全部博文(267)
分类: Python/Ruby
2022-11-23 10:35:43

回到 ASCII 码

ASCII的演化(evolve)
 正在上传…重新上传取消
正在上传…重新上传取消
编码来源

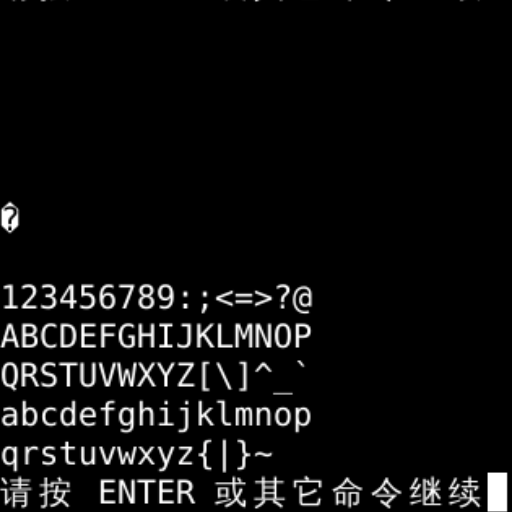
for n in range(0xff):
print(chr(n),end="")
if n % 16 == 0:
print()
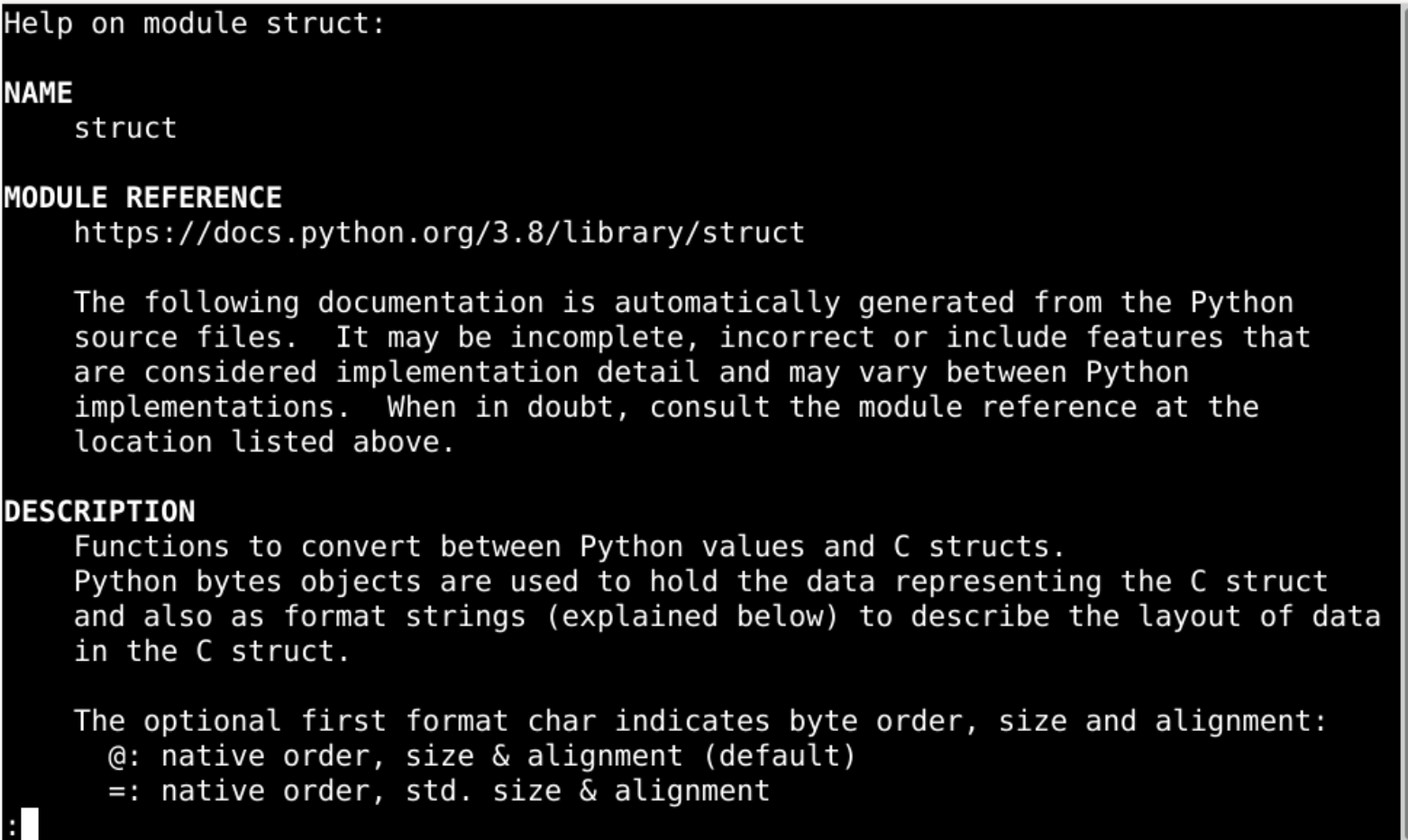
struct
