蚂蚁金服技术团队
分类: IT职场
2019-12-23 09:16:03

图为 ZSearch 基础架构负责人十倍 2019 Elastic Dev Day 现场分享
ElasticSearch(简称 ES)是一个非常受欢迎的分布式全文检索系统,常用于数据分析,搜索,多维过滤等场景。蚂蚁金服从2017年开始向内部业务方提供 ElasticSearch 服务,我们在蚂蚁金服的金融级场景下,总结了不少经验,此次主要给大家分享我们在向量检索上的探索。
ElasticSearch 广泛应用于蚂蚁金服内部的日志分析、多维分析、搜索等场景。当我们的 ElasticSearch 集群越来越多,用户场景越来越丰富,我们会面临越来越多的痛点:
为了解决这些痛点,我们开发了 ZSearch 通用搜索平台:
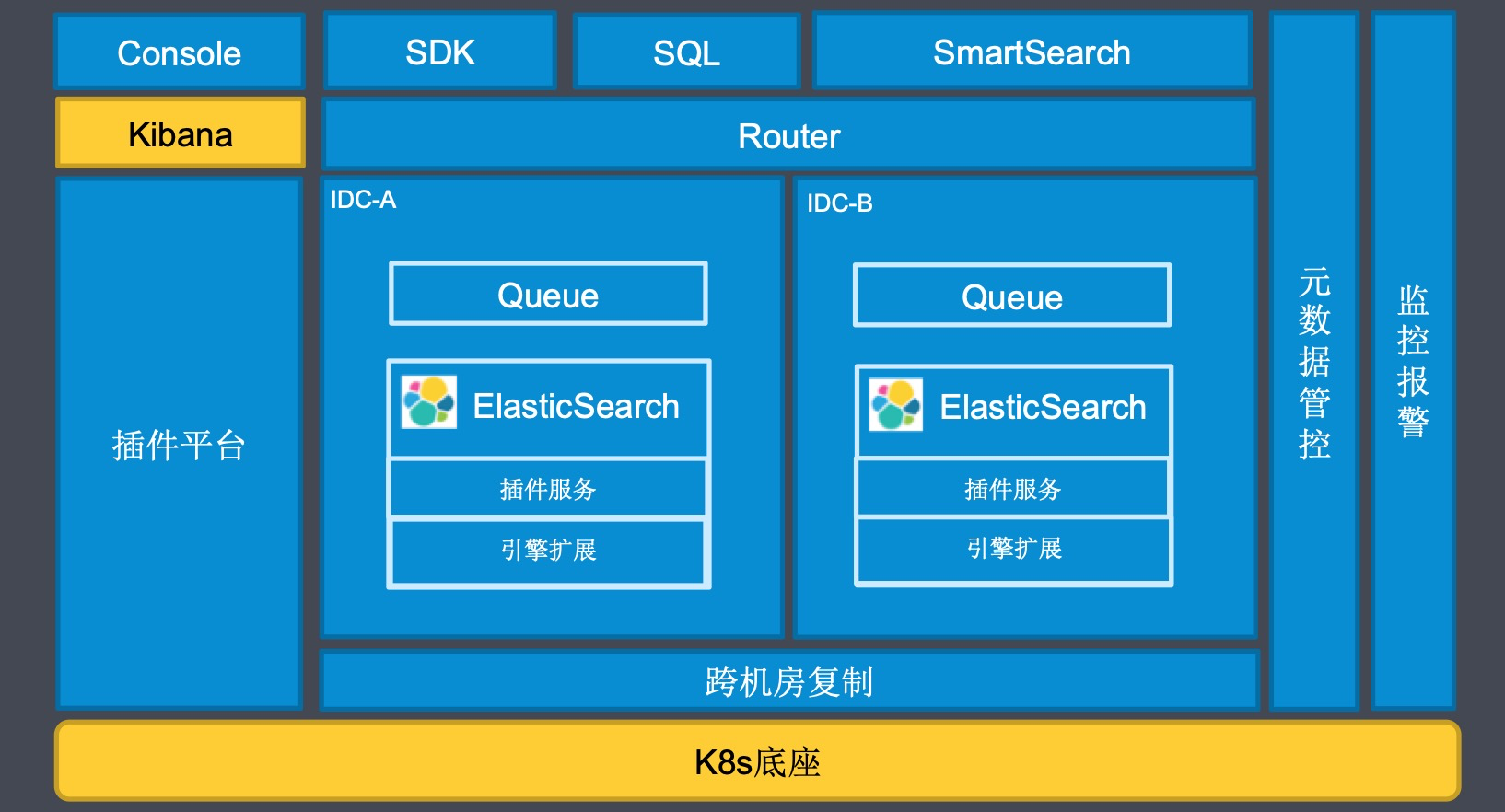
基于 ElasticSearch 的通用搜索平台 ZSearch 日趋完善,用户越来越多,场景更加丰富。
随着业务的飞速发展,对于搜索的需求也会增加,比如:搜索图片、语音、相似向量。
为了解决这个需求,我们是加入一个向量检索引擎还是扩展 ElasticSearch 的能力使其支持向量检索呢?
