蚂蚁金服技术团队
分类: IT职场
2019-10-30 09:21:23
蚂蚁金服过去十五年,重塑支付改变生活,为全球超过十二亿人提供服务,这些背后离不开技术的支撑。在 2019 杭州云栖大会上,蚂蚁金服将十五年来的技术沉淀,以及面向未来的金融技术创新和参会者分享。我们将其中的优秀演讲整理成文并将陆续发布在“蚂蚁金服科技”头条号上,本文为其中一篇。
今年 4 月,蚂蚁金服董事长兼 CEO 井贤栋在参与第二届一带一路国际合作高峰论坛时表示,通过九年的实践,蚂蚁金服改善了中小企业的融资渠道并形成了 310 模式,即 3 分钟在线申请、1 秒钟审核放款、0 人工干预。与此相对的是,仅仅在两年前,有相关人士表示,他们出台的 310 模式却是 3 周申请,1 月审核,0 几率获贷。
那么,蚂蚁金服是如何通过不断探索应用金融新技术,为中小企业提供融资便利,其中的 1 秒钟审核放款,又是如何做到的呢?在这里,我们来谈谈其中非常关键的一项核心技术,在线图计算技术。
在线图计算就是将流式计算与图计算结合起来,能做到进行实时的图计算的技术。蚂蚁金服在这个方向上经过多年研发,在关键技术上做出了突破性的创建,并形成了面向金融场景的解决方案。
蚂蚁研发在线图计算技术,是因为金融场景需要这样的技术来解决问题。
比如,在金融风控中的实时反套现场景。套现,指的是采用违法或者虚假的手段交换而获取现金利益的行为,一般多用于信用卡和公积金等场景。
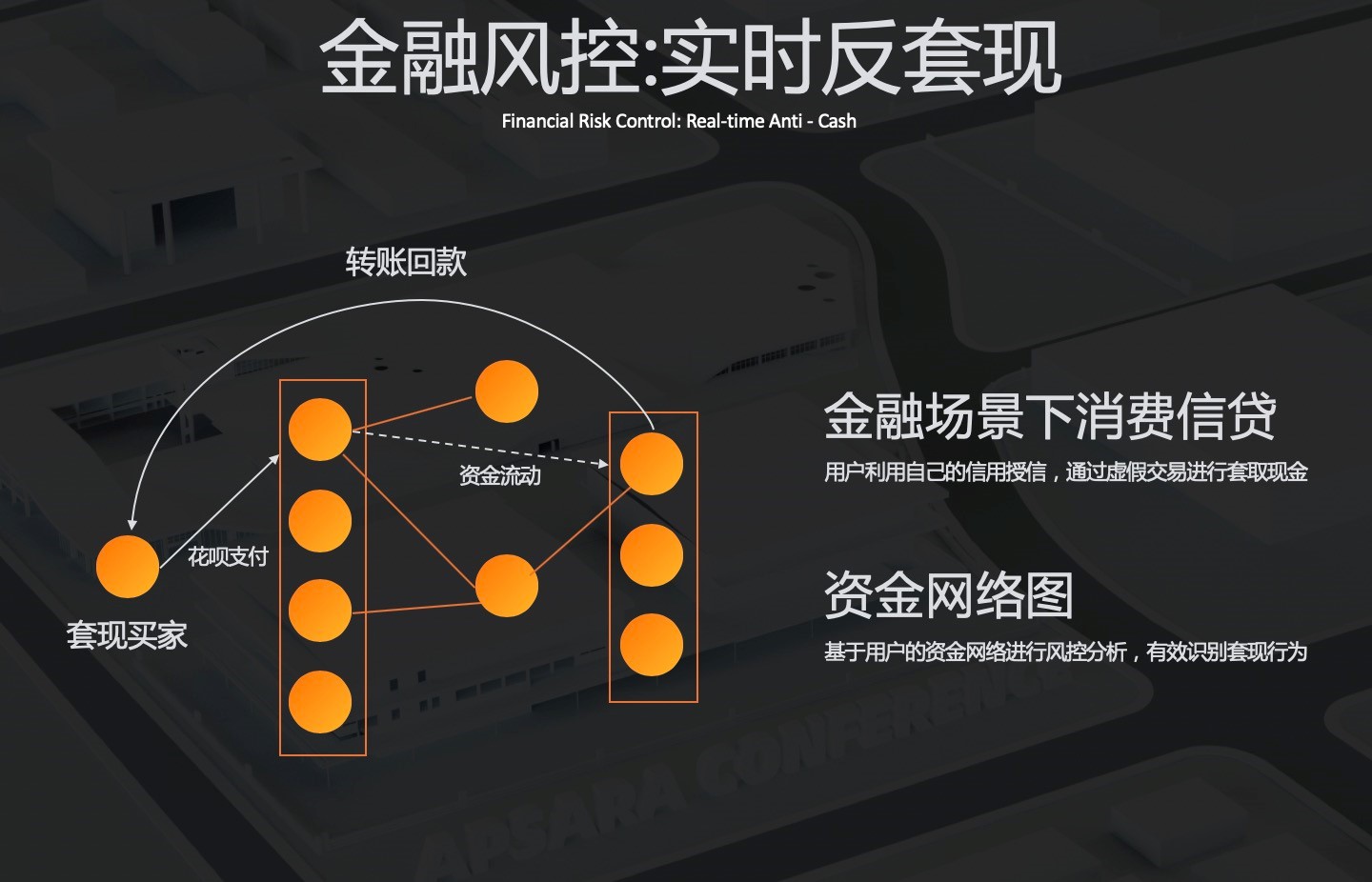
