全部博文(267)
分类: Python/Ruby
2022-02-12 09:56:50
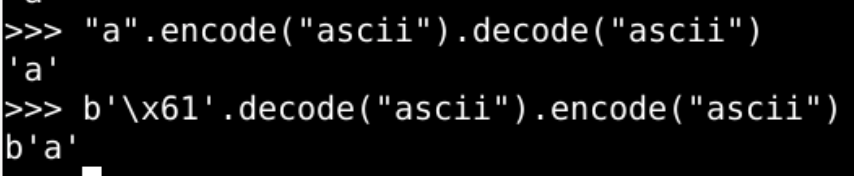
通过 help()可以从 python 命令行模式进入到帮助模式
ord(c)和 chr(i)
这俩是一对,相反相成的
Python 里面的字符对应着一些数字
#输出a,b,c
ord("a")
ord("b")
ord("c")
#输出z-a的数字差距,相对序号
ord("z")-ord("a")
#输出a的相对序号
ord("a")-ord("a")
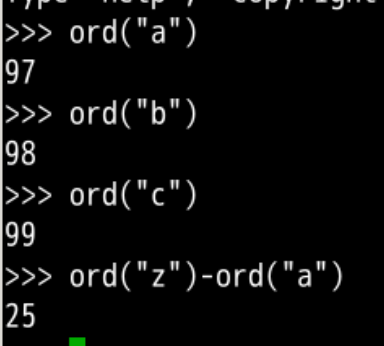
为什么是从 97 开始?

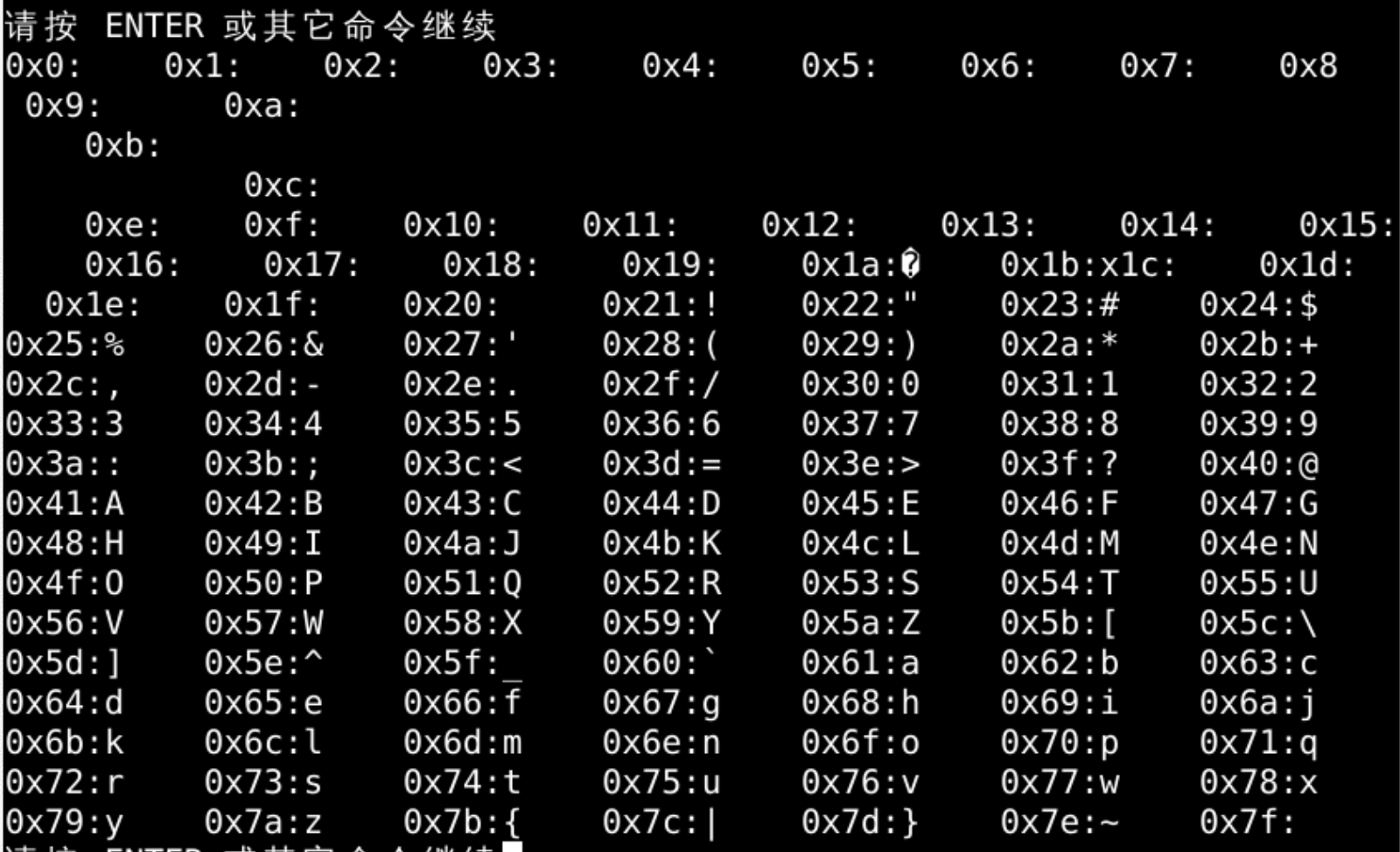
for i in range(0,128):