我们选择了后者,因为这样我们可以更方便的利用 ElasticSearch 良好的插件规范、丰富的查询函数、分布式可扩展的能力。
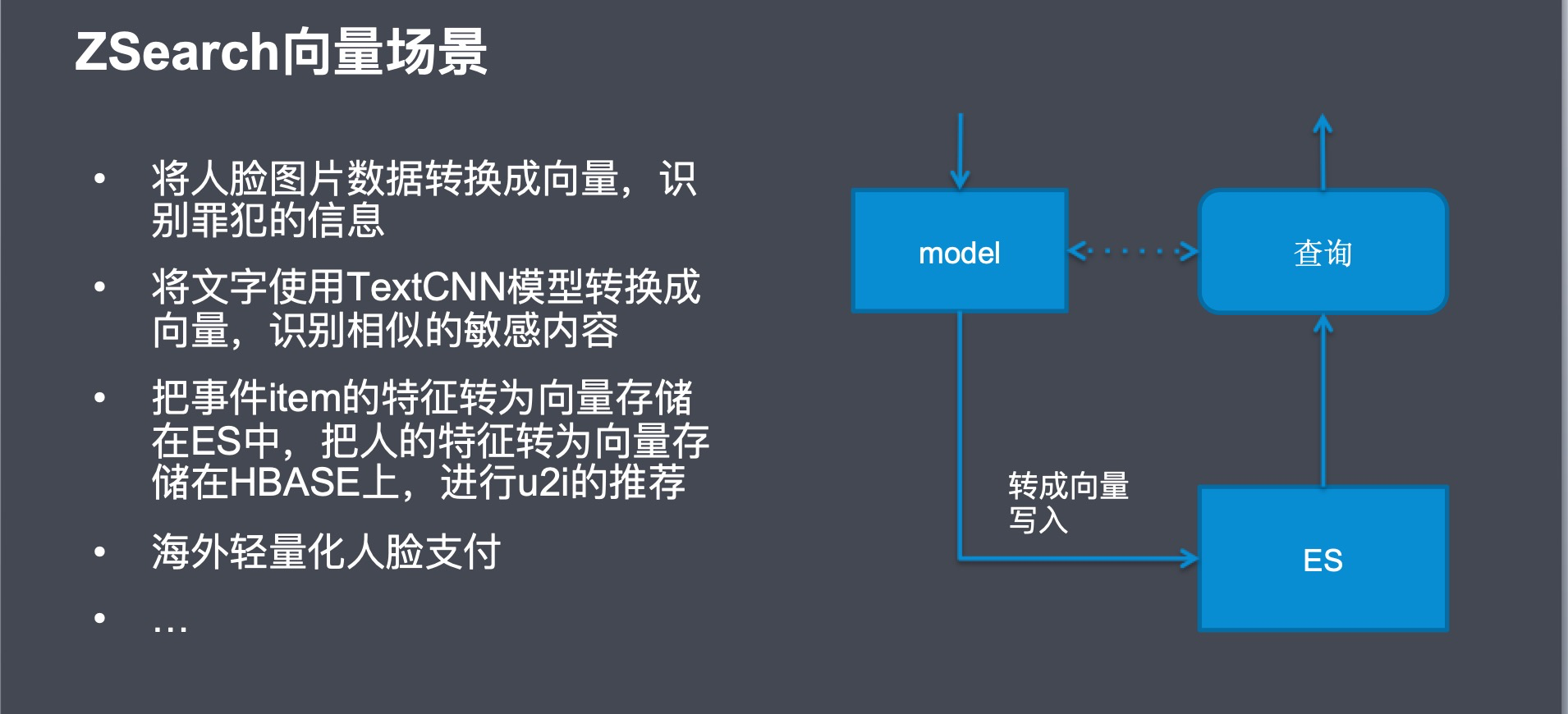
接下来,我来给大家介绍向量检索的基本概念和我们在这上面的实践。
向量从表现形式上就是一个一维数组。我们需要解决的问题是使用下面的公式度量距离寻找最相似的 K 个向量。
两点间的真实距离,值越小,说明距离越近;
就是两个向量围成夹角的 cosine 值,cosine 值越大,越相似;
一般作用于二值化向量,二值化的意思是向量的每一列只有0或者1两种取值。
汉明距离的值就两个向量每列数值的异或和,值越小说明越相似,一般用于图片识别;
把向量作为一个集合,所以它可以不仅仅是数字代表,也可以是其他编码,比如词,该值越大说明越相似,一般用于相似语句识别;
因为向量检索场景的向量都是维度很高的,比如256,512位等,计算量很大,所以接下来介绍相应的算法去实现 topN 的相似度召回。
KNN 算法表示的是准确的召回 topK 的向量,这里主要有两种算法,一种是 KDTtree,一种是 Brute Force。我们首先分析了 KDTree 的算法,发现 KDTree 并不适合高维向量召回,于是我们实现的 ES 的 Brute Force 插件,并使用了一些 Java 技巧进行加速运算。
