蚂蚁金服技术团队
分类: IT职场
2019-11-04 09:18:31
去年春节期间支付宝推出的集五福的活动可谓风靡一时,每张福卡背面都有刮刮卡,里面有来自蚂蚁金服、阿里巴巴以及合作伙伴的上百种权益。集五福的活动集中在春节前的几天,具有很强的时效性。所以如何实现权益和投放人群的自动匹配,解决系统的冷启动问题,优化转化率和提升用户体验,就成了一个在线学习的优化问题。
之前我们搭建一个这样的系统需要的模块非常繁杂。我们需要日志收集、数据聚合、样本的拼接和采样等流处理任务,需要对接模型训练、模型验证等机器学习模块,需要有把模型实时加载的模型服务,还需要其他的配套设施等等。众多模块的衔接极大地增加了系统的复杂性。

由于涉及的系统比较多,我们之前的系统遇到了比较多的问题。比如大促时为了保证高优链路的稳定性,上游某些数据处理的链路就会被降级了,但下游同学并不知情。另外一个很常见问题的是流批逻辑不一致,需要离线特征来训练基准模型,同时在线计算的特征来对模型进行实时更新。这两个模块一个在离线一个在线,曾经出现过处理逻辑的细微差别对业务效果造成了很大的影响。
总结下来,我们曾经遇到的坑可以归结为三类:
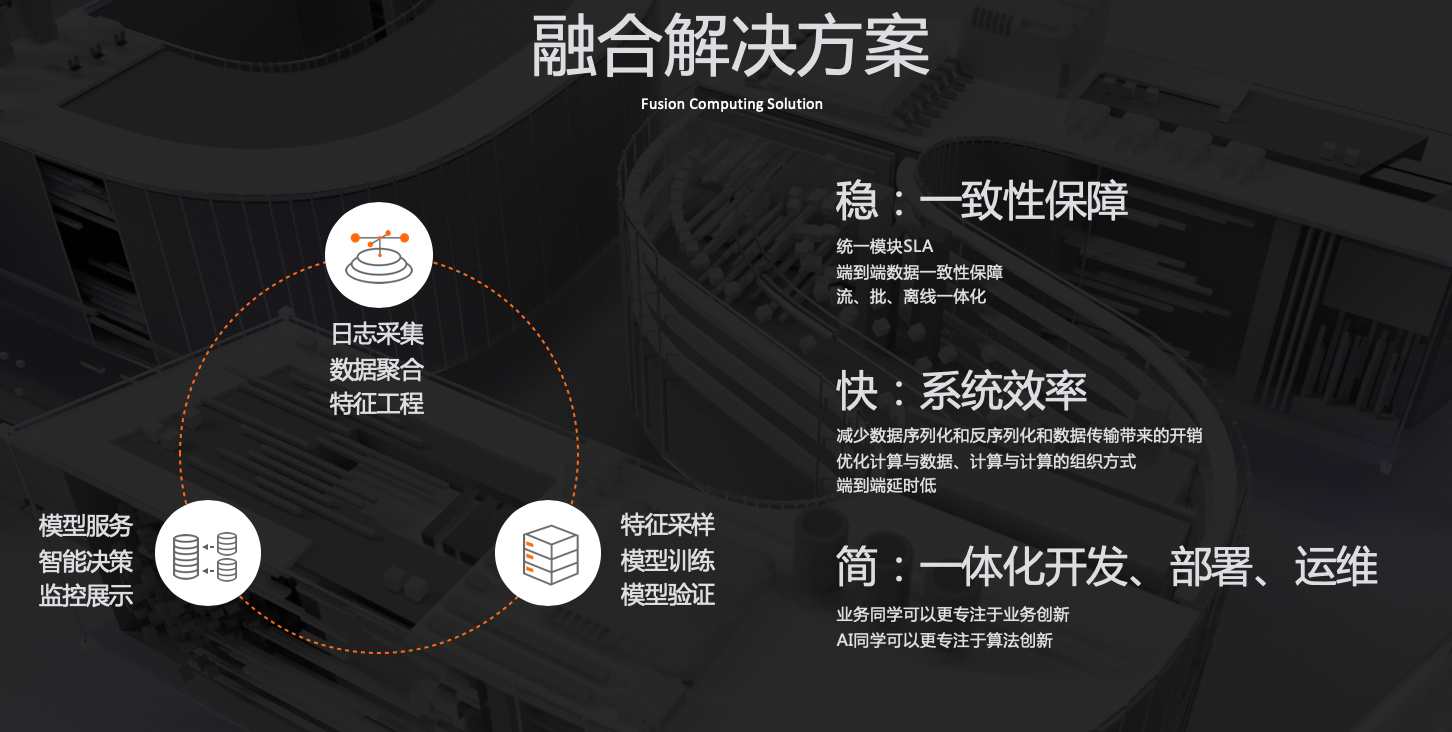
一个理想的系统应该提供什么样的能力呢?可以从“稳快简”三个方面来讲:首先从数据来讲它需要保证数据和计算一致性,实现整个链路端到端的SLA,数据一致性和链路的稳定是保障业务稳定的基础。第二是我们需要去优化系统效率,我们希望把这十几个系统的衔接转换成系统内部的衔接,希望把这些作业调度转换成任务的调度,通过这样转化我们希望把计算与计算之间协同调度,从而提高系统效率和降低网络带宽使用的目的。一个融合的系统也可以对开发和运维提供非常大的便利,以前需要对接十几个系统,现在只要对接一个系统就可以了。以前我们在应急的时候需要回溯好几个业务来发现问题,现在融合在一起的系统调试也会更加容易。
在线机器学习最外层需要透出数据处理、模型训练、模型服务三个能力。这三个能力反映到对计算引擎框架上的需求是敏捷的调用机制、比较灵活的资源管控,以及比较完善的容错机制。上层的系统往往是通过不同编程语言来实现的,因此还需要有多语言接口。通过对底层需求的考量以及现在各框架的特点,最后我们选择了Ray为融合计算的底座。