print(i,end=",")


for i in range(0,128):
print(hex(i),chr(i),sep=":",end=" ")
print(hex(i),chr(i),sep=":",end=" ")
hex(i)
chr(i)
sep=':'
end=" "
sudo apt install ascii
字符包括

1967 年的时候就有了最初这个 ASCII 码表????
当时计算机用高电平和低电平分别表示 0 和 1
字符 和 二进制数 的 映射关系 如果不一致
当时美国的工程师定义了一套编码规则
ASCII
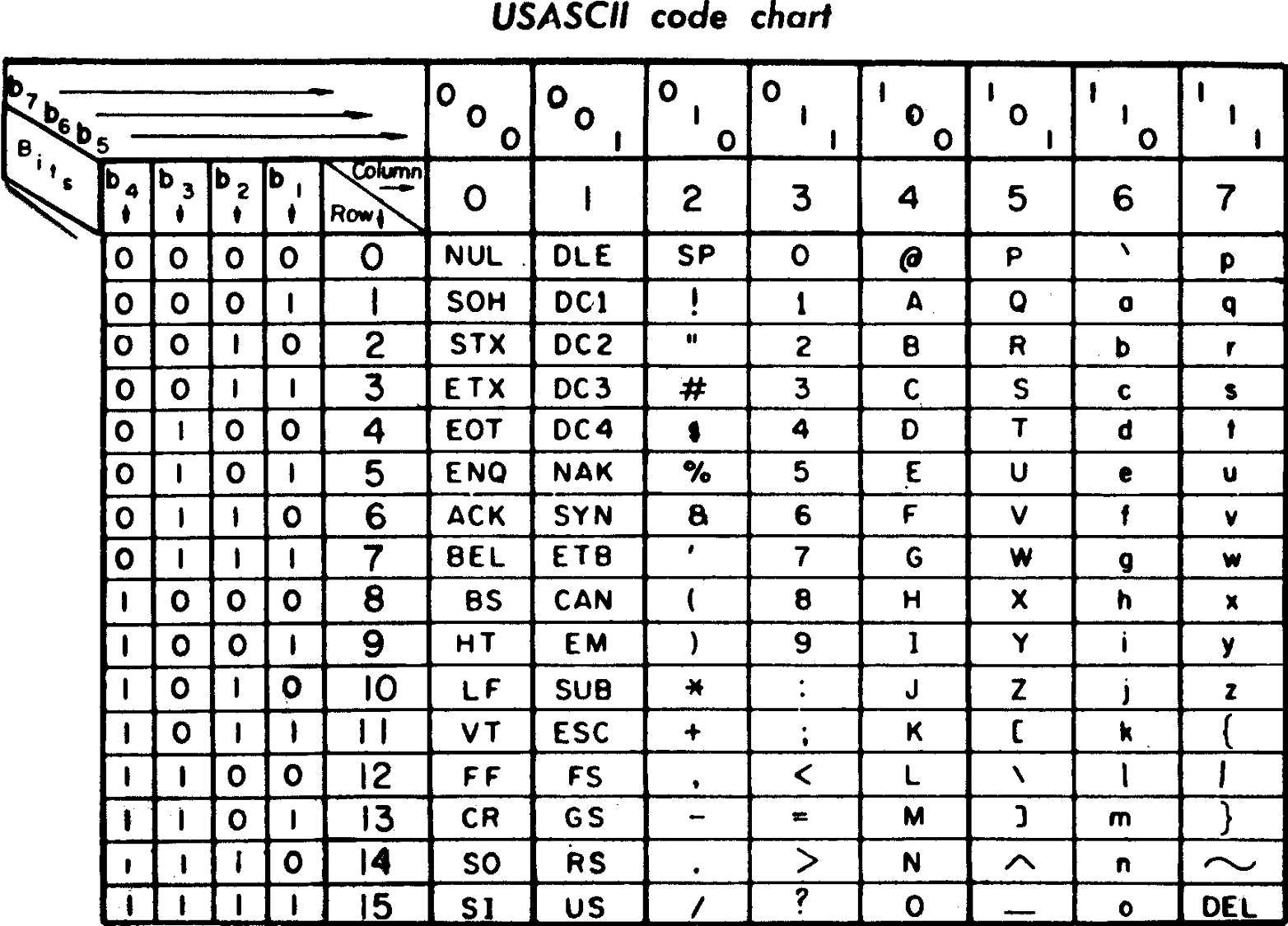
这标准是美国信息交换标准代码是由美国国家标准学会制定的
后来是国际标准化组织定为国际标准
最后一次更新则是在 1986 年
