蚂蚁金服技术团队
分类: 网络与安全
2019-08-22 10:26:58
如果有A、B、C三位同学,他们各自手上有10、15、20块钱,这时需要在相互不知道对方有多少钱的情况下,不借助力第三方来计算三个人一共有多少钱。请问这时候,我们如何实现呢?——这,就是最经典的秘密共享场景。在看完这篇文章后,答案就出来了~
背景
互联网时代,一切基于数据。
随着人工智能的兴起,数据的质量和数量,已经成为影响机器学习模型效果最重要的因素之一,因此通过数据共享的模式来“扩展”数据量、从而提升模型效果的诉求也变得越发强烈。
但在数据共享过程中,不可避免会涉及到两个问题:隐私泄露和数据滥用。
提到这两个关键词,大家一定都对其背后的缘由有所耳闻:
随着对数据安全的重视和隐私保护法案的出台,以前粗放式的数据共享受到挑战,各个数据拥有者重新回到数据孤岛的状态,同时,互联网公司也更难以收集和利用用户的隐私数据。
数据孤岛现象不仅不会消失,反而会成为新的常态,甚至它不仅存在于不同公司和组织之间,在大型集团内部也存在。未来,我们必须面对这样的现状:如果我们想更好的利用数据,用大数据和AI做更多有意义的事情,就必须在不同组织之间、公司与用户之间进行数据共享,但这个共享需要满足隐私保护和数据安全的前提。
隐私泄漏和数据滥用如同达摩克利斯之剑悬在各个公司和组织头上,因此解决数据孤岛,成为AI行业需要解决的首要问题之一。
当前,业界解决隐私泄露和数据滥用的数据共享技术路线主要有两条。一条是基于硬件可信执行环境(TEE: Trusted Execution Environment)技术的可信计算,另一条是基于密码学的多方安全计算(MPC:Multi-party Computation)。
TEE字面意思是可信执行环境,核心概念为以第三方硬件为载体,数据在由硬件创建的可信执行环境中进行共享。这方面以Intel的SGX技术,AMD的SEV技术,ARM的Trust Zone技术等为代表。TEE方案的大致原理如下图所示:
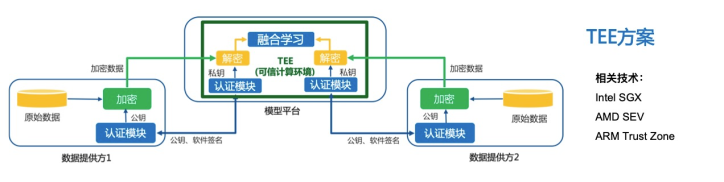
目前在生产环境可用的TEE技术,比较成熟的基本只有Intel的SGX技术,基于SGX技术的各种应用也是目前业界的热门方向,微软、谷歌等公司在这个方向上都有所投入。
SGX(Software Guard Extensions )是Intel提供的一套软件保护方案。SGX通过提供一系列CPU指令码,允许用户代码创建具有高访问权限的私有内存区域(Enclave - 飞地),包括OS,VMM,BIOS,SMM均无法私自访问Enclave,Enclave中的数据只有在CPU计算时,通过CPU上的硬件进行解密。同时,Intel还提供了一套远程认证机制(Remote Attestation),通过这套机制,用户可以在远程确认跑在Enclave中的代码是否符合预期。
