两个语法规则,里面详细转义了G4文件的内容。

4)HelloBaseVisitor是采用访问者模式,开放出来的接口,需要自行实现,可以获取xxxParser中的规则信息。
5)编写测试类,使用解析器,识别字符串“hi abc”:

6)调试后发现命中规则h,解析为Hi和abc两部分。
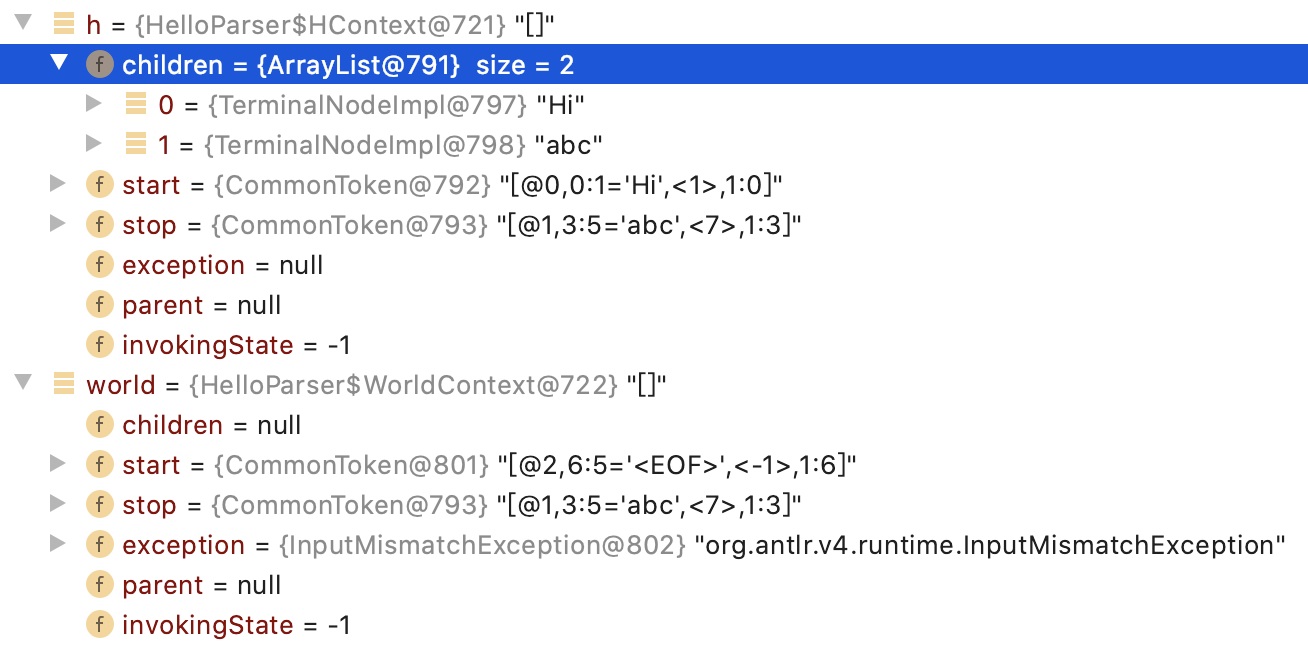
7)如果是SQL的解析,则会一层层的获取到SQL中的各类关键key。
利用ANTLR4进行语法解析,是比较底层的实现,因为Antlr4的结果,只是简单的文法解析,如果要进行更加深入的处理,就需要对Antlr4的结果进行更进一步的处理,以更符合我们的使用习惯。
利用ANTLR4去生成并解析AST的过程,相当于我们在写rpc框架前,先去实现一个netty。因此在工业生产中,会直接采用已有工具来实现解析。
Java生态中较为流行的SQL Parser有以下几种(此处摘自网络):
Apache Sharding Sphere(原当当Sharding-JDBC,在1.5.x版本后自行实现)、Mycat都是国内目前大量使用的开源数据库中间件,这两者都使用了alibaba druid的SQL Parser模块,并且Mycat还开源了他们在选型时的对比分析Mycat路由新解析器选型分析与结果.
当我们拿到AST后,可以做什么?
提到改写SQL,可能{BANNED}中国第一个思路就是在SQL中添加占位符,再进行替换;再或者利用正则匹配关键字,这种方式局限性比较大,而且从安全角度不可取。
基于AST改写SQL,是用SQL字符串生成AST,再对AST的节点进行调整;通过遍历Tree,拿到目标节点,增加或修改节点的子节点,再将AST转换为SQL字符串,完成改写。这是在满足SQL语法的前提下实现的安全改写。
以Druid的SQL Parser模块为例,利用其中的SQLUtils类,实现SQL改写。
4.2.1 新增改写

1)原始SQL

2)实际执行SQL

前面省略了Tree的遍历过程,需要识别诸如join、sub-query等语法

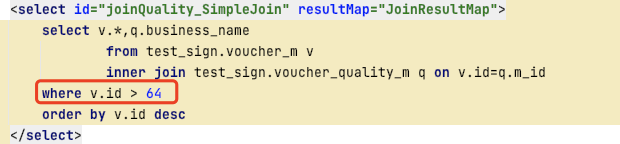
1)简单join查询

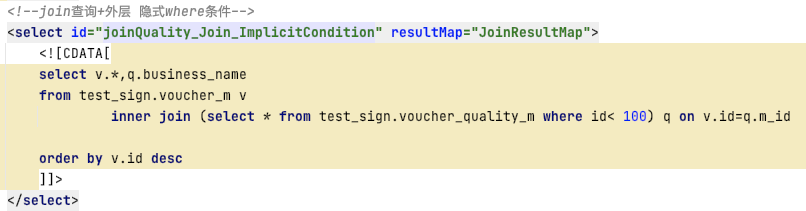
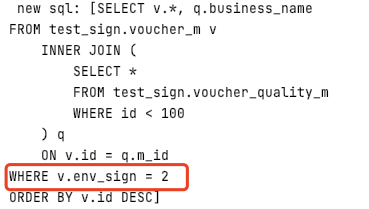
2)join查询+隐式where条件
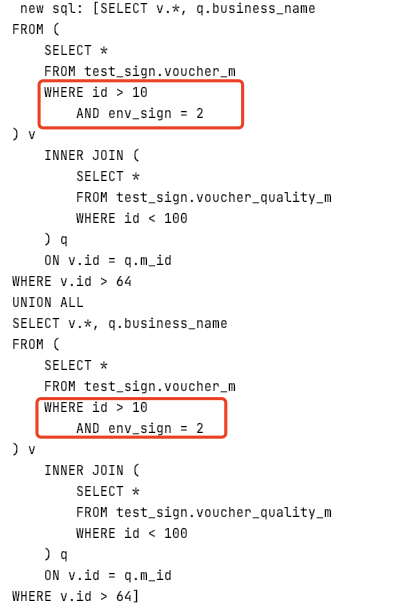
3)union查询+join查询+子查询+显示where条件

本文是基于环境隔离的技术预研过程产生的,其中改写SQL的实现,是数据库在数据隔离上的一种尝试。
可以让开发人员无感知的情况下,以插件形式,在SQL提交到MySQL前实现动态改写,只需要在数据表上增加字段、标识环境差异,后续CRUD的SQL都会自动增加标识字段(flag=’预发’、flag=’生产’),所操作的数据只能是当前应用所在环境的数据。