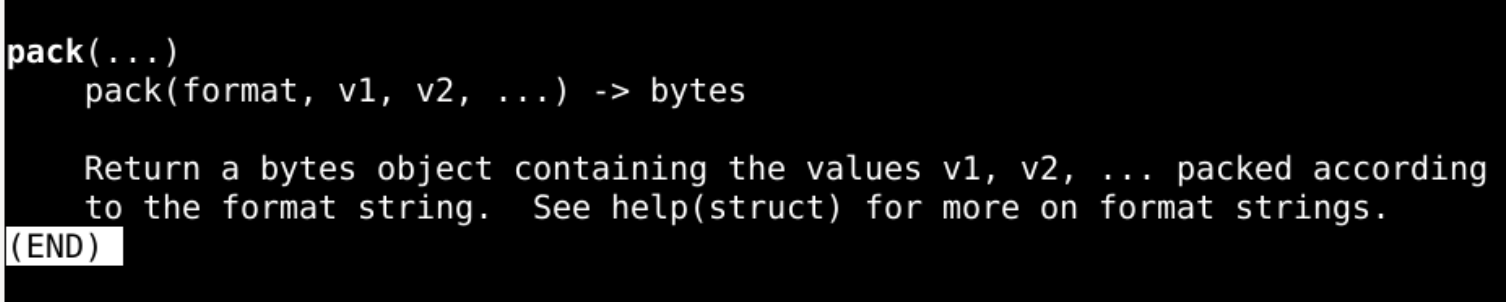
pack
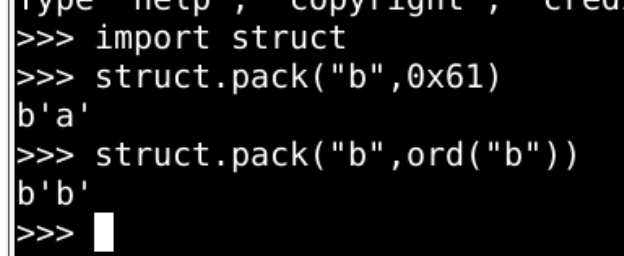
字节表示法
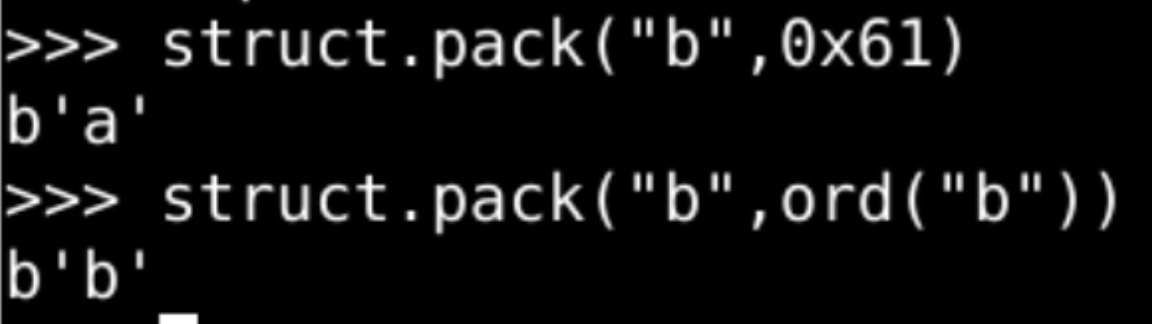
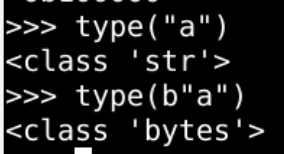
字节形态
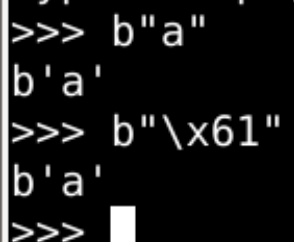
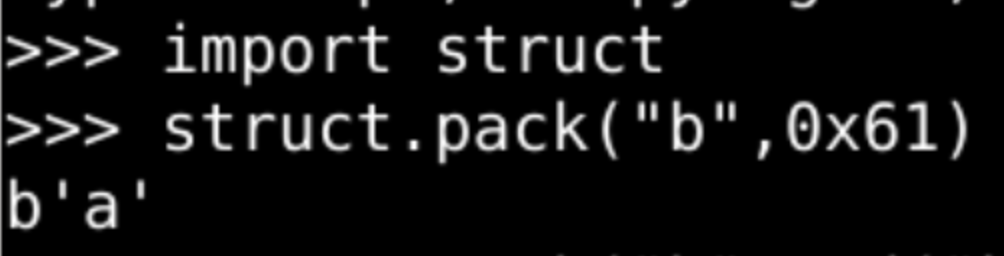
封包pack

遍历
import struct