简单来讲,就是把数据按照平面分割,并构造二叉树代表这种分割,在检索的时候,可以通过剪枝减少搜索次数。
构建树
以二维平面点(x,y)的集合(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)为例:

图片来源:https://blog.csdn.net/richard9006/article/details/90058465
查找最近点
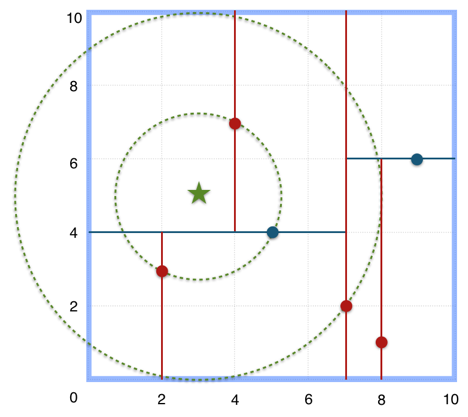
图片来源:https://blog.csdn.net/richard9006/article/details/90058465
搜索(3,5)的最近邻:
Lucene 中实现了 BKDTree,可以理解为分块的 KDTree,并且从源码中可以看到 MAX_DIMS = 8,因为 KDTree 的查询复杂度为 O(kn^((k-1)/k)),k 表示维度,n 表示数据量。说明 k 越大,复杂度越接近于线性,所以它并不适合高维向量召回。
顾名思义,就是暴力比对每一条向量的距离,我们使用 BinaryDocValues 实现了 ES 上的 BF 插件。更进一步,我们要加速计算,所以使用了 JAVA Vector API 。JAVA Vector API 是在 openJDK project Panama 项目中的,它使用了 SIMD 指令优化。