MPC(Multi-party Computation,多方安全计算)一直是学术界比较火的话题,但在工业界的存在感较弱,之前都是一些创业小公司在这个方向上有一些探索,例如Sharemind,Privitar,直到谷歌提出了基于MPC的在个人终端设备的“联邦学习” (Federated Learning)的概念,使得MPC技术一夜之间在工业界火了起来。MPC方案的大致原理如下图所示:
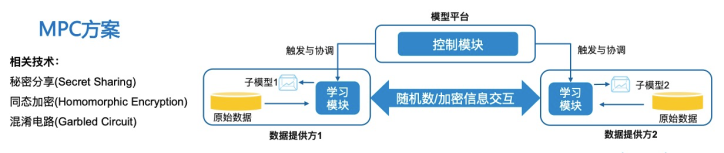
目前,在MPC领域,主要用到的是技术是混淆电路(Garbled Circuit)、秘密分享(Secret Sharing)和同态加密(Homomorphic Encryption)。
混淆电路是图灵奖得主姚期智教授在80年代提出的一个方法。其原理是,任意函数最后在计算机语言内部都是由加法器、乘法器、移位器、选择器等电路表示,而这些电路最后都可以仅由AND和XOR两种逻辑门组成。一个门电路其实就是一个真值表,假设我们把门电路的输入输出都使用不同的密钥加密,设计一个加密后的真值表,这个门从控制流的角度来看还是一样的,但是输入输出信息都获得了保护。
秘密分享的基本原理是将每个数字随机拆散成多个数并分发到多个参与方那里。然后每个参与方拿到的都是原始数据的一部分,一个或少数几个参与方无法还原出原始数据,只有大家把各自的数据凑在一起时才能还原真实数据。
同态加密是一种特殊的加密方法,允许对密文进行处理得到仍然是加密的结果,即对密文直接进行处理,跟对明文进行处理后再对处理结果加密,得到的结果相同。同态性来自抽象代数领域的概念,同态加密则是它的一个应用。
当前,业界针对数据共享场景,利用上面的技术路线推出了一些解决方案,包括隐私保护机器学习PPML、联邦学习、竞合学习、可信机器学习等,但这些方案只利用了其中的一部分技术,从而只适合部分场景,同时基本处于学术研究阶段,没有在生产环境落地。
为了更好的应对形势变化,解决数据共享需求与隐私泄露和数据滥用之间的矛盾,蚂蚁金服提出了希望通过技术手段,确保多方在使用数据共享学习的同时,能做到:用户隐私不会被泄露,数据使用行为可控,我们称之为共享机器学习(Shared Machine Learning)。
共享机器学习的定义:在多方参与且各数据提供方与平台方互不信任的场景下,能够聚合多方信息并保护参与方数据隐私的学习范式。
从17年开始,蚂蚁金服就一直在共享机器学习方向进行探索和研究,在结合了TEE与MPC两条路线的同时,结合蚂蚁的自身业务场景特性,聚焦于在金融行业的应用。
蚂蚁金服共享机器学习方案拥有如下特性:
基于数年沉淀与积累,目前共享机器学习技术已在银行、保险、商户等行业成功落地诸多场景业务。通过在业务中打磨出的金融级共享机器学习能力,沉淀下来一套数据共享场景的通用解决方案,未来会逐步对外开放。
在几年的艰苦研发中,共享学习累积专利50余项。在2019中国人工智能峰会上,共享机器学习获得“紫金产品创新奖”,在8月16日的全球人工智能创业者大会上,获得“应用案例示范奖”。
下面,我们将分享基于上面两种路线的共享机器学习实践细节。