Ray是由伯克利大学RiseLab实验室发起,蚂蚁金服共同参与的一个开源分布式计算框架,它提出的初衷在于让分布式系统的开发和应用能够更加简单。Ray作为计算框架可以帮我们实现上面“稳快简”三个目标。Ray作为计算框架具有敏捷的调度机制,用它可以一秒钟进行上百万次任务调度,它也可以根据计算对资源使用的需求实现异构调度。
在目前比较流行的分布式框架,都有三个比较基础的分布式原语,分布式任务、对象和服务。而我们常用的面向过程的编程语言中,也刚好有三个基本概念,函数、变量和类。这三个编程语基本概念刚好可以和分布式框架的原语对应起来。在Ray系统中,可以通过简单的改动,实现他们之间的转换。

左边是一个简单的例子,在这个函数前面需要加入一个“@remote”修饰符,就可以把一个函数转换成为分布式任务。任务通过“.remote”调用执行,返回值是一个变量,又可以参与到其他计算中。
右边是另一个例子,通过加“@remote”修饰符的方式可以把一个类转变成服务。类中的方法可以通过“.remote”调用变成一个分布式任务,和函数的使用非常相似。通过这种方式可以实现从单机程序到分布式任务的转变,把本地的任务调度到远程的机器上进行执行。

Ray上应该做怎么样的调度,衡量指标就是系统的效率问题,系统的效率很多时候取决于计算和数据的组织方式,比如说我们要计算Add(a,b),首先这个函数在本地会被自动注册并且提供给本地调度器。之后通过全剧调度器和第二个节点的本地调度器一起协同工作,把A备份到第二个节点执行Add这个操作。它还可以根据A和B的数据大小来进行进一步的调度和控制优化,A和B可以是简单数据类型,也可以是比较复杂的变量或者矩阵。
Ray上面提供多语言API接口。由于历史原因,在蚂蚁金服内部流式计算使用最多的语言是Java,而机器学习建模比较普遍使用的语言是Python。我先希望重用Java语言实现的流处理算子,同时保留Python进行机器学习建模的便捷性。Ray上面提供这样的多元化支持就非常方便我们做这个事情,用户在上层开发的时候可以可以方便地使用Java和Python分别进行流处理和机器学习模型的开发
对于在线机器学习来说,它最核心需要解决的问题是要打通流计算和模型训练,那我们需要使用一个介质,这个介质能够比较方便的将两者衔接在一起。之前我们介绍Ray的几个特点,如提供多语言的接口、灵活的调动机制,这是因为这两个特点在Ray上可以比较方便做这个事情,Ray可以起到衔接的作用。数据处理的最后一个节点是流计算的输出,worker节点消费数据,是模型训练的输入。Ray就可以通过调度机制把这两个计算调度在一个节点上,实现数据共享从而实现两个模式的打通。通过这种方式不仅可以兼容流计算和机器学习,也可以将其他模式进行衔接。
计算中DAG概念最开始是为了解决多阶段分布式计算的效率而提出的,主要思想是通过调度减少计算时的IO。但是以前的计算DAG,在任务执行的时候它就已经确定了,但我们在机器学习的任务里面,很多时候我们会需要设计新的模型,或者对模型的超参进行调试,我们希望看到这些模型能被加载到链路上,看到业务效果的同时又不想线上已经有的模型的训练和服务被中断。在Ray系统内部,计算的过程中可以动态的生成另外一个节点,我们可以利用这个特性来增点和变,从而动态的对DAG进行局部修正。

在线系统和离线系统之间比较大的区别,在于如果一个离线系统里的任务挂了,一般来说可以通过重启机器的方式来解决,但对在线系统来说,出于时效性的考虑,我们不能简单的通过重启机群回溯数据的方式来解决。因此就需要有比较完善的容错机制。我们在模型训练的时候可以利用Ray的Actor来拉起模型训练的worker和server节点。如果worker或者server节点处于不健康状态,我们就可以利用Actor的容错特性通过血缘关系来对数据和计算进行恢复,从而实现容错的训练。

我们比较追求链路的时效性,模型能够尽快的拟合实时数据里。但是追求时效性的同时也要保证整个链路的稳定性,在敏捷和敏感之间达到平衡。我们从三个方面,系统稳定性、模型稳定性、机制稳定性来保障整个链路的稳定性。
除了之前用Ray来实现融合以及它带来的好处,我们也做了非常多的模块建设,TF融合、稳定性保障、样本回流、延迟样本修正、数据共享、流批一体、端到端强一致、模型增量导出。我们把这个平台上线了支付宝的几个场景,从下面的几个数字可以一探效果:
我们从去年8月份开始建设,今年2月份开始上线第一个场景,在支付线财富线也都取得了不错的效果,接下来我们会推广到蚂蚁金服的其他业务线上。

基于融合计算机器学习,它是融合计算和机器学习这两种模式的有机组合,实现优化资源共享。我们通过这两方面的探索初步验证了融合计算的框架,融合计算是旨在数据共享来进行计算模式的兼容,融合的本质是开放,开放的基础是实现数据的互通,只要我们能够方便的实现各模式之间的数据互通,并且能够保障它们数字的实时性和端到端的一致性,就可以实现复杂场景里面需要多种模式进行组合的计算。模块的衔接就像搭乐高积木一样,基本的模块可能只有几种,但是搭建出复杂且多变的系统。
