分类: 大数据
2020-04-20 10:34:38
图像识别为什么要用卷积神经网络CNN?比传统神经网络好在哪里?
核心差别点:多了卷积层+池化层,所以本文主要是梳理卷积层和池化层设计原理+CNN模型实现(基于Keras代码)
传统神经网络的劣势
我们知道,图像是由一个个像素点构成,每个像素点有三个通道,代表RGB颜色,如果一个图像的尺寸是(28,28,1),即代表这个图像的是一个长宽均为28,channel为1的图像(channel也叫depth,此处1代表灰色图像)。如果使用全连接的网络结构,即,网络中的神经与与相邻层上的每个神经元均连接,那就意味着我们的网络有28 * 28 =784个神经元,hidden层采用了15个神经元,那么简单计算一下,我们需要的参数个数(w和b)就有:7841510+15+10=117625个,这个参数太多了,随便进行一次反向传播计算量都是巨大的,从计算资源和调参的角度都不建议用传统的神经网络。卷积神经网络CNN通过卷积层、池化层分别对图像数据进行特征提取,特征降维,可以大大减少计算权重参数的工作量。Dropout层的设计可以随机将一定比例的神经元权重设置为0,有效防止过拟合。
CNN卷积神经网络图像识别图解:
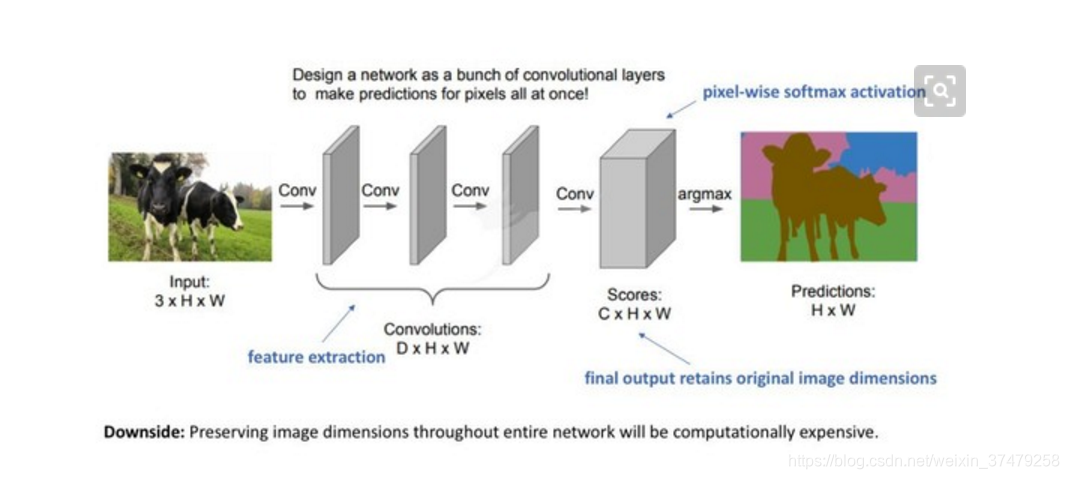
一、CNN图像识别数据流工作过程:

1输入:图像预处理、图像增强
2特征提取:多层卷积+池化
2.1卷积层要点:
可以把卷积核就理解为特征提取器,只需要把图片数据灌进去,设计好卷积核的尺寸、数量和滑动的步长就可以让自动提取出图片的某些特征,从而达到分类的效果。
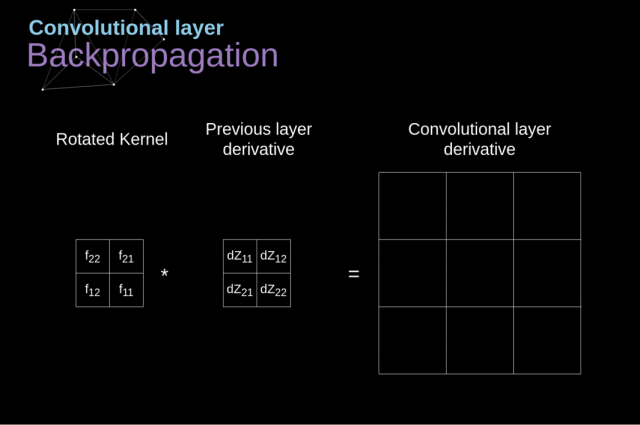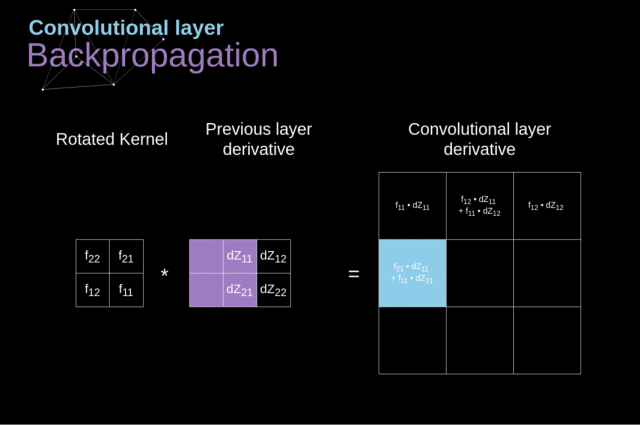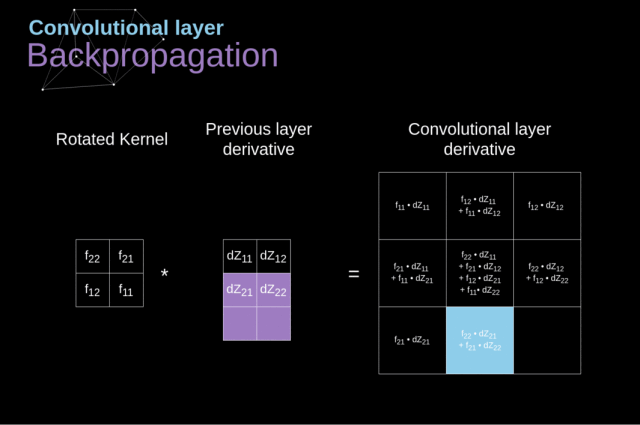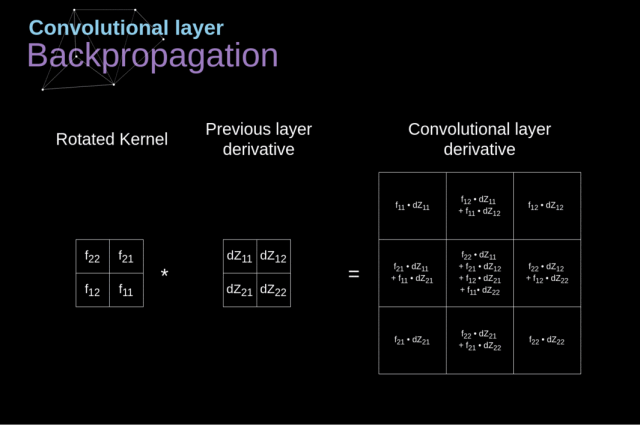
卷积核上数字为权重,与上一层输入对应位置相乘再相加,得到卷积层输出结果。有N卷积核,相应输出N个通道层数据。那么第二层卷积层的卷积核对应(3,3,N),tensorflow需要界定,Keras只要界定(3,3)即可。
边界补齐:卷积核按照一定步长移动覆盖输入层,为了加速计算,对边界进行补齐:

2.2池化层要点:
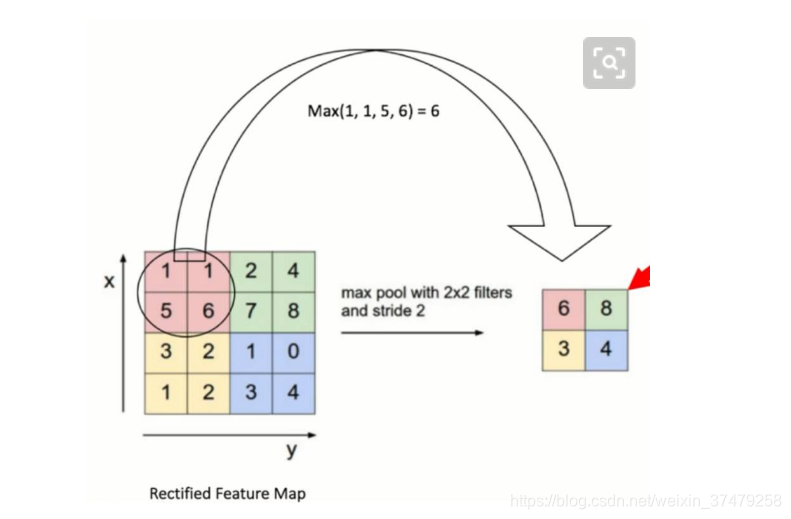
池化层的目的:
为了减少训练参数的数量,降低卷积层输出的特征向量的维度
,只保留最有用的图片信息,减少噪声的传递。
实现方式:
最大池化:max-pooling——选取指定区域内最大的一个数来代表整片区域
均值池化:mean-pooling——选取指定区域内数值的平均值来代表整片区域
3分类识别:全连接层、dropout层(防止过拟合)、softmax(传统神经网络也有,在此不多赘述)
以上重点梳理卷积神经网络比传统神经网络的优势点:卷积层、池化层设计原理。