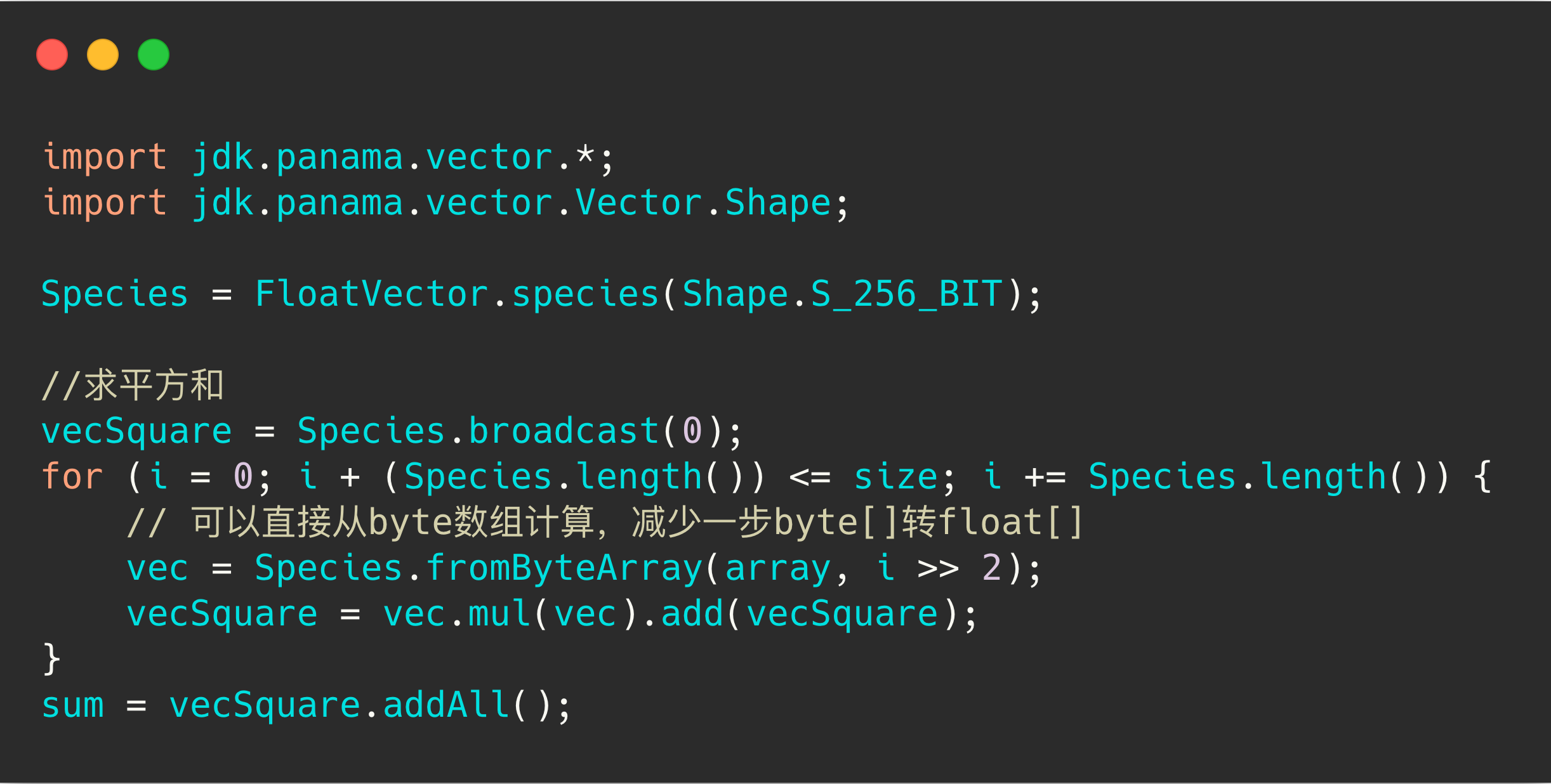
使用 avx2 指令优化,100w 的 256 维向量,单分片比对,RT 在 260ms,是常规 BF 的 1/6。 ElasticSearch 官方在7.3版本也发布了向量检索功能,底层也是基于 Lucene 的 BinaryDocValues,并且它还集成入了 painless 语法中,使用起来更加灵活。
可以看到 KNN 的算法会随着数据的增长,时间复杂度也是线性增长。例如在推荐场景中,需要更快的响应时间,允许损失一些召回率。
ANN 的意思就是近似 K 邻近,不一定会召回全部的最近点。ANN 的算法较多,有开源的 ES ANN 插件实现的包括以下这些:
ZSearch 依据自己的业务场景也开发了 ANN 插件(适配达摩院 proxima 向量检索引擎的 HNSW 算法)。
Local Sensitive Hashing 局部敏感 hash,我们可以把向量通过平面分割做 hash。例如下面图例,0表示点在平面的左侧,1表示点在平面的右侧,然后对向量进行多次 hash,可以看到 hash 值相同的点都比较靠近,所以在 hash 以后,我们只需要计算 hash 值类似的向量,就能较准确的召回 topK。

