蚂蚁金服技术团队
分类: IT职场
2020-03-05 09:37:51
人工智能目前存在的难题是鱼与熊掌不可兼得,也就是隐私性跟可用性难以兼顾。如果想要AI系统发挥作用,就可能需要牺牲隐私。但是,在大量真实场景中,如果做不到同时兼顾隐私和可用性,会导致很多AI落地的困境。随着对数据安全和重视和隐私保护法案的出台,曾经粗放式的数据共享受到挑战,各个数据拥有者重新回到数据孤岛的状态。同时,互联网公司也更加难以收集和利用用户的隐私数据,数据孤岛反而成为了常态。如果希望更好的利用数据,就必须在满足隐私保护和数据安全的前提下,在不同的组织、公司与用户之间进行数据共享。
为了解决这一问题,国内外不少科技公司先后推出了解决方案,比如谷歌推出的联邦学习、蚂蚁金服提出的共享智能等。本文,InfoQ对蚂蚁金服机器学习算法中台负责人周俊进行了采访,了解共享智能如何解决金融领域的数据共享问题。
共享智能与联邦学习的区别
在介绍技术实践之前,我们需要花些时间厘清共享智能与联邦学习之间的区别,以方便读者了解本文的讨论范围。
当前,业界解决隐私泄露和数据滥用的数据共享技术路线主要有两条。一条是基于硬件可信执行环境(TEE:Trusted Execution Environment)技术的可信计算,另一条是基于密码学的多方安全计算(MPC:Multi-party Computation)。
TEE字面意思是可信执行环境,核心概念为以第三方硬件为载体,数据在由硬件创建的可信执行环境中进行共享。目前在生产环境可用的TEE技术,比较成熟的基本只有Intel的SGX技术,基于SGX技术的各种应用也是目前业界的热门方向,微软、谷歌等公司在这个方向上都有所投入。
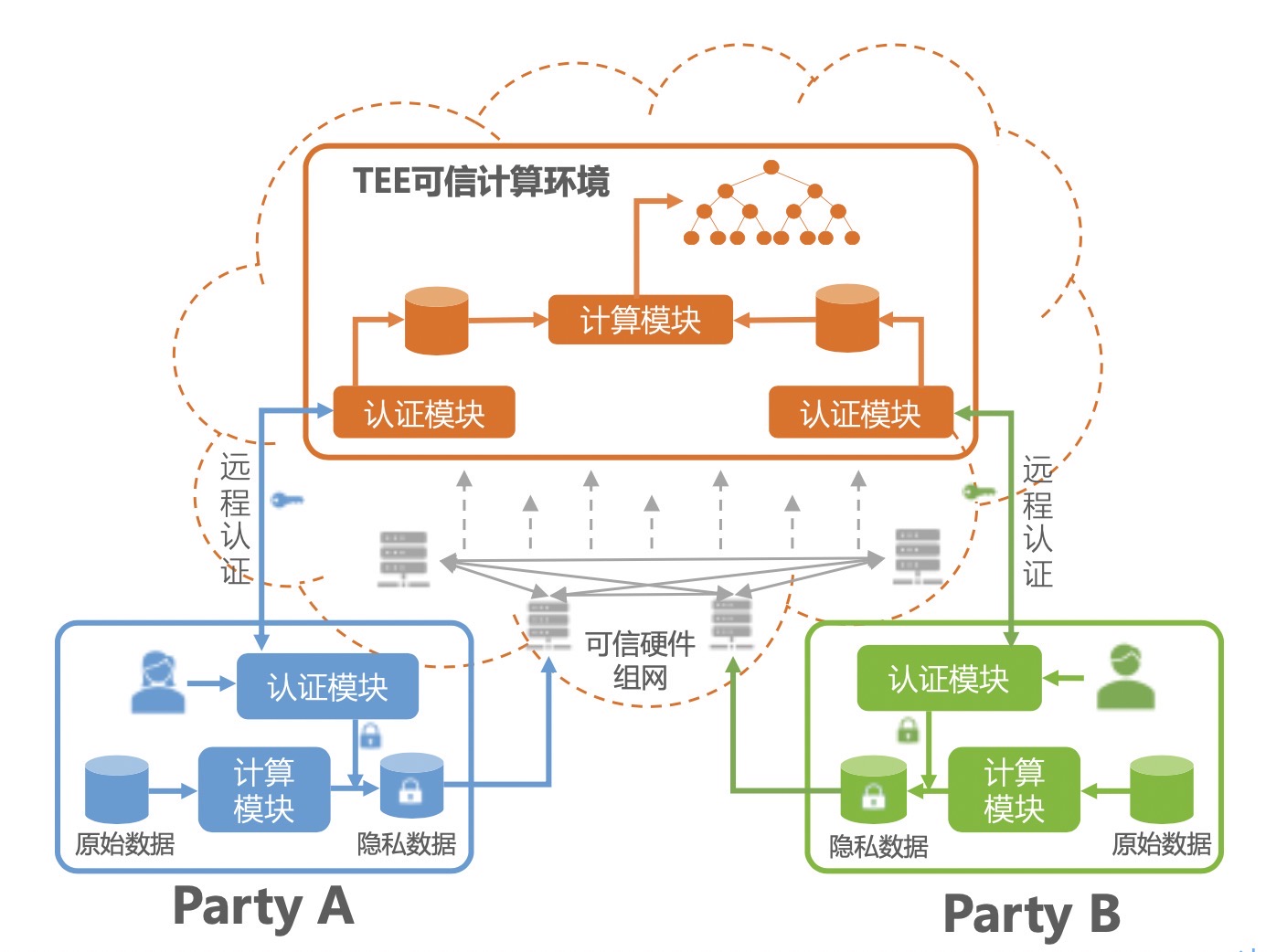
MPC(Multi-party Computation,多方安全计算)一直是学术界比较火的话题,但在工业界的存在感较弱,之前都是一些创业小公司在这个方向上有一些探索,例如Sharemind,Privitar,直到谷歌提出了基于MPC的在个人终端设备的“联邦学习”(Federated Learning)的概念,使得MPC技术一夜之间在工业界火了起来。
当前,业界针对数据共享场景,利用如上技术路线推出了一些解决方案,包括隐私保护机器学习PPML、联邦学习、竞合学习、可信机器学习等,不同解决方案采用的技术路线相互也会有一些重叠。周俊表示,蚂蚁金服提出的共享智能(又称:共享机器学习)结合了TEE与MPC两条路线,同时结合蚂蚁的自身业务场景特性,聚焦于金融行业的应用。
简单来说,共享智能的概念,或者说理念,是希望在多方参与且各数据提供方与平台方互不信任的场景下,能够聚合多方信息进行分析和机器学习,并确保各参与方的隐私不被泄漏,信息不被滥用。