for n in range(0,128):
b = struct.pack("b",n)
print(b,end=",")
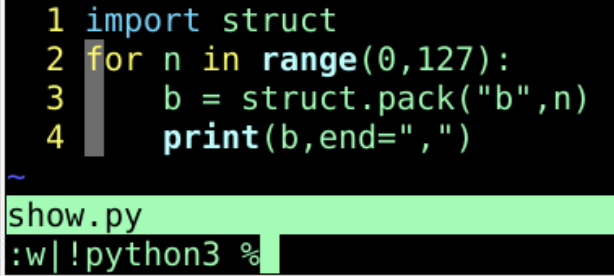
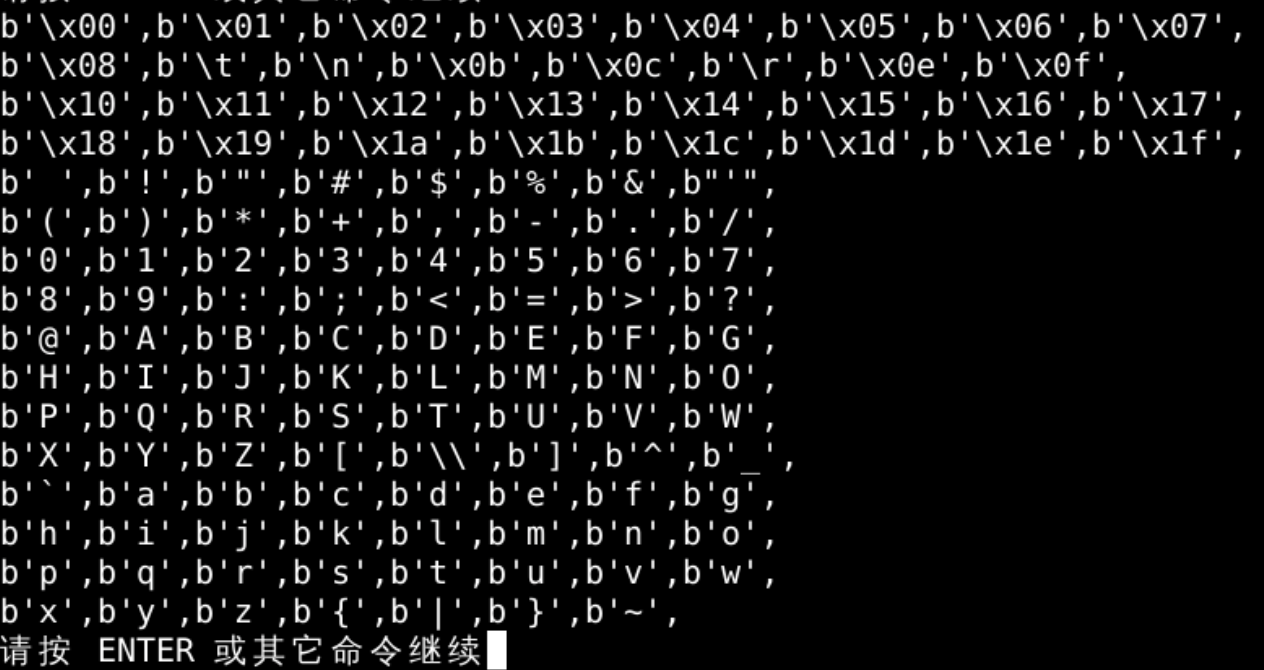
遍历结果
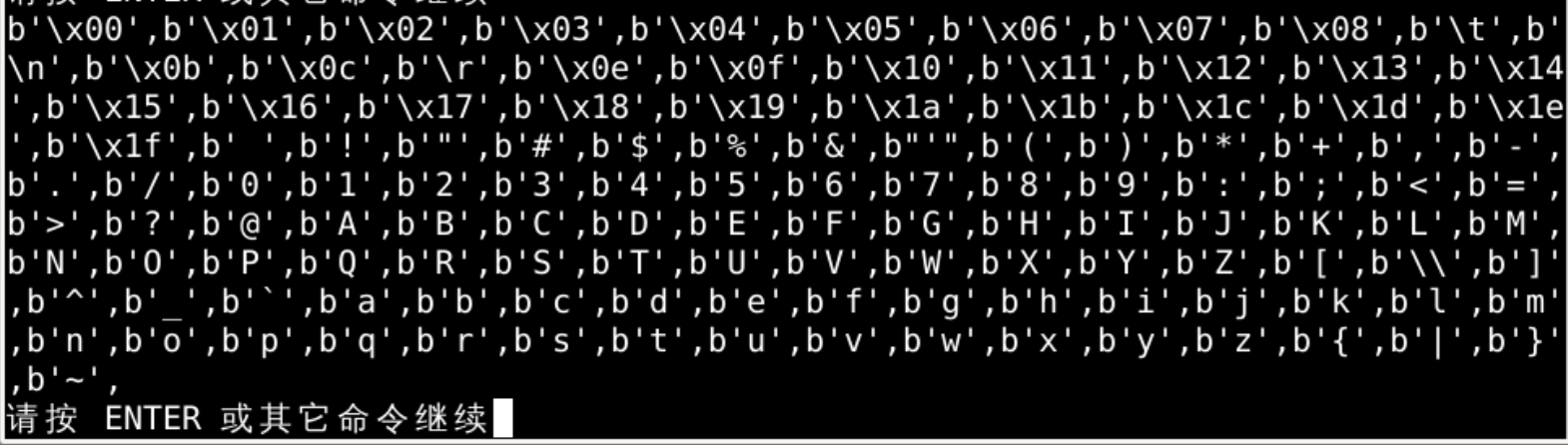
换行

解包
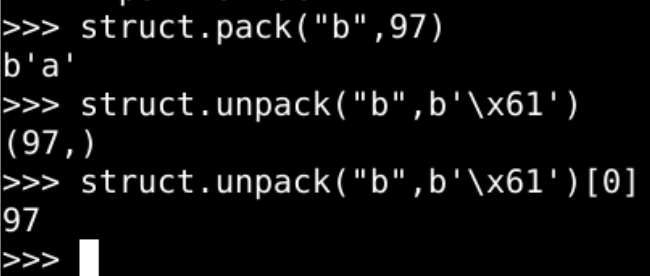
封包再解包
import struct
for n in range(0,127):
b = struct.pack("b",n)
c = struct.unpack("b",b)[0]
print(chr(c),end="")
if n % 16 == 0:
print()
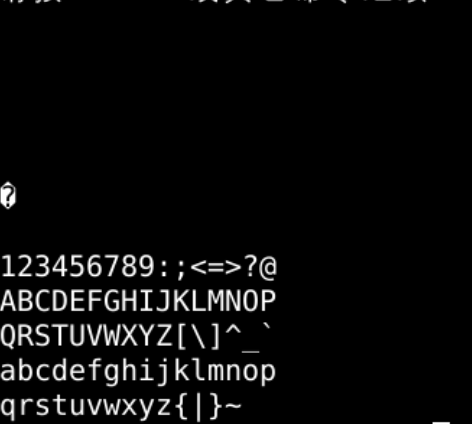
封包再解码
import struct
for n in range(0,127):
b = struct.pack("b",n)
s = b.decode("ascii")
print(s,end="")
if n % 16 == 0:
print()
总结