IVF-PQ 算法
PQ 是一种编码,例如图中的128维向量,先把向量分成4份,对每一份数据做 kmeans 聚类,每份聚类出256个聚类中心,这样,原始向量就可以使用聚类中心的编号重新编码,可以看出,现在表示一个向量,只需要用4个字节就行。然后当然要记录下聚类中心的向量,它被称之为码本。
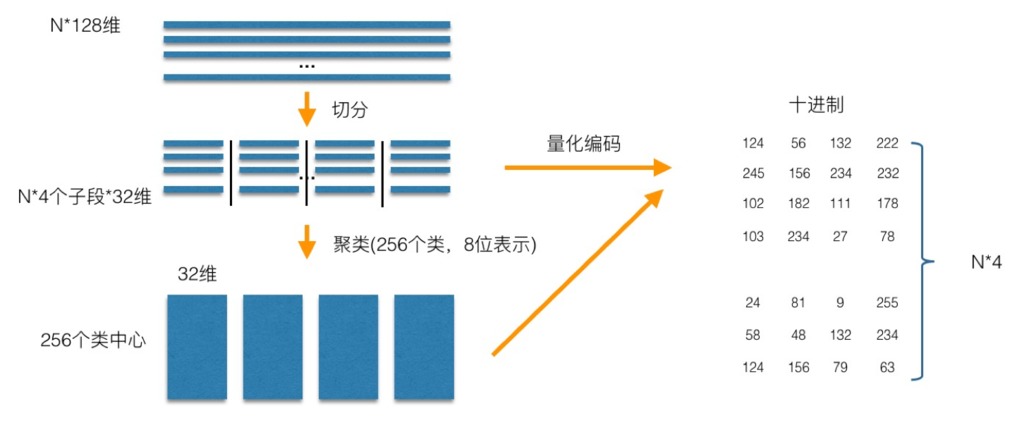
图片来源:https://yongyuan.name/blog/vector-ann-search.html
PQ 编码压缩后,要取得好的效果,查询量还是很大,所以前面可以加一层粗过滤,如图,把向量先用 kmeans 聚类成1024个类中心,构成倒排索引,并且计算出每个原始向量与其中心的残差后,对这个残差数据集进行 PQ 量化。用 PQ 处理残差,而不是原始数据的原因是残差的方差能量比原始数据的方差能量要小。
这样在查询的时候,我们先找出查询出靠近查询向量的几个中心点,然后再在这些中心点中去计算 PQ 量化后的 top 向量,最后把过滤出来的向量再做一次精确计算,返回 topN 结果。
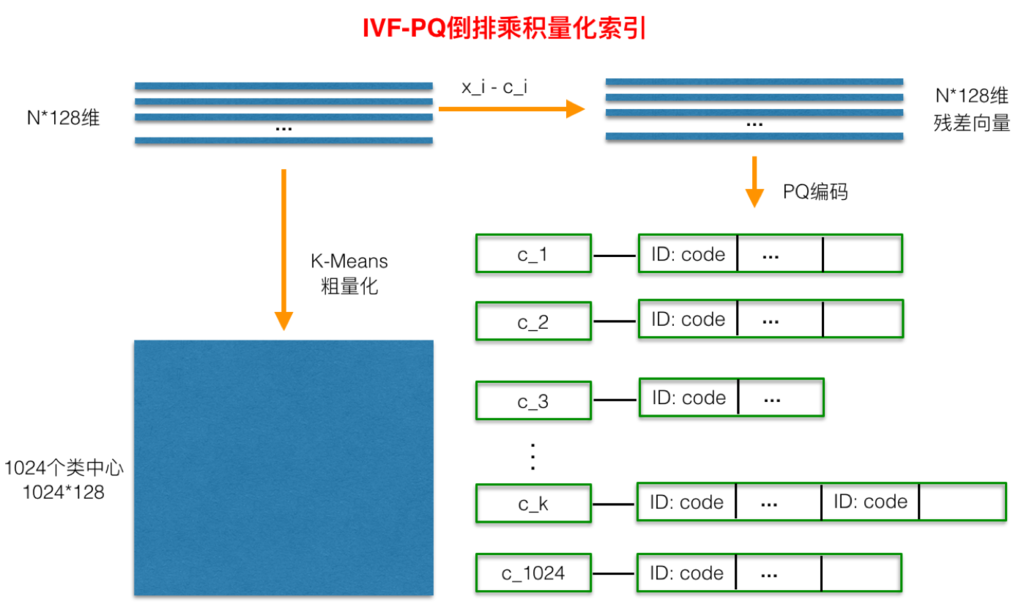