关于共享智能与联邦学习的差异,周俊表示,目前,联邦学习涉及两个不同的概念:
第一种是谷歌提出的联邦学习,旨在解决云 + 端训练过程中,端上隐私不暴露的问题,这是一个 To C + 数据水平切分的场景。除了保护端上的数据隐私外,其重点还在于如何解决训练过程中,端自身可能掉线等问题。
第二种是国内提出的联邦学习,主要用于解决 To B 场景中各方隐私不泄露的问题,既可应用于数据的水平切分场景,也可应用于数据垂直切分的场景。它们侧重于不同的数据共享场景,技术上有不同的侧重点。
2019年,一篇由多个知名大学和企业撰写的关于联邦学习的综述文章《Advances and Open Problems in Federated Learning》,对联邦学习的定义和描述是比较清晰的。首先,联邦学习的架构是由一台中心服务器和多个计算节点构成,中心服务器会参与到整个计算过程,因此不适用于一些不需要中心服务器节点的应用场景(文章中将这种模式称为Fully Decentralized Distributed Learning )。此外,联邦学习要求原始数据不能出域,这也限制了其可以使用的技术方案,而共享智能是从问题出发,作为一个新兴的技术领域,在面临当前各种复杂场景的时候,很难用一套技术方案去解决所有问题,因此共享智能的解决方案中不仅包含有类似联邦学习的有中心服务器参与计算的模式,也包含完全去中心化的方案,还有基于TEE的共享学习方案。
在不同的场景下,不同的方案各有优劣。周俊表示,目前,数据共享下的机器学习仍然还有很多待突破的地方,我们并不纠结于解决问题的是联邦学习还是去中心化的分布式学习,或者是其它任何技术方案,最终还是希望大家能够合力解决这个业界难题。
蚂蚁金服共享智能应用实践
2016年开始,蚂蚁金服就开始投入到共享智能的研究中,出发点是为了解决业务中遇到的问题,比如机构与蚂蚁金服的信息协同问题。基于此,蚂蚁金服调研了差分隐私、矩阵变换等多种方案,确定了目前的技术大方向。
纵观整个研发阶段,周俊认为大致可以分为探索期、技术攻坚和技术应用三个时期。
- 探索期:对业界相关技术进行全面摸底,并设计了上百个方案,逐一验证可行性,并在真实场景反复锤炼技术,实现从0到1的突破;
- 技术攻坚期,经过前面的摸索,确定了几个可能适用于工业界的方案,进一步在大规模工业场景下,对这些方案的安全性和性能等逐一优化提升;
- 技术应用期,开始大规模在真实业务场景中应用,直面业务需求,进一步淬炼技术,接受市场检验。
在共享智能的技术细节上,周俊表示,可以按照TEE和MPC两条路线来理解。
基于TEE的共享学习
