蚂蚁金服技术团队
分类: 数据库开发技术
2019-05-31 14:19:29
查询优化理论诞生距今已有四十来年,学术界和工业界其实已经形成了一套比较完善的查询优化框架(System-R 的 Bottom-up 优化框架和 Volcano/Cascade 的 Top-down 优化框架),但围绕查询优化的核心难题始终没变——如何利用有限的系统资源尽可能为查询选择一个“好”的执行计划。
近年来,新的存储结构(如 LSM 存储结构)的出现和分布式数据库的流行进一步加大了查询优化的复杂性,本文章结合 OceanBase 数据库过去近十年时间的实践经验,与大家一起探讨查询优化在实际应用场景中的挑战和解决方案。
SQL 是一种结构化查询语言,它只告诉数据库”想要什么”,但是它不会告诉数据库”如何获取”这个结果,这个"如何获取"的过程是由数据库的“大脑”查询优化器来决定的。在数据库系统中,一个查询通常会有很多种获取结果的方法,每一种获取的方法被称为一个"执行计划"。给定一个 SQL,查询优化器首先会枚举出等价的执行计划。
其次,查询优化器会根据统计信息和代价模型为每个执行计划计算一个“代价”,这里的代价通常是指执行计划的执行时间或者执行计划在执行时对系统资源(CPU + IO + NETWORK)的占用量。最后,查询优化器会在众多等价计划中选择一个"代价最小"的执行计划。下图展示了查询优化器的基本组件和执行流程。
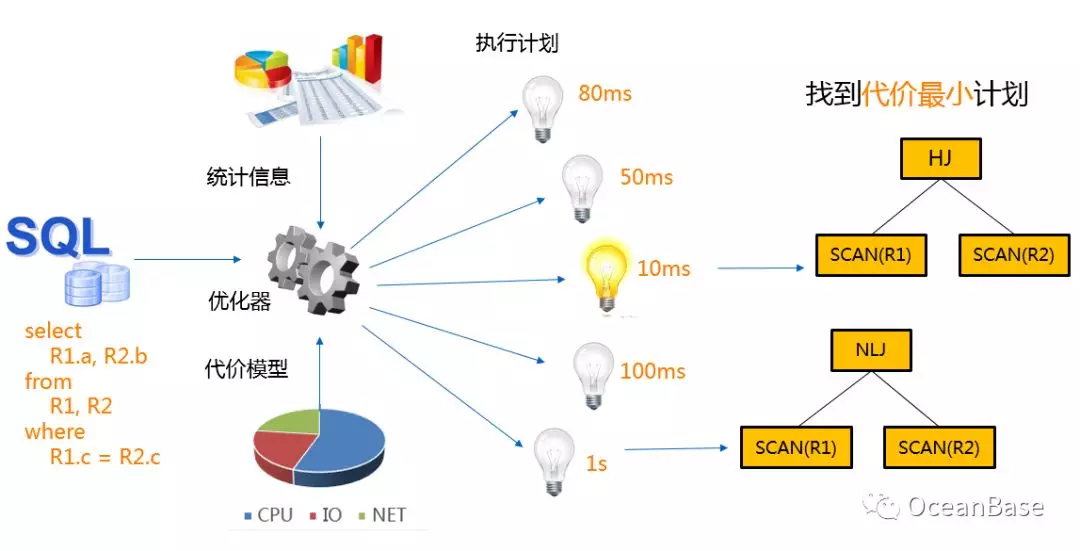
查询优化自从诞生以来一直是数据库的难点,它面临的挑战主要体现在以下三个方面:
挑战一:精准的统计信息和代价模型
统计信息和代价模型是查询优化器基础模块,它主要负责给执行计划计算代价。精准的统计信息和代价模型一直是数据库系统想要解决的难题,主要原因如下:
1、统计信息:在数据库系统中,统计信息搜集主要存在两个问题。首先,统计信息是通过采样搜集,所以必然存在采样误差。其次,统计信息搜集是有一定滞后性的,也就是说在优化一个 SQL 查询的时候,它使用的统计信息是系统前一个时刻的统计信息。
2、选择率计算和中间结果估计:选择率计算一直以来都是数据库系统的难点,学术界和工业界一直在研究能使选择率计算变得更加准确的方法,比如动态采样,多列直方图等计划,但是始终没有解决这个难题,比如连接谓词选择率的计算目前就没有很好的解决方法。
3、代价模型:目前主流的数据库系统基本都是使用静态的代价模型,比如静态的 buffer 命中率,静态的 IO RT,但是这些值都是随着系统的负载变化而变化的。如果想要一个非常精准的代价模型,就必须要使用动态的代价模型。
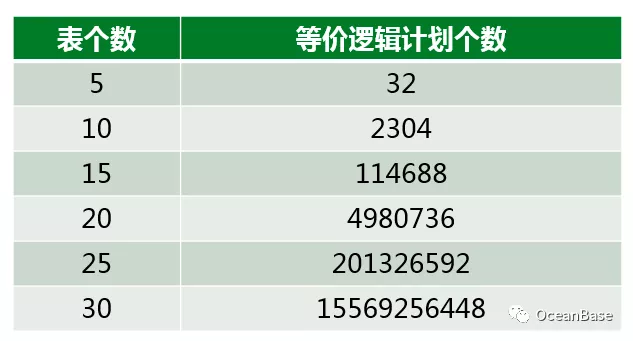