图片来源:https://yongyuan.name/blog/vector-ann-search.html
讲 HNSW 算法之前,我们先来讲 NSW 算法,如下图,它是一个顺序构建图流程:
查找流程包含在了插入流程中,一样的方式,只是不需要构建边,直接返回结果。

HNSW 算法是 NSW 算法的分层优化,借鉴了 skiplist 算法的思想,提升查询性能,开始先从稀疏的图上查找,逐渐深入到底层的图。
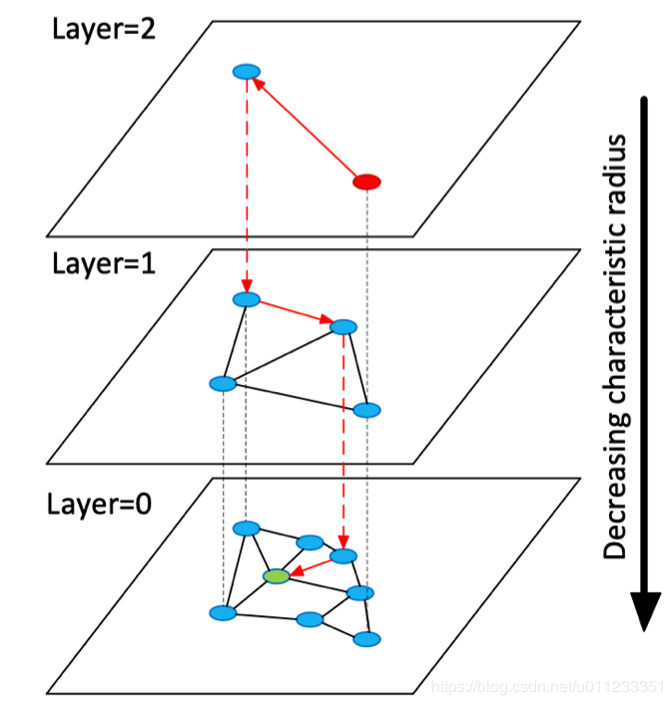
以上这3类算法都有 ElasticSearch 的插件实现:

我们根据自己的场景(轻量化输出场景),选择了在 ES 上实现 HNSW 插件。因为我们用户都是新增数据,更关心 top10 的向量,所以我们使用了通过 seqNo 去 join 向量检索引擎方式,减少 CPU 的消耗和多余 DocValues 的开销。
对接 Porxima 向量检索框架:

实现 ProximaEngine
写入流程,扩展 ElasticSearch 本身的 InternalEngine,在写完 Lucene 以后,先写 Proxima 框架,Proxima 框架的数据通过 mmap 方式会直接刷到磁盘,一次请求的最后,Translog 刷入磁盘。就是一次完整的写入请求了。至于内存中的 segment,ElasticSearch 会异步到达某个条件是刷入磁盘。