花呗是一个消费信贷类产品,用户可以基于花呗的额度消费,并定期还款。花呗反套现是花呗整体风控中非常关键的一个环节,如何实时的、准确的识别套现行为则是花呗反套现的关键。
如图所示,套现的买家通过花呗进行一笔交易的支付,并通过一系列复杂的资金流动,最终通过转账回款进行资金的套现。
通过数据建模,将整体的资金流动抽象成资金关系网络,基于资金关系网络之上进行子图的识别和分析,从而有效的识别套现行为。
通过实时反套现的例子,我们可以得到在线图计算的三个基本需求:
再说说大家比较熟悉的蚂蚁森林场景。
蚂蚁森林中有多种形式的好友互动,如支付宝好友之间可以互相收取能量,以及好友、亲人之间可以一起合种一棵树。
在蚂蚁森林中有人与人的关系,以及人与树的关系等。它不仅需要支持实时的关系数据构建,还需要支持高性能低延迟的关系数据查询和一致性的关系数据修改等需求。
通过蚂蚁森林的例子,我们也可以得到在线图计算其他三个需求。
通过前面实时反套现和蚂蚁森林的例子,我们对金融级的在线图计算的需求做一下简单的总结。
我们将需求分成两部分,第一部分是功能需求:
第二部分是稳定性需求,由于金融场景的特性,所以稳定性显得尤为重要。这里主要列举两点:
在介绍完蚂蚁金服在线图计算相关的场景和需求之后,我们来一起了解下蚂蚁金服在线图计算的核心关键技术及过程中的思考。
首先,我们来一起看下蚂蚁在线图计算的整体架构图。
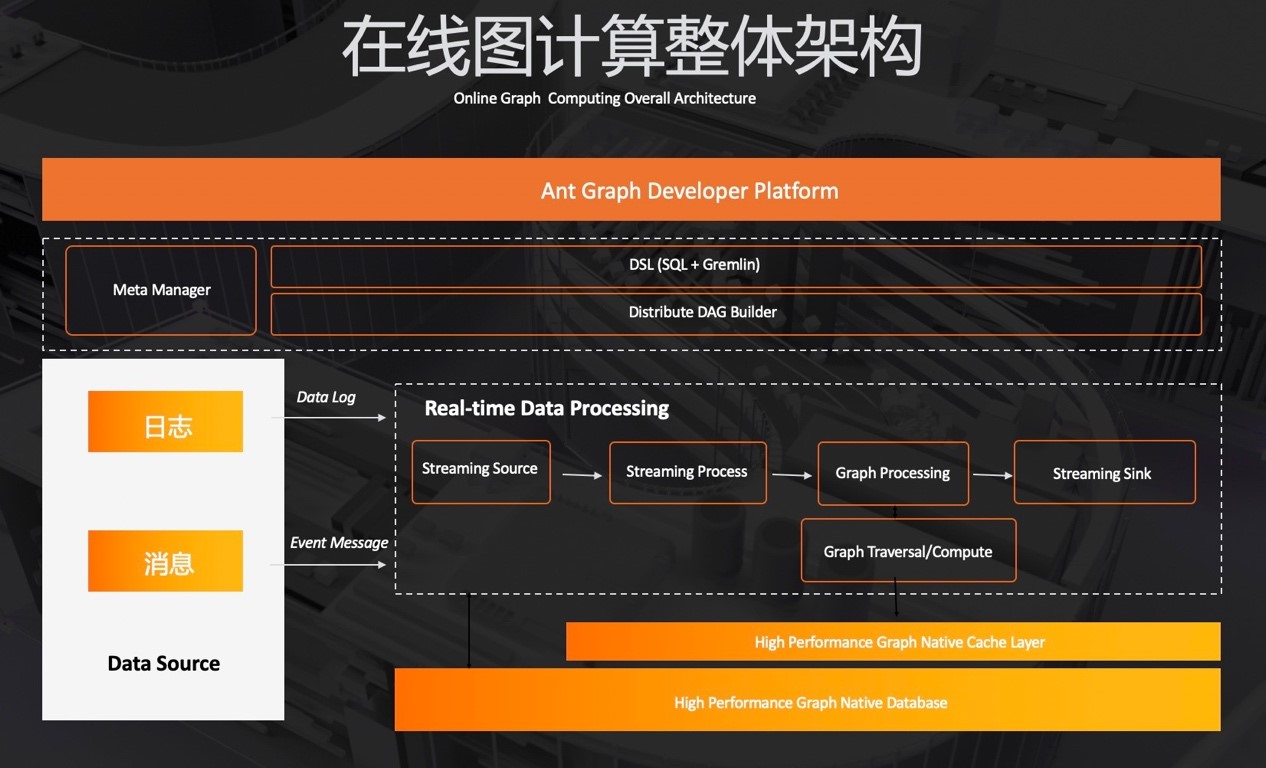
在最上层,蚂蚁在线图计算提供一套统一的图开发平台。基于统一的图开发平台,用户可以基于关系元数据和统一的 DSL 进行作业的开发。目前统一的 DSL 主要通过 SQL 和 Gremlin 融合的方式进行编程开发。同时基于用户的 DSL,会实时的构建分布式的 DAG 进行运行。
