在使用三剑客grep、sed、awk之前,如果不了解正则表达式,是寸步难行的。
在正则表达式简单入门之后,还需要了解BRE和ERE的区别,否则有些工具和网上案例看的稀里糊涂,因为有些元字符只能在ERE中具有特殊含义,推荐一篇文章: 作者:,正则30分钟忽悠
正则还有一本书,写的非常精彩:《精通正则表达式》
这里Sed的归纳是根据awk and sed这本书做的基础命令归纳,sed工具我现在也学的有点稀里糊涂的,所以简单归纳,知识有限,大家多方面学习
格式 :
sed options [address][sed-command] filename
原理:
正常流程:sed读取文件的备份,一行一行读入到sed的pattern space(模式空间,一个sed工具缓冲区),接着sed-command对每行进行处理,最后输送到标准输入输出(可以重定向),同时清空模式空间内容,接着处理下一行,重复上述动作,直到文本结束,或者[address]规定文本范围
非正常流程,指得仅仅是sed提供了一些命令,改变了执行的顺序,比如next命令(n),比如:标签,跳转到某处执行后续命令等等
第一点:sed操作的是文件的副本,不会影响源文件,但是可以通过sed的options:-i 选项来直接操作源文件,也可以通过>重定向来覆盖源文件
第二点:sed工具的sed-command(编辑命令)可以是多个,可以使用options: -e来提供多个sed-command(编辑命令),也可以通过分组命令大括号{}来使用多个编辑命令,需要注意的是sed的模式空间内容是动态变化的,比如文本行 The Unix System在经过第一个sed-command(编辑命令)后,变成了The UNIX System,这时候再经过第二个sed-command(编辑命令)之后,由The UNIX System变成了The UNIX Operation System.

第二条sed-command是在第一条sed-command处理后的文本(此时文本已经不是第一次读入的The Unix System文本了)上进行替换的,所以说模式空间pattern space内容是动态变化的。
第三点:sed工具有两个缓冲区,一个pattern space,一个hold space,一般的命令都是在pattern sapce完成的,高级命令会涉及hold space(很少用到,但是精通的都懂),其次pattern space执行完sed-command后会清空空间,hold space则不会清空(不知道是不是脚本执行完或者进程执行结束后才会清除)
第四点:学习sed的时候注意sed流控制(这个也是sed高级命令学习的)
sed选项options:
-e 支持多项sed-command
-i 直接修改源文件
-r,-E 支持ERE(扩展正则表达式)
-f 这个选项是脚本使用的
-n
几个选项没啥特殊的地方
[address]:定位文本行
这个框架是用来规定文本行范围的,比如/etc/passwd文本中,可以通过[address]来定位sed-command执行第一行到第三行之内的文本,因为sed默认是全局编辑的。这里在我看来只有一种文本定位方式:
/pattern1/,/pattern2/ 指定从模式pattern1到模式pattern2之间的文本行
其他的定位方式:
x 指定某行执行sed-command
x,y 指定行号x到y之间的行
x,y! 指定匹配x到y之外的行,!非,排除的含义
/pattern/ 指定包含pattern模式的行
x,/pattern/ 指定从行号x开始到第一次包含pattern之间的行
/pattern/,x 指定从第一次包含pattern到行号x之间的行
这里有一个很有意思的地方:大家有没有想过,sed一行一行查询文本时,在第一次碰到pattern时,达到匹配,但是sed还未到达第x行,这时候又碰到了包含pattern的字符,sed会不会再匹配呢?答案是no,不会
/pattern/,+n 指定从第一次匹配包含pattern字符到之后的n行之间的行
x~step step为步长,表示从x行开始,每step行编辑一次
在这里说明一下:sed内部的计数器是固定的(一个文本,一个固定的计数器),所以一个文本中第x行,第y行都是唯一标识,固定死了的,不存在碰到第二个第x行、第y行,所以以行x(数字)开头或结尾的文本定位只能定位一个区域,而以/pattern1/,/pattern2/定位的文本可以匹配多个区域,字符pattern1可以进行第二次匹配
/pattern1/,/pattern2/ 可以理解为以包含pattern1字符行启用匹配,直到包含pattern2字符的行结束,那么如果当第二次匹配pattern1字符之后,sed无法匹配到第二个pattern2字符会怎么样?sed会直接匹配到文本结束。