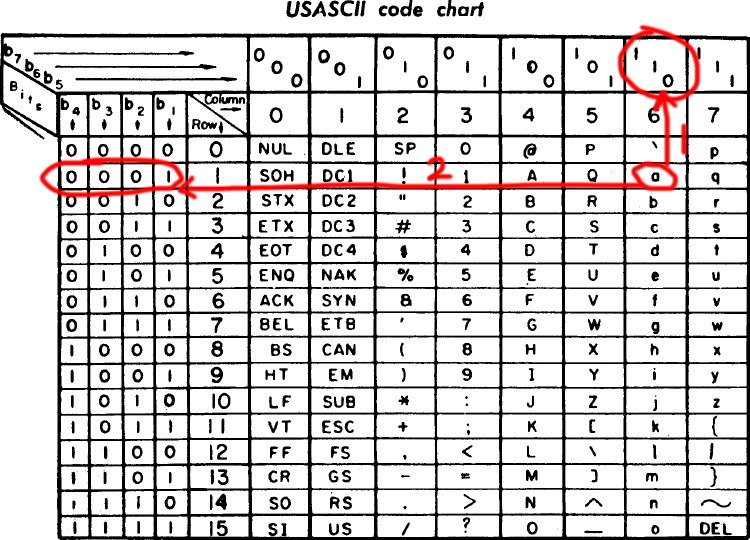
我们找到小写的a
先向上找到110
再向左找到0001
对应关系
1 个 字节 byte
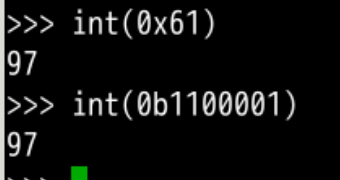
我们可以查询 hex
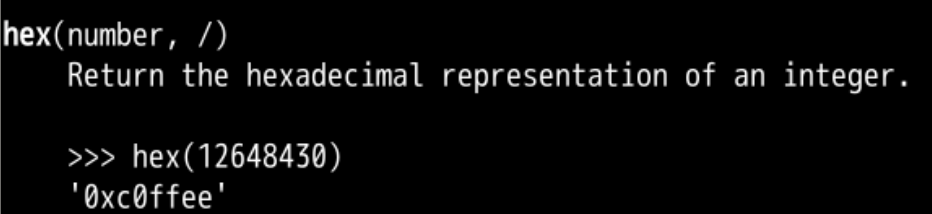
#得到a的序号
ord("a")
#输出97对应的16进制形式
hex(97)
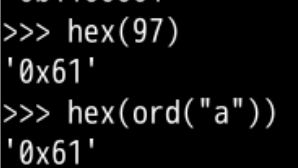
#找到a对应的16进制形式数字对应的字符
hex(ord("a"))
0x61就是十六进制的61
x 的起源

0 的起源
在 C 语言之前的 B 语言用 0 开头表示 8 进制
C 语言继承了类似设定
python 也继续继承