构建完成后,分布式的任务会实时的对线上的日志数据和事件数据进行实时的处理。这里主要包含两条链路,一条链路会基于实时处理完成的日志数据和事件行为会写入到高性能的图数据库,并基于数据实时的构建高性能的图缓存,提供快速高效的子图抽取。
另外一条链路则会基于实时处理的数据,来动态的决策是否需要一个图的 Traversal 和计算,并在计算的过程中,从高性能缓存快速的抽取子图进行计算,最后将计算的结果输出提供在线使用。
通过前面的架构图,可以看到,蚂蚁的金融级在线图计算主要有三个技术方向:
下面,我们来分布分布介绍一下这三个方向的核心技术点。
第一个关键技术是:流图融合计算。
以花呗反套现的场景为例,并不是每一笔交易或回款行为都需要进行套现行为的识别,需要先进行一定的规则的处理。比如,基于实时的统计交易的笔数或者回款的金额,在满足一定的条件后才开始进行子图的迭代计算。最后,基于图的迭代计算的结果,在进行数据链路的处理后再提供给在线使用。因此,一个场景在完整的计算链路中,需要流计算和图计算两种模态的融合计算。
在传统的计算方式中,则会通过流计算和图计算进行组合的方式来实现全链路,比如通过 Flink、GraphX、Neo4j 等多个系统进行串联。 但是通过传统的方案,用户需要学习多套系统,并且需要维护多套系统进行衔接。而且由于多套系统衔接,因此会产生额外的数据存储和延迟。因此,在蚂蚁金服,我们打破计算模态的边界,将流计算和图计算进行融合,提供流图融合的计算系统。用户可以通过一套 API、一套计算系统来实现完成流图融合的链路,由于是一套系统,同时能减少用户的运维成本。