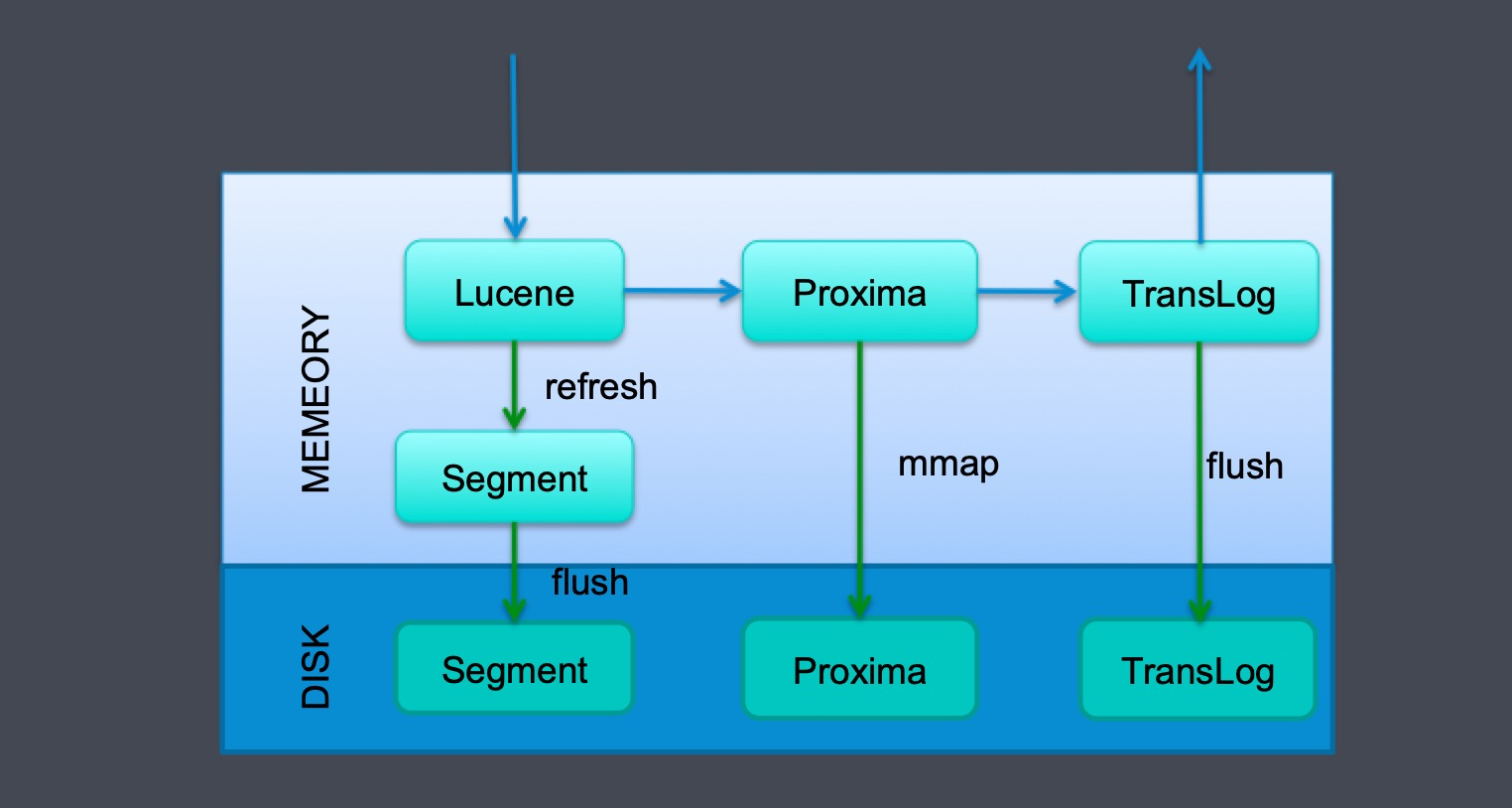
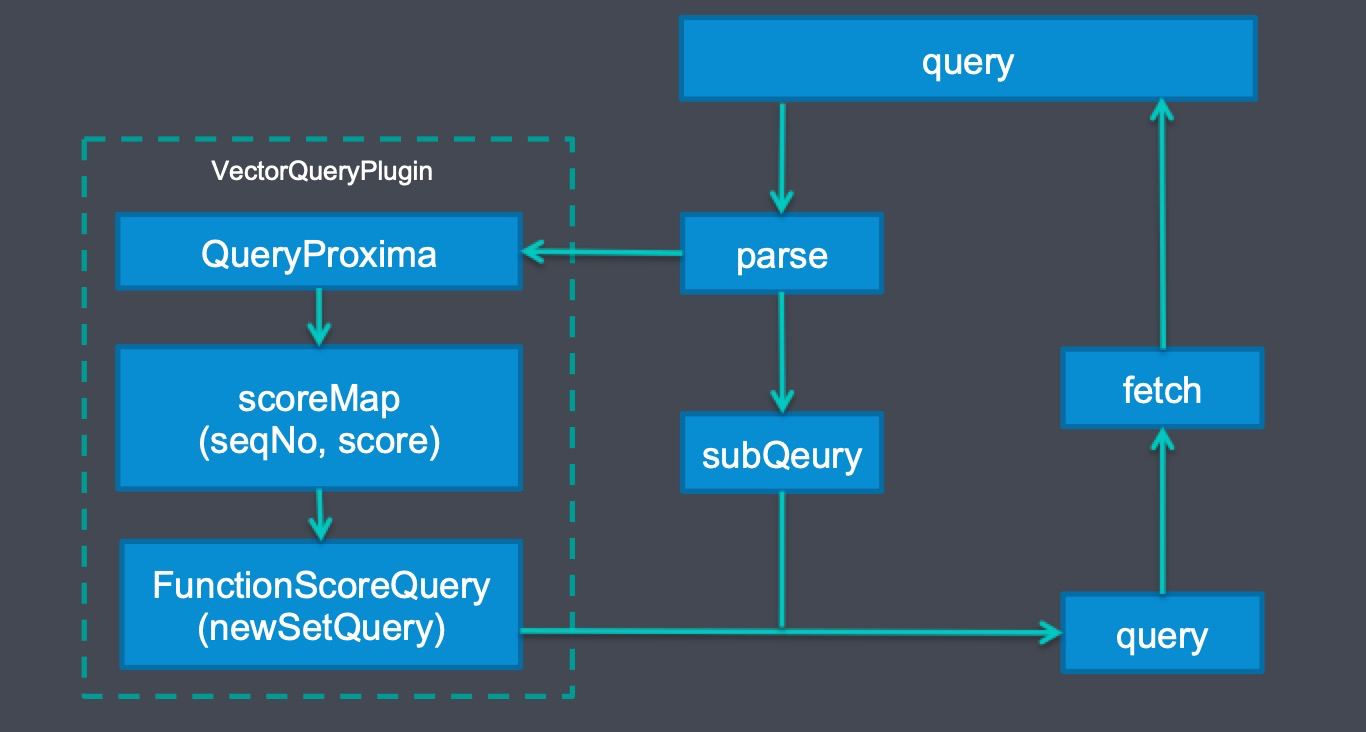
Query 流程
查询的时候,通过 VectorQueryPlugin,先从 proxima 向量检索引擎中查找 topN 的向量,获得 seqNo 和相似度,再通过构造 newSetQuery 的 FunctionScoreQuery,去 join 其他查询语句。
这里的数字型 newSetQuery 底层是通过 BKDTree 去一次遍历所得,性能还是很高效的。
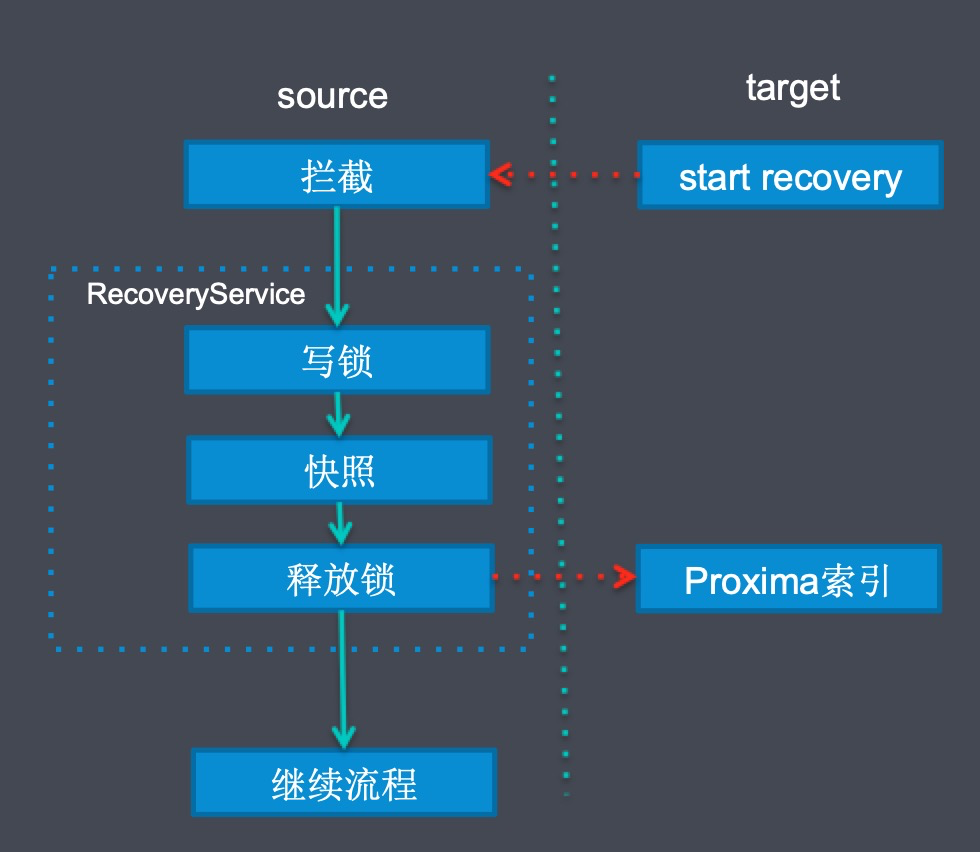
Failover 流程
当然我们还要处理各种的 Failover 场景:
我们拦截了 ElasticSearch 的 recovery action;
然后生成 Proxima 索引的快照,这个时候需要通过写锁防止数据写入,快照生成由于都是内存的,其实非常快;
把 Proxima 快照复制到目的端;
再进行其他 ElasticSearch 自己的流程;
sift-128-euclidean 100w 数据集()

所以更大的堆外内存分配给 pagecache;