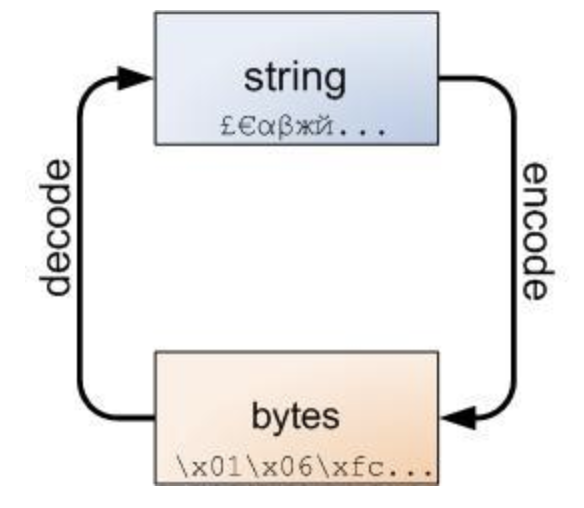
字符和二进制数之间的关系其实是
编码

解码是编码的逆过程

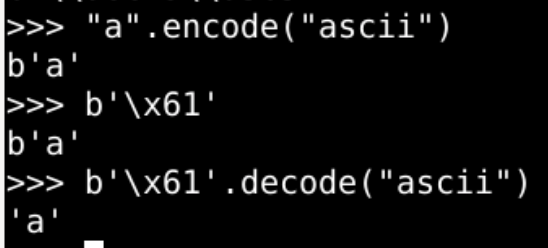
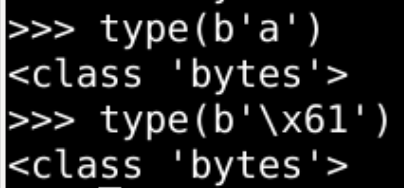
很像
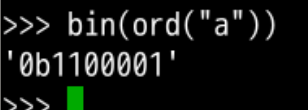
查询 bin


#得到a的序号
ord("a")
#输出97对应的16进制形式
bin(97)
#找到a对应的十六进制形式
bin(ord("a"))
0b是 2 进制数的前缀标志
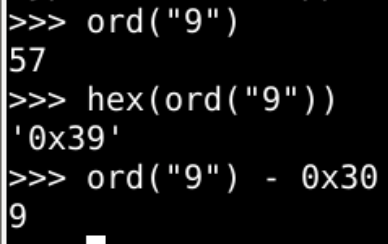
#输出a的ASCII吗
ord("a")
#输出A的ASCII吗
ord("A")
#输出大小写之差
ord("a")-ord("A")