动态DAG
在提供了融合计算和动态计算的能力之后,如何让用户进行快速便捷的开发显得尤为重要。
这里我们通过 SQL Plus(Gremlin)的方式进行融合计算的开发,用户可以通过 SQL 来构建整体的 Pipeline 的流程,同时,引入 GraphView 的概念,基于 SQL 可以离线和实时的构建 Graph View。基于 GraphView 之上,可以通过 SQL+Gremlin 实现基于数据驱动的在线图计算能力。

同时,由于 SQL 大部分开发者都比较熟悉,可以减低用户的学习、开发、调试的门槛,易学易用。目前蚂蚁金服也在关注最新的图查询语言国际标准 GQL,未来也会融入于此。
基于以上三个特性,用户可以快速的构建流图的一体化作业。
接着,用户在上线一个算法策略的同时,则需要对策略进行验证,这里用户需要针对流式的数据进行有效的仿真,来判定当前的算法是否有效。
基于当前的在线图计算架构,我们可以通过模型的有效抽象,将历史的图数据和请求进行有效的回放来实现仿真和在线的一体化架构能力。
与此同时,由于仿真的特性,会对历史版本的数据快照进行访问,从而会引起图数据存储的加速膨胀。 由于这里采用流式回放的方式进行仿真,我们可以通过基于驱动的数据 GC 策略,从而避免数据的过量膨胀。 同时,基于多级缓存的策略,从而实现提升图仿真的吞吐能力。
以上就是融合计算方向的四个关键技术,通过以上的四个特性,用户可以高效、方便的进行任务的构建和计算。