例如 8C32G 的机器,JVM 设置 8GB,其他 24GB 留给系统和 pagecache;
6.x 默认为节点数*5,如果单节点 CPU 多,可以设置更大的 shards,并且调大该参数;
数据量小(单分片100w以下);
先过滤其他条件,只剩少量数据,再向量召回的场景;
召回率100%;
数据量大(千万级以上);
先向量过滤再其他过滤;
召回率不需要100%;
LSH 算法: 召回率性能要求不高,少量增删;
IVFPQ 算法:召回率性能要求高,数据量大(千万级),少量增删,需要提前构建;
HNSW 算法: 召回率性能要求搞,数据量适中(千万以下),索引全存内存,内存够用;
深度学习里的算法模型都会转化成高维向量,在召回的时候就需要用相似度公式来召回 topN,所以向量检索的场景会越来越丰富。
我们会继续探索在 ElasticSearch 上的向量召回功能,增加更多的向量检索算法适配不同的业务场景,将模型转化成向量的流程下沉到 ZSearch 插件平台,减少网络消耗。希望可以和大家共同交流,共同进步。
吕梁(花名:十倍),2017年加入蚂蚁金服数据中间件,通用搜索平台 ZSearch 基础架构负责人,负责 ZSearch 组件在 K8s 上的落地及基于 ES 的高性能查询插件开发,对 ES 性能调优有着丰富的经验。