#差值的16进制形式
hex(ord("a")-ord("A"))
#差值的2进制形式
bin(ord("a")-ord("A"))
其实最初不是相差 0x20
有了这种对应关系之后
这个 0x20 发生在 1963 年 5 月
如果是大写字母
0x30-0x39这个范围是数字
0x00-0x1F之间的东西是什么?
可以肯定都是
ASCII 也不是从无到有的
下图是他的编码表

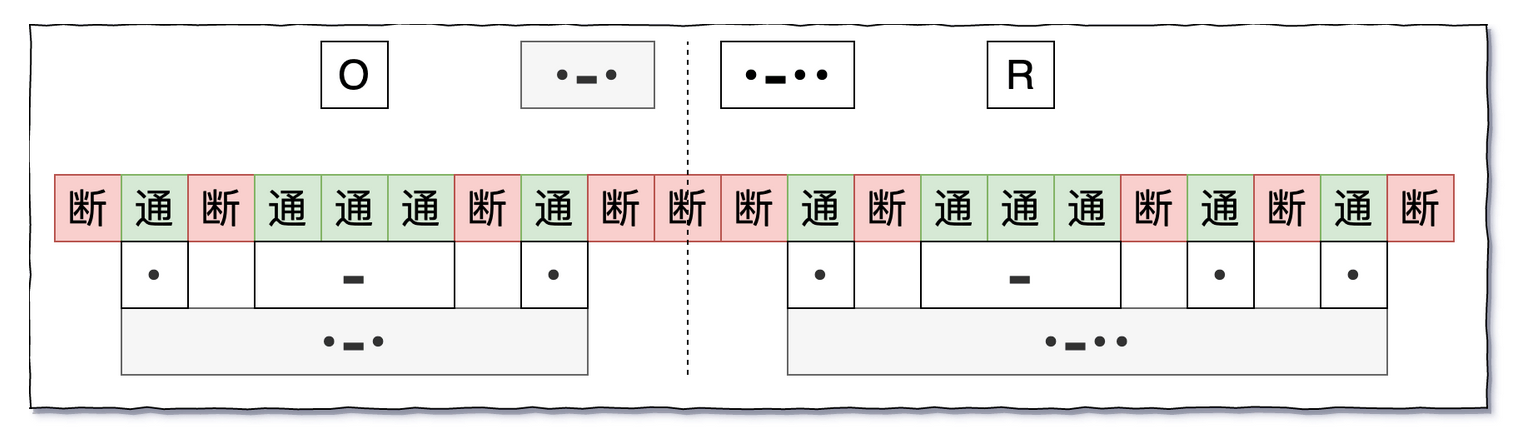
编码的规则是常用的字符点击次数少
按照字符出现概率分配对应点击数量
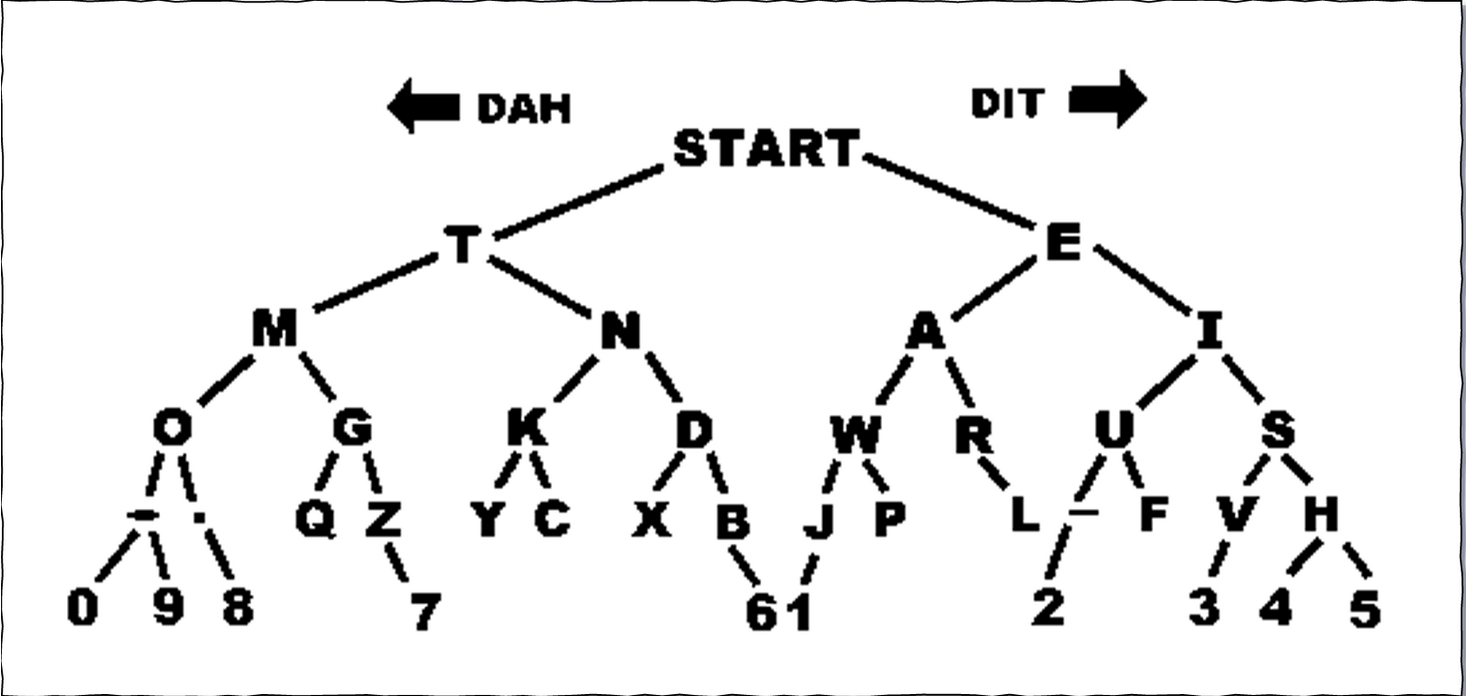
当时完全由人进行发射和接收
这就是早期使用电来进行编码的过程
数制可以转化
编码和解码可以转化
ASCII 码表范围
0x30-0x39 这个范围是 数字