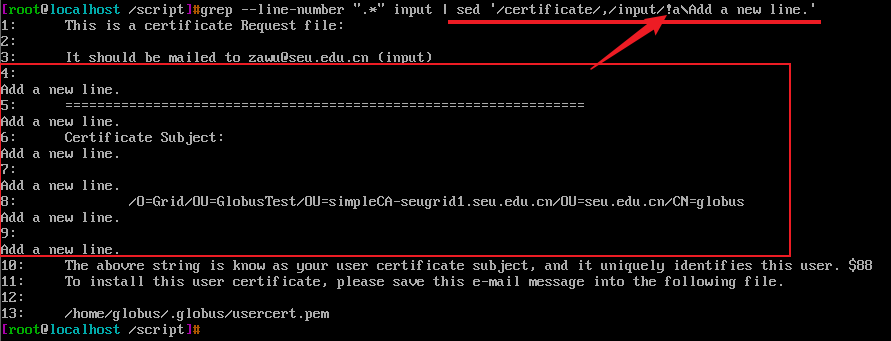
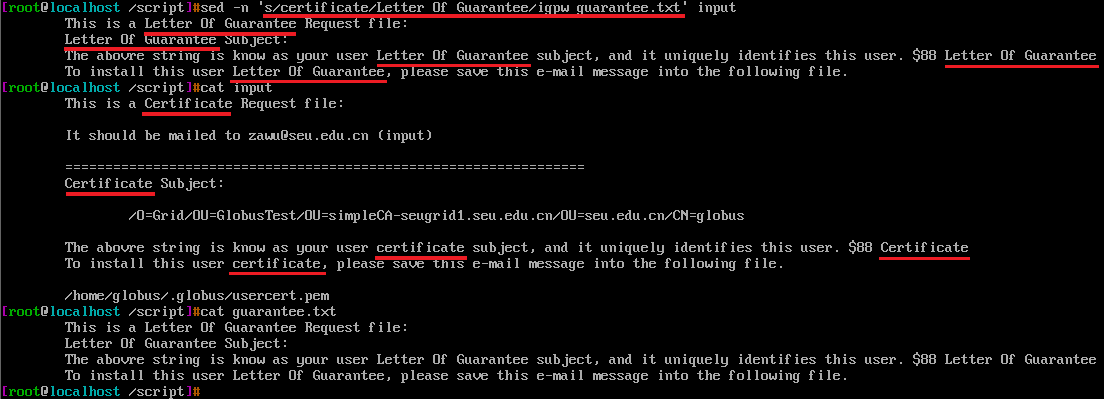
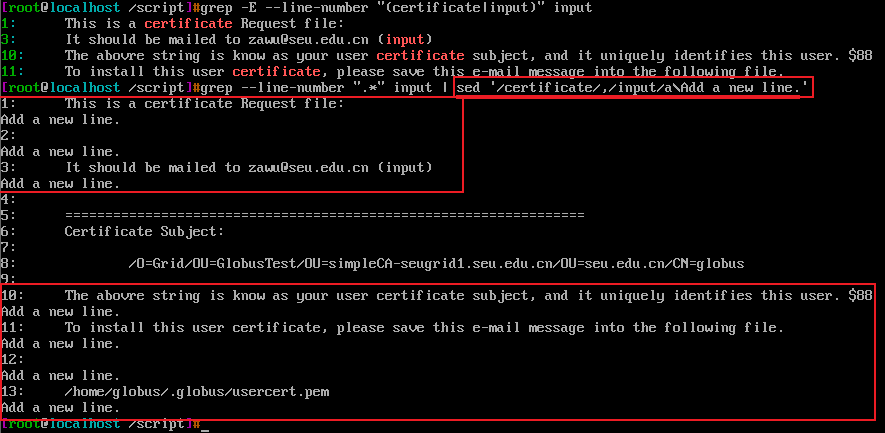
文件input第1,第10,第11行包含字符certificate,只有第3行包含input字符
sed '/certificate/,/input/a\Add a new line.' 匹配第1行的certificate,到第3行匹配到字符input结束,执行sed-command动作 a\Add a new line.每行追加新的一行文本,sed接着读取第4行,未匹配到certificate,第5,第6.....第9都没有匹配到certificate,所以未执行a\Add a new line. sed在第10行再次匹配到certificate,直到结束都未再次匹配到input
实质上,当sed匹配到certificate时,就在执行a\Add a new line. 直到匹配到input字符所在行时,结束a\Add a new line.
awk and sed书中有一句话:sed没有办法先行决定第二个地址是否会匹配。一旦匹配了第一个地址,这个动作就将应用与这些行。简单直接概括了上面的动作。