蚂蚁共享学习底层使用Intel的SGX技术,并可兼容其它TEE实现。下面着重介绍一下
基于TEE的共享学习中的一种数据加密出域的方案,目前,这种方案已支持集群化的模型在线预测和离线训练。
1. 模型在线预测
预测通常是在线服务。相对于离线训练,在线预测在算法复杂度上面会相对简单,但是对稳定性的要求会更高。提升在线服务稳定性的关键技术之一就是集群化的实现——通过集群化解决负载均衡,故障转移,动态扩容等稳定性问题。
但由于SGX技术本身的特殊性,传统的集群化方案在SGX上无法工作。
为此,蚂蚁金服设计了如下分布式在线服务基本框架:
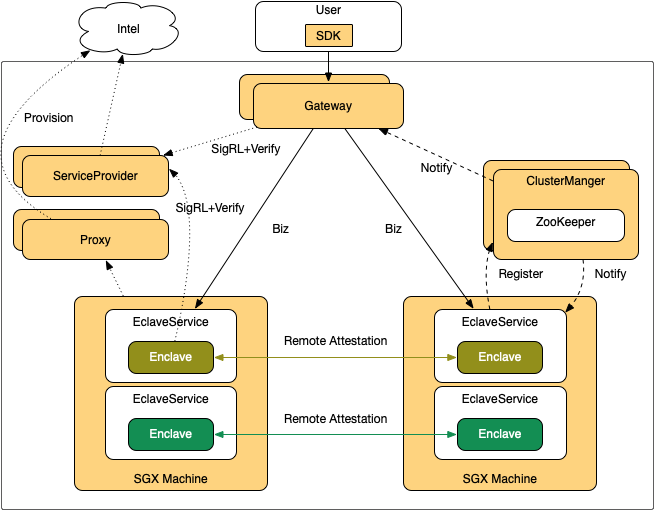
该框架与传统分布式框架不同的地方在于,每个服务启动时会到集群管理中心(ClusterManager,简称CM)进行注册,并维持心跳,CM发现有多个代码相同的Enclave进行了注册后,会通知这些Enclave进行密钥同步,Enclave收到通知后,会通过远程认证相互确认身份。当确认彼此的Enclave签名完全相同时,会通过安全通道协商并同步密钥。
2. 模型离线训练
模型训练阶段,除了基于自研的训练框架支持了LR和GBDT的训练外,蚂蚁金服还借助于LibOS Occlum(蚂蚁主导开发,已开源)和自研的分布式组网系统,成功将原生Xgboost移植到SGX内,并支持多方数据融合和分布式训练。通过上述方案,不仅可以减少大量的重复性开发工作,并且在Xgboost社区有了新的功能更新后,可以在SGX内直接复用新功能,无需额外开发。目前,蚂蚁金服正在利用这套方案进行TensorFlow框架的迁移。
此外,针对SGX当下诟病的128M内存限制问题(超过128M会触发换页操作,导致性能大幅下降),蚂蚁金服通过算法优化和分布式化等技术,大大降低内存限制对性能的影响。
上述方案在多方数据共享学习训练流程如下:
1. 机构用户从Data Lab下载加密工具
2. 使用加密工具对数据进行加密,加密工具内嵌了RA流程,确保加密信息只会在指定的Enclave中被解密
3. 用户把加密数据上传到云端存储
4. 用户在Data Lab的训练平台进行训练任务的构建
5. 训练平台将训练任务下发到训练引擎
6. 训练引擎启动训练相关的Enclave,并从云端存储读取加密数据完成指定的训练任务。

此外,针对有一些数据提供方不希望数据出域的场景,蚂蚁还提供了使用TEE对训练过程中的参数信息进行加密的技术方案,篇幅原因,就不在这里展开了。
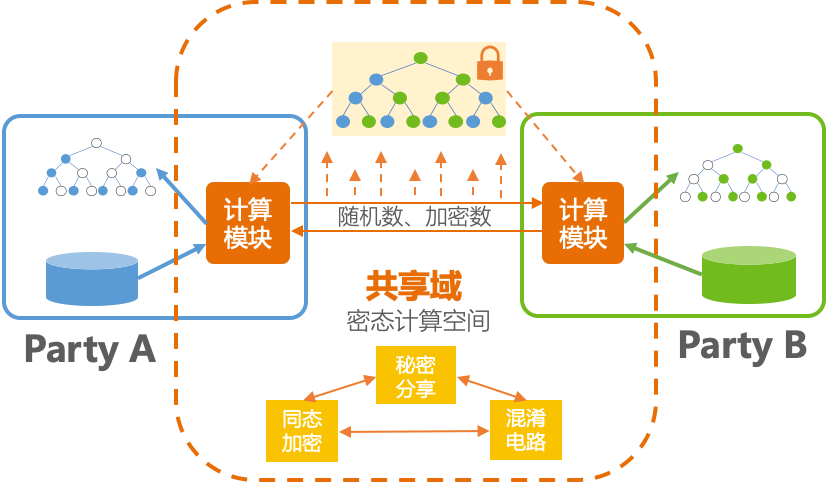
基于MPC的共享学习
蚂蚁基于MPC的共享学习框架分为三层:
- 安全技术层:安全技术层提供基础的安全技术实现,比如在前面提到的秘密分享、同态加密、混淆电路,另外还有一些跟安全密切相关的,例如差分隐私技术、DH算法等;
- 基础算子层:在安全技术层基础上,蚂蚁金服会做一些基础算子的封装,包括多方数据安全求交、矩阵加法、矩阵乘法,以及在多方场景下,计算sigmoid函数、ReLU函数等;同一个算子可能会有多种实现方案,用以适应不同的场景需求,同时保持接口一致;
- 安全机器学习算法:有了基础算子,就可以很方便的进行安全机器学习算法的开发,这里的技术难点在于,如何尽量复用已有算法和已有框架,蚂蚁金服在这里做了一些有益的尝试,但也遇到了很大的挑战。
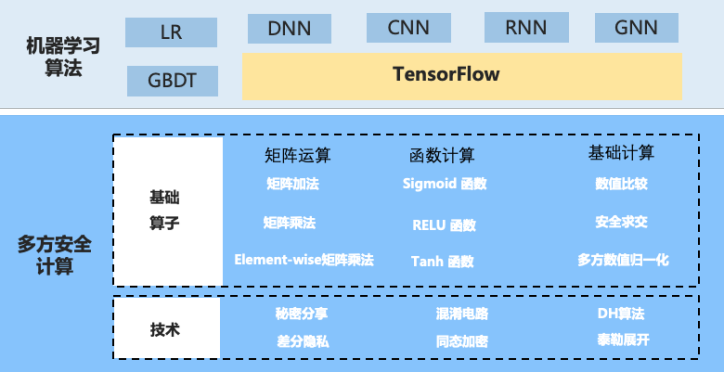
目前,这套基于MPC的共享学习框架已支持了包括LR、GBDT、DNN等头部算法,后续一方面会继续根据业务需求补充更多的算法,同时也会为各种算子提供更多的技术实现方案,以应对不同的业务场景.
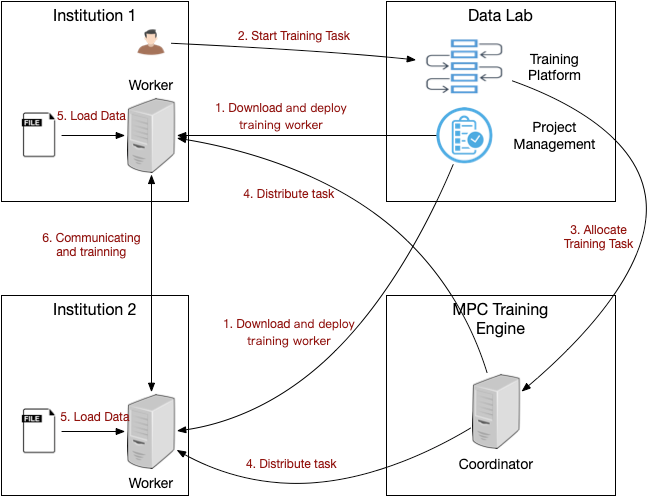
基于MPC的多方数据共享学习训练流程如下:
1. 机构用户从Data Lab下载训练服务并本地部署
2. 用户在Data Lab的训练平台上进行训练任务的构建
3. 训练平台将训练任务下发给训练引擎
4. 训练引擎将任务下发给机构端的训练服务器Worker
5. Worker加载本地数据
6. Worker之间根据下发的训练任务,通过多方安全协议交互完成训练任务
训练引擎的具体架构如下:
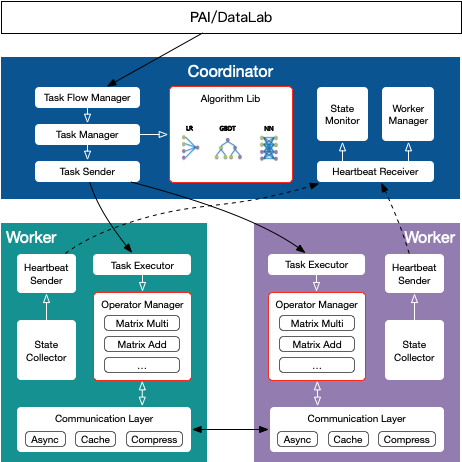
其中Coordinator部署于蚂蚁平台,用于任务的控制和协调,本身并不参与实际运算。Worker部署在参与多方安全计算的机构,基于安全多方协议进行实际的交互计算。
用户在建模平台构建好的训练任务流会下发给Coordinator的Task Flow Manager,Task Flow Manager会把任务进行拆解,通过Task Manager把具体算法下发给Worker端的Task Executor,Task Executor根据算法图调用Worker上的安全算子完成实际的运算。
利用这套方法,可以做到数据不出域就可以完成数据共享,训练工具可以部署在本地的服务器。
对金融领域的重要意义
无论是联邦学习还是共享智能,很多技术实践都优先选择了在金融领域落地。相较于其他领域,金融领域对数据的管控更为严格,对数据隐私更加重视,因此也是最需要通过技术手段解决数据孤岛问题的领域。