接下来,会讨论如何快速的进行子图构建。
这里重点介绍一下蚂蚁的高性能图缓存,基于完美 Hash 函数和专业的压缩能力,将数据缓存在内存中进行在线服务,从而实现子图场景下的低延迟和高吞吐。
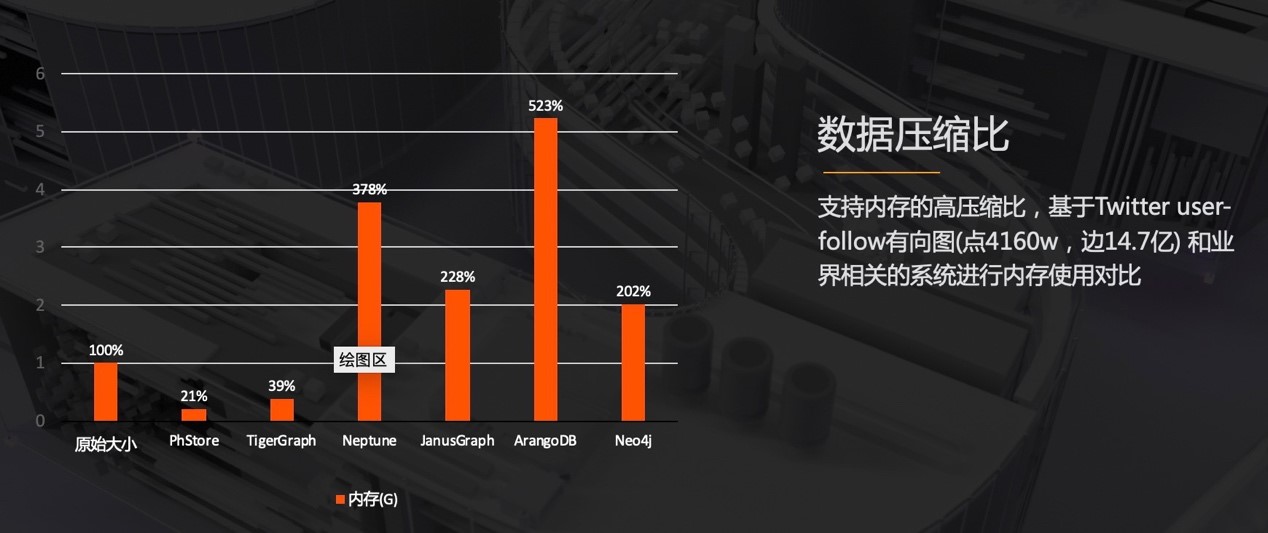
针对高性能的图缓存,内存的占用显得尤为重要。这里重点看下蚂蚁图缓存和业界系统的压缩比对比图。这里采用的是基于 Twitter 的 User-Follow 的开放数据集。
可以看到,由于图的关联特性,所以业界开源的系统在原始图的基础上,都有一定程度的放大,而业界做得比较好的 TigerGraph 做到了相对于原始大小的 40% 左右的内存使用。而蚂蚁的图缓存可以实现 20% 的原始内存大小。比目前业界最佳,还要节省一半的内存使用。
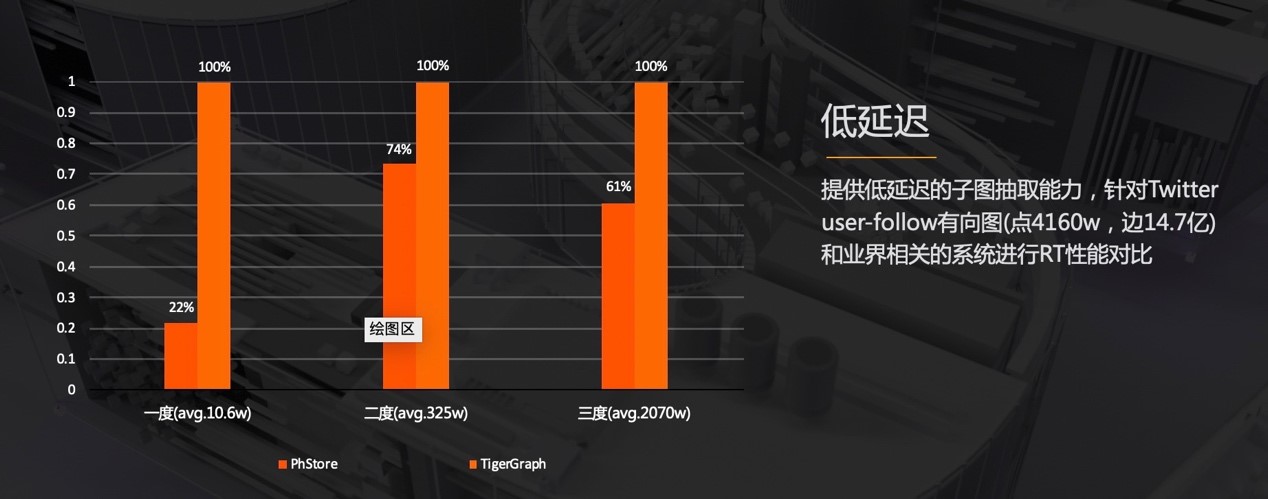
通过高压缩比,我们将图数据完整的存放在内存中,下面我们可以对比一下子图抽取的 RT 性能。
同样是基于 Twitter 的 UserFollow 的数据,可以看到在 1 度、2 度、3 度的场景下,特别是 1 度的场景,整体的时间延迟仅是 Tiger Graph 的 20% 左右。
通过高性能图缓存,针对子图的高性能查询,才能实现在线的实时链路计算。
下面我们来看下,如何实现金融场景下的高可靠和一致性的能力需求,这里重点介绍下蚂蚁的金融级图数据库 GeaBase。