!非, 不仅仅只是能x,y!,也可以/pattern/,x!, /pattern1/,/pattern2/!
定位文本可以结合正则表达式一起使用,但是正则表达式中有些元字符会与sed中的命令冲突。比如$在正则表达式中表示一行的行尾,在sed中则表示文本的最后一行。正则表达式不熟练,学的头炸,会混淆

强调!强调!强调!sed使用正则表达式时,一定要在两个反斜杠/之内,否则sed会将其解释成sed工具本身的元字符,如果sed工具本身没有元字符则提示无法识别该命令

^是正则表达式的元字符,而sed工具不具有^命令,所以提示不认识这个人是谁
然后就是sed中分组命令:大括号{}的运用
可以将一个地址[address]嵌套在另一个地址[address]中,也可以在相同的地址[address]上使用多个命令(这里的地址就是定位文本行[address])。

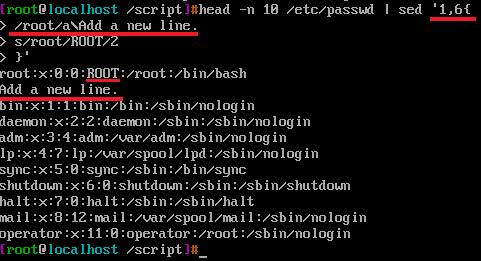
最后一行的root之所以没有匹配到是因为sed定位1,6行
[sed-command]:sed编辑命令,归纳五个a\ i\ c\ d l(小写L)
a\命令 追加文本到匹配行的后面一行
i\命令 插入文本到匹配行的前面一行
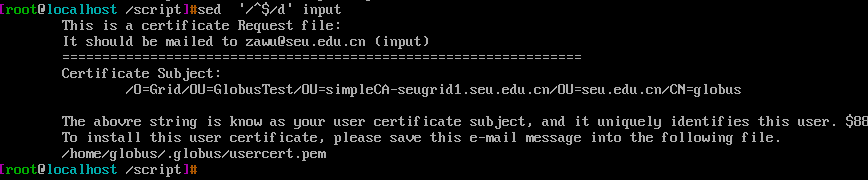
删除命令:d
删除命令将指定的定位[address]文本行给删除,上面的sed '/^$/d' input就是例子
需要说明的是删除命令是一个可以改变脚本中控制流的命令,这在sed的分组命令{}中体现非常明显

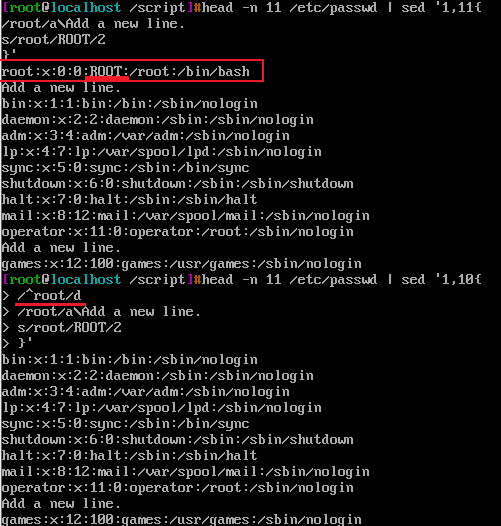
/^root/d将第一行给删除,同时终止了后面的/root/a\Add a new line. s/root/ROOT/2两个命令的执行,改变了控制流,接着从第二行重复/^root/d /root/a\Add a new line. s/root/ROOT/2。其实在我的理解中,sed工具针对行,每次pattern space只有一行,那么在行首包含root的行,首先执行了d命令后,直接将pattern space中的文本行都删除了,也就是pattern space空了,没有内容了,之后后面的编辑命令也就不存在执行的问题了。
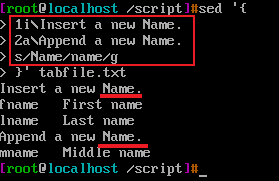
a\ i\ c\都有一个特殊的地方:追加的文本,插入的文本,更改的文本不参与a\ i\ c\后续的sed-command编辑命令,比如:

a\ i\插入的文本包含Name字符,后续编辑命令s/Name/name/g 却没有将a\ i\ 追加的文本行,插入的文本行中的字符Name替换成name,就是因为a\ i\ c\添加的文本不参与后续的编辑命令
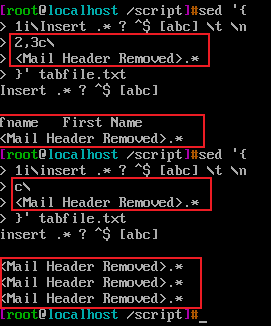
c\ 更改命令,将指定行文本更改成指定的文本,更改命令另外还有一个特殊功能:当更改命令作为一组命令之一被封闭在大括号{}中时,它将具有相反的功能。


c\在大括号中有定位文本行更改时,依然指定文本行更改文本效果一样,但是在不指定定位文本范围时,结果却是文本行每一行添加一个需要更改的文本,因为tabfile.txt只有三行,所以添加了三行.*
同时a\ i\ c\添加的文本只是字面意思,不具备特殊含义(\t \n在其中被解释成了特殊含义),这与s命令的替换部分何其相似,s命令的替换部分也只有少量的元字符,大部分字符解释成字面意思。
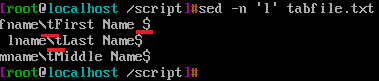
l命令(小写L):打印非可见字符

l要与-n选项结合使用,否则将会重复显示。
下面说一个sed中经典的命令:s命令
sed options [address]s/pattern/replacement/flags filename
sed命令flags标志位:
n 1到512之间的一个数字,表示对文本模式中指定模式第n次出现的情况进行替换(这个是标志位的数字,在s命令的replacement部分还有\n(此n范围1-9)不要混淆)
g 对pattern进行全局替换,全局替换成replacement,sed默认只对第一次出现的pattern进行替换
p 打印模式空间的内容,此命令以及后面出现的r,w标志位flags与sed工具命令p,r,w命令效果都一样
w file 将模式空间的内容写到文件file中,如果文件file存在,则覆盖,如果file不存在,则创建文件
r file 读入文件到模式空间
i 忽略pattern的大小写,进行replacement替换。该标志只有GNU Sed才可使用
上面的flags位可以组合使用,同时说明一下p,w,r与sed命令p,w,r的区别是s命令的flags位p,w,r的执行条件是s命令得到匹配,才会执行到flags位

i忽略了certificate的大小写,g全局替换成Letter Of Guarantee,w将其写入到当前目录下的guarantee.txt文件,p将替换结果行输送到屏幕。这些前提条件都是s命令匹配到certificate字符。

改掉最后一个字符,结果无任何输出。关于上面“这些前提条件都是s命令匹配到certificate字符”这句话,我看了一下,我的理解有偏差,虽然上面无任何打印,但是w实质上还是创建了一个空文件。
sed替换命令的分界符:
sed的分界符不是唯一的斜杠/,也可以是| 或者^或@或#等等
sed 's/root/ROOT/g' /etc/passwd, 标记红线的就是分界符,同时需要注意的是分界符在s命令运用中必然是三个同时出现的。
sed替换命令replacement部分:
这一部分字符串,大部分字符串表示字符字面意思,只有少量的字符具有特殊含义
& 当replacement中使用了&时,它(&)会被替换成匹配到的pattern的内容,如果pattern使用的是正则表达式,那么对应replacement部分中&就变化多端了
\n 匹配第n个字符串,n范围在1-9,在sed命令的pattern部分使用\(和\)时,默认将分组中的内容保存在\1中,第二个\( \)则存储在\2中,以此类推,最多存储到\9 \n是配合\(\)使用的
\(反斜杠) 当replacement部分需要使用到&、\反斜杠以及替换命令的分界符时,需使用\反斜杠来转义&、\和分界符,以解释成字面意思。并且\反斜杠还有另一层功能:创建多行replacement字符串