周俊表示,在金融领域,共享智能侧重在解决“开放”这个大领域中的问题,比如联合营销、联合风控等,这两个场景相对更容易看到具体实施效果。相比其他领域,金融领域对数据保护看的更重,数据的流转在该领域中更难,因此采用共享智能技术,可以做到更好的隐私保护,实现数据可用不可见,是一个关键的助推器。
举例来说,通过数据融合,蚂蚁金服的共享智能帮助中和农信大幅度提高了风控性能,把原来传统的线下模式,变成线上自动过审模式,完成授信只需5分钟,8个月累计放款31.9亿,授信成功人数44万人,业务覆盖20多个省区,300多县城,10000多个乡村。
落地困境如何解决?
虽然该技术的落地对金融企业有着重要意义,但很多公司在实际的落地过程中遇到了问题,可能是技术原因,也可能是处于对结果的担忧。
采访中,周俊表示,共享智能技术属于交叉领域,涉及到密码学、机器学习等技术,有一定的门槛,企业部署这样的技术,需要结合自身技术能力以及业务需求来综合考量。当然,蚂蚁金服也在积极探索降低企业落地门槛的技术和方案,随着越来越多的企业一起参与进来,相信不远的将来,共享智能的技术落地将不再会有太高的门槛。
此外,蚂蚁金服的共享智能是一个开放的生态,希望更多的企业能参与进来一起共建,而不需要重新再去走蚂蚁金服之前走过的很多弯路。金融企业可以根据自身业务发展的需要,及时跟进业界最新进展,从而选择更合适的技术和合作方来解决业务难题。能够让业务赢,解决业务痛点,是这里面最重要的因素。
更为重要的是,共享智能解决的是信任问题,所以大规模落地的前提是用户对共享智能有一个全面的认知和信任。蚂蚁金服通过立标杆、推标准、定向开源等方式来逐步建立用户对共享智能的信任。目前,蚂蚁金服已经在智能信贷领域的多家机构落地了标杆型业务场景。同时,牵头在推进共享智能的行业标准、联盟标准、国家标准以及IEEE、ITU-T等国际标准。周俊表示,我们相信,随着技术和用户心智的同步发展,共享智能的大规模落地将会很快发生,而最先受益的,是数据驱动的、并且对隐私保护有强需求的金融科技和医疗科技行业。
结束语
面向未来,周俊表示,重点还是继续推动全行业共同解决数据共享问题。蚂蚁金服会逐步开放技术能力,赋能行业中有需求的企业,同时会联合更多单位,包括研究机构、企业等共同推进解决技术难题。最终希望全行业能够共同打造一个可以在保护用户隐私和防止数据滥用的前提下实现数据互联互通的共享智能网络,更好的实现普惠金融。
专家介绍
周俊,负责蚂蚁金服机器学习算法中台,包括共享机器学习、图机器学习、自动机器学习、对抗机器学习等方向。在阿里8年多时间里,开发过阿里云-飞天分布式操作系统、大数据处理平台MaxCompute以及人工智能平台PAI,做过广告、推荐、搜索等CTR预估方面的工作,目前聚焦在将智能技术更好应用在用户增长、风险智能等核心场景上。