GeaBase 内部通过实现 Mirco Shards 的方式来实现数据分片。并基于 Mirco Shard 的数据分片实现 Cost-Base 的数据迁移和自动的负载均衡。同时,借助于蚂蚁的基础架构体系,实现了三地五中心的城市级容灾策略。
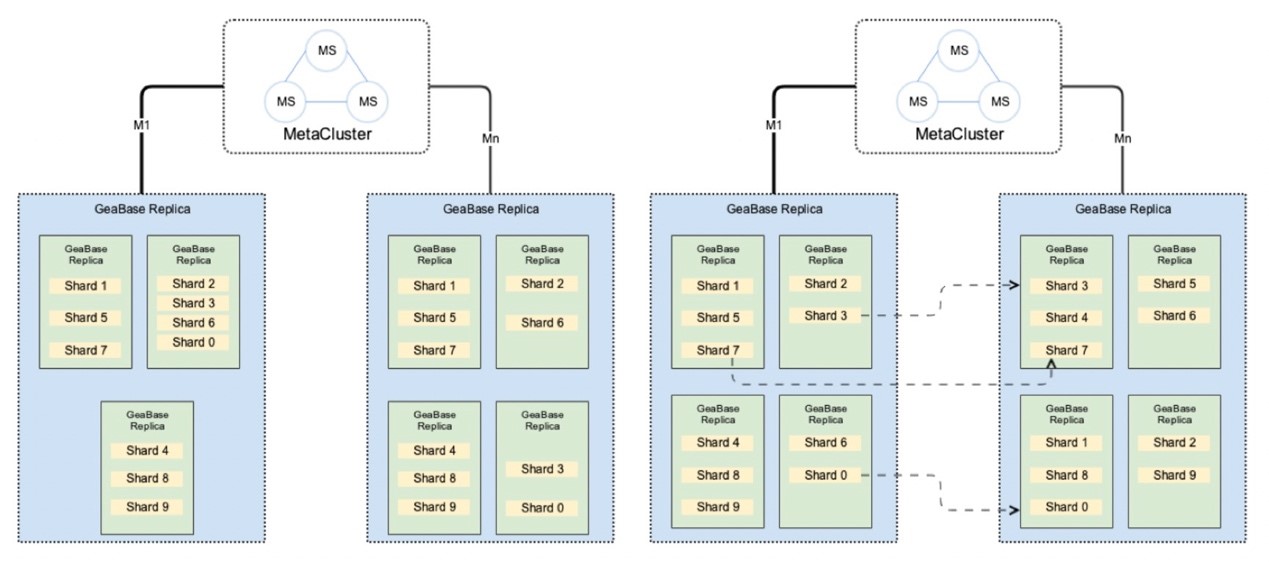

通过对比,我们可以看到,在单机、单副本和机房级故障时,GeaBase 的灾备能力均优于 HBase。与此同时,在城市级容灾的场景下,GeaBase 可以实现数据的恢复和不丢失。
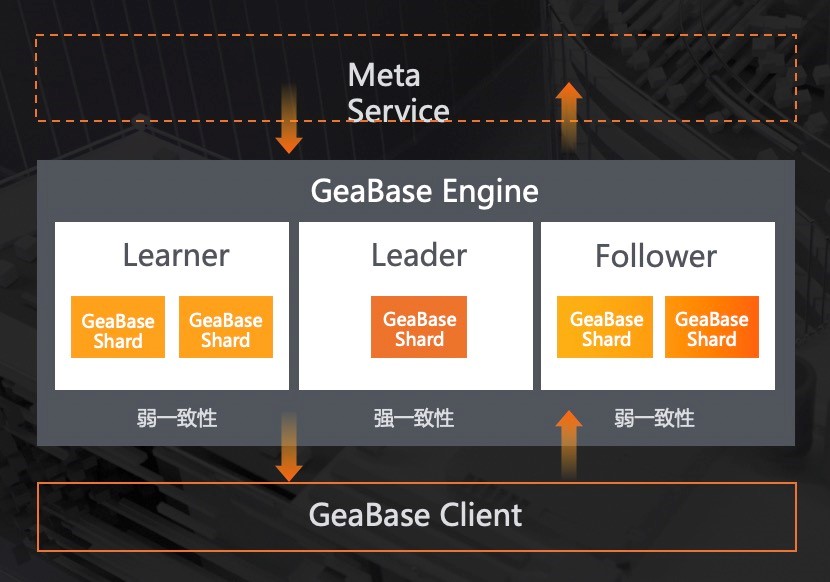
与此同时,GeaBase 还实现了一致性的能力,来满足金融场景的数据强一致性的需求。GeaBase 通过实现 Raft 协议来实现数据的一致性。并且可以让业务根据自身业务需求自由选择,是最终一致性还是强一致性。
蚂蚁的在线图计算目前广泛应用于蚂蚁的多条业务线,支持了风控、社交和营销等 100 多个业务场景。当前在蚂蚁内部有 2000 多台机器的集群规模 7*24 小时运行。
与此同时,蚂蚁逐渐把这些能力输出给外部金融级客户,如常熟农商银行和泰隆银行。比如在常熟农商银行,蚂蚁金服与行方联合共研了蚁燕知识图谱项目,基于蚂蚁研发的在线图计算技术,在大数据量环境下,通过海量关联分析,提前进行担保关系预判,实现担保圈风险的秒级预判和风险提醒,有效管控风险的同时,切实提高了信贷审批效率。蚂蚁金服不仅自己实现了 310,还通过合作输出给客户,为实现普惠金融而努力。
未来,蚂蚁金服会继续打磨在线图计算的技术能力,并向更多的合作伙伴开放,一起将在线图计算推广到更多的场景中去。