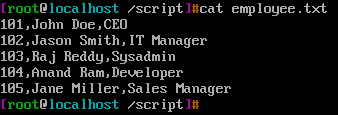
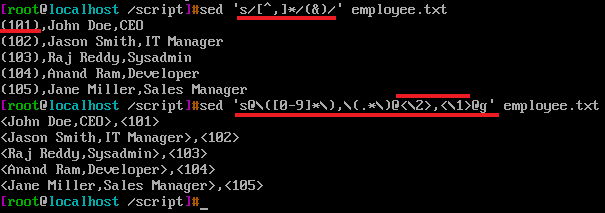
s/[^,]*/(&)/ 给逗号之前的字符穿上()
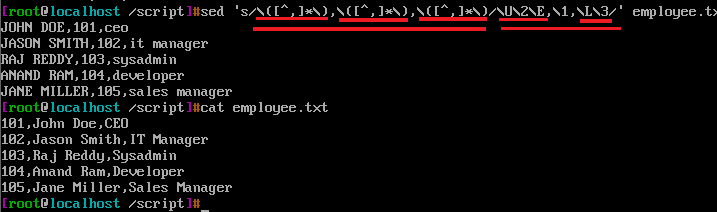
s@\([0-9]*\),\(.*\)@<\2>,<\1>@g \([0-9]*\) 匹配数字,*表示可以是无数字,也可以表示n多位数字,同时\(\)将匹配结果存储在\1中,紧接着是,逗号,紧接着是\(.*\),将逗号之后的所有字符都匹配上,同时存储在\2中,这种解读的思维是正则表达式的解读思维,无论阅读还是解读起来都相对容易理解上面的语句。
<\2>,<\1>,将匹配的顺序对调,这样显示就发生了变化,同时如果将<>或者<>之间的逗号替换成()和.句点号,那么元字符()和.句点号在replacement部分是否被解释成特殊含义呢?答案是不会。因为() . 不是replacement部分的元字符。上面分界符用了@,如果用了/,再加上pattern部分,replacement部分也有\、/,那阅读起来简直懵逼眼花

replacement部分,前两个\\,第一个\用来转义后一个\,而&前面没有\,所以表示匹配pattern部分的内容。

反斜杠\后面不能有任何字符,否则不会被解释成\n换行效果。
有机会我归纳一下awk and sed书中用sed来处理一些细节的案例。replacement部分这些元字符运用起来也有很多奇妙的地方。
下面说一下在replacement部分中,只有在GNU Sed才能使用的标志
\l(小写L 应该是lower的首字母) 表示将紧跟在其后面的字符当作小写字符来处理

\L标志 表示将后面所有的字符都当作小写字符来处理

\u标志 与\l相似,将后面紧跟的一个字符当作大写字符来处理
\U标志 将后面的所有字符当作大写字符来出来
\E标志 \E标志结合\U或者\L一起使用,它将关闭\U\L的功能

注意:上面这四个标志只能在GNU Sed中使用,而且使用在s命令的replacement部分
归纳完[address]、flags、replacement部分后,现在s命令只剩下pattern部分没有归纳了,pattern部分主要就是结合正则表达式进行文本匹配,正则表达式多精通,这里就能玩出多少花样。
到这里sed工具的基本一些命令归纳完了,其他的像p,=,w,r 我觉得没啥需要注意的细节
其次,剩下一些sed高级命令或者控制流相关命令,比如q(退出命令),n(next 下一步命令),还有处理多行模式空间的N,D,P, hold space和pattern space 方面的H、h、G、g、x
以及更改控制流的(:、b、t)等等
END