基于TEE的共享学习
蚂蚁共享学习底层使用Intel的SGX技术,并可兼容其它TEE实现。目前,基于SGX的共享学习已支持集群化的模型在线预测和离线训练。
1.模型在线预测
预测通常是在线服务。相对于离线训练,在线预测在算法复杂度上面会相对简单,但是对稳定性的要求会更高。
提升在线服务稳定性的关健技术之一就是集群化的实现——通过集群化解决负载均衡,故障转移,动态扩容等稳定性问题。
但由于SGX技术本身的特殊性,传统的集群化方案在SGX上无法工作。
为此,我们设计了如下分布式在线服务基本框架:
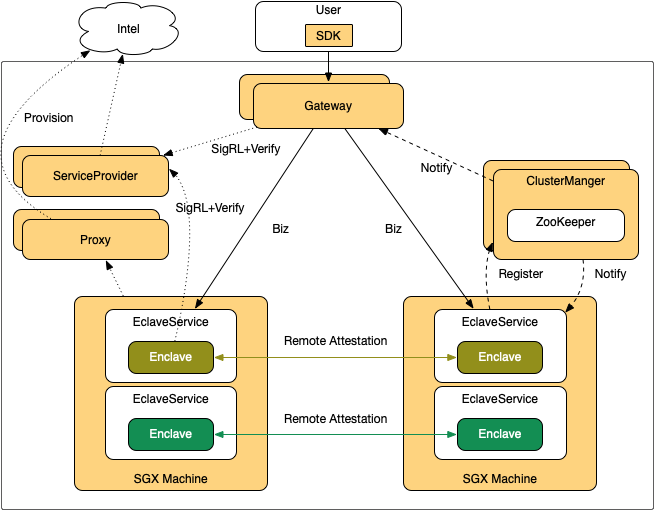
该框架与传统分布式框架不同的地方在于,每个服务启动时会到集群管理中心(ClusterManager,简称CM)进行注册,并维持心跳,CM发现有多个代码相同的Enclave进行了注册后,会通知这些Enclave进行密钥同步,Enclave收到通知后,会通过远程认证相互确认身份。当确认彼此的Enclave签名完全相同时,会通过安全通道协商并同步密钥。
该框架具备如下特性:
目前在这套框架之上已经支持包括LR、GBDT、Xgboost等多种常用的预测算法,支持单方或多方数据加密融合后的预测。基于已有框架,也可以很容易的扩展到其它算法。
2.模型离线训练
模型训练阶段,除了基于自研的训练框架支持了LR和GBDT的训练外,我们还借助于LibOs Occlum和自研的分布式组网系统,成功将原生Xgboost移植到SGX内,并支持多方数据融合和分布式训练。通过上述方案,不仅可以减少大量的重复性开发工作,并且在Xgboost社区有了新的功能更新后,可以在SGX内直接复用新功能,无需额外开发。目前我们正在利用这套方案进行TensorFlow框架的迁移。
此外,针对SGX当下诟病的128M内存限制问题(超过128M会触发换页操作,导致性能大幅下降),我们通过算法优化和分布式化等技术,大大降低内存限制对性能的影响。
基于TEE的多方数据共享学习训练流程如下:
1. 机构用户从Data Lab下载加密工具
2. 使用加密工具对数据进行加密,加密工具内嵌了RA流程,确保加密信息只会在指定的Enclave中被解密
3. 用户把加密数据上传到云端存储
4. 用户在Data Lab的训练平台进行训练任务的构建
5. 训练平台将训练任务下发到训练引擎
6. 训练引擎启动训练相关的Enclave,并从云端存储读取加密数据完成指定的训练任务。
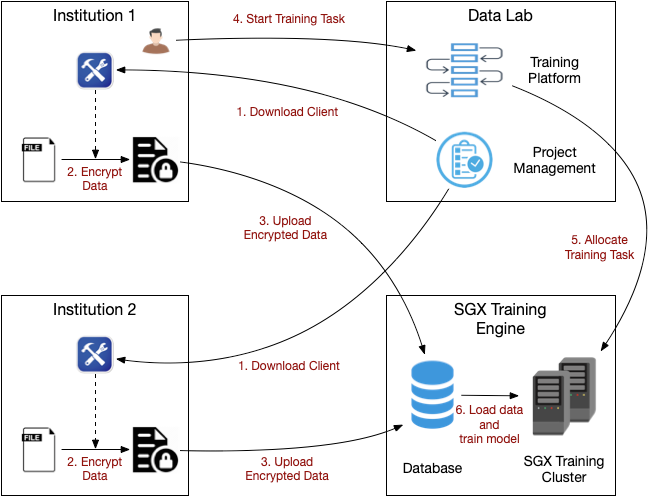
采用该方式进行数据共享和机器学习,参与方可以保证上传的数据都经过加密,并通过形式化验证保证加密的安全性。
基于MPC的共享学习
蚂蚁基于MPC的共享学习框架分为三层:

目前我们这套基于MPC的共享学习框架已支持了包括LR、GBDT、GNN等头部算法,后续一方面会继续根据业务需求补充更多的算法,同时也会为各种算子提供更多的技术实现方案,以应对不同的业务场景。
基于MPC的多方数据共享学习训练流程如下:
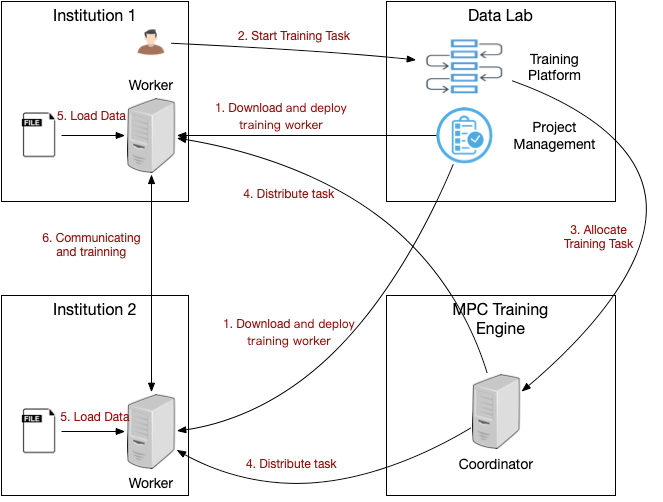
如图所示,训练步骤为:
1. 机构用户从Data Lab下载训练服务并本地部署
2. 用户在Data Lab的训练平台上进行训练任务的构建
3. 训练平台将训练任务下发给训练引擎
4. 训练引擎将任务下发给机构端的训练服务器Worker
5. Worker加载本地数据
6. Worker之间根据下发的训练任务,通过多方安全协议交互完成训练任务
训练引擎的具体架构如下:
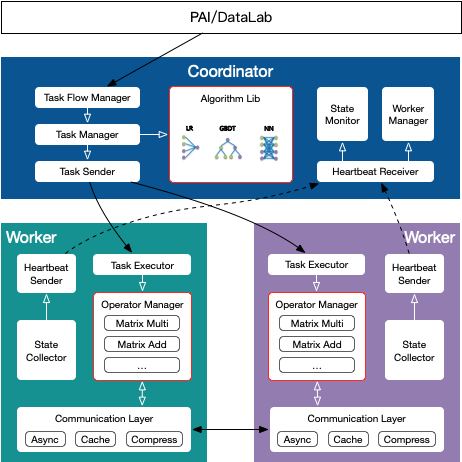
其中Coordinator部署于蚂蚁平台,用于任务的控制和协调,本身并不参与实际运算。Worker部署在参与多方安全计算的机构,基于安全多方协议进行实际的交互计算。
用户在建模平台构建好的训练任务流会下发给Coordinator的Task Flow Manager,Task Flow Manager会把任务进行拆解,通过Task Manager把具体算法下发给Worker端的Task Executor,Task Executor根据算法图调用Worker上的安全算子完成实际的运算。
利用这套方法,可以做到数据不出域就可以完成数据共享,训练工具可以部署在本地的服务器。
目前,国内对于数据共享场景的机器学习解决方案,比较熟悉的可能是由谷歌提出的联邦学习概念。
经过我们的了解,其实联邦学习目前涉及两个不同的概念:
它们侧重于不同的数据共享场景,采用不同的技术,相比之下,蚂蚁金服的共享学习兼容多种安全计算技术,并且支持多种机器学习算法和使用场景。
除此之外,共享学习和联邦学习的差异在于:
1. 联邦学习只解决数据不出域的情况,这就限制了其可以使用的技术(只有严格的MPC算法才符合这个要求),而共享学习目前基于TEE的集中式共享学习技术,是联邦学习没有涉及的;
2. 联邦学习讲究的是参与各方的“身份和地位”的相同,所以叫联邦;而共享学习则不强调各共享方的地位对等,在很多场景下,不同的参与方是拥有不同的角色的。
目前,数据共享下的机器学习仍然还有很多可突破的地方,这些不同只是对当前状态的一个比较,希望大家能对共享学习有更好的理解。
让数据孤岛在安全环境下进行连接、合作、共创、赋能,是蚂蚁金服共享机器学习的核心使命。
共享机器学习作为一个安全与AI的交叉学科,正在越来越受到关注,尤其是在金融行业,有着广阔的应用空间。但是,这个领域的各项技术,也远未到成熟的阶段。我们团队经过两年的摸索,也只是取得了阶段性的一些成果,在算法的计算性能以及支持算法的多样性等各个方面,还有一段路要走。
9月27日杭州云栖大会,蚂蚁金服将向外界首次分享共享学习的理念和实践,欢迎届时关注。后续我们也会分享更多共享学习方面的研究进展及实践经验, 欢迎业界同仁交流探讨,共同探索更多更强的数据孤岛解决方案,推进数据共享下的机器学习在更多场景下落地。