挑战二:海量的计划空间
复杂查询的计划空间是非常大的,在很多场景下,优化器甚至没办法枚举出所有等价的执行计划。下图展示了星型查询等价逻辑计划个数(不包含笛卡尔乘积的逻辑计划),而优化器真正的计划空间还得正交上算子物理实现,基于代价的改写和分布式计划优化。在如此海量的计划空间中,如何高效的枚举执行计划一直是查询优化器的难点。
挑战三:高效的计划管理机制
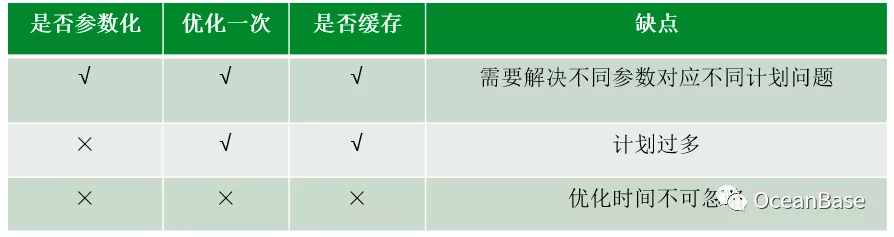
计划管理机制分成计划缓存机制和计划演进机制。
1、计划缓存机制:计划缓存根据是否参数化,优化一次/总是优化以及是否缓存可以划分成如下图所示的三种计划缓存方法。每个计划缓存方法都有各自的优缺点,不同的业务需求会选择不同的计划缓存方法。在蚂蚁/阿里很多高并发,低时延的业务场景下,就会选择参数化+优化一次+缓存的策略,那么就需要解决不同参数对应不同计划的问题(parametric query optimization),后面我们会详细讨论。
2、计划演进机制:计划演进是指对新生成计划进行验证,保证新计划不会造成性能回退。在数据库系统中, 新计划因为一些原因(比如统计信息刷新,schema版本升级)无时无刻都在才生,而优化器因为各种不精确的统计信息和代价模型始终是没办法百分百的保证新生成的计划永远都是最优的,所以就需要一个演进机制来保证新生成的计划不会造成性能回退。
下面我们来看一下 OceanBase 根据自身的框架特点和业务模型如何解决查询优化器所面临的挑战。
从统计信息和代价模型的维度看,OceanBase 发明了基于 LSM-TREE 存储结构的基表访问路径选择。从计划空间的角度看,因为 OceanBase 原生就是一个分布式关系数据库系统,它必然要面临的一个问题就是分布式计划优化。从计划管理的角度看,OceanBase 有一整套完善的计划管理机制。
基表访问路径选择方法是指优化器选择索引的方法,其本质是要评估每一个索引的代价并选择代价最小的索引来访问数据库中的表。对于一个索引路径,它的代价主要由两部分组成,扫描索引的代价和回表的代价(如果一个索引对于一个查询来说不需要回表,那么就没有回表的代价)。
通常来说,索引路径的代价取决于很多因素,比如扫描/回表的行数,投影的列数,谓词的个数等。为了简化我们的讨论,在下面的分析中,我们从行数这个维度来介绍这两部分的代价。
扫描索引的代价跟扫描的行数成正比,而扫描的行数则是由一部分查询的谓词来决定,这些谓词定义了索引扫描开始和结束位置。理论上来说扫描的行数越多,执行时间就会越久。扫描索引的代价是顺序 IO。
回表的代价跟回表的行数也是正相关的,而回表的行数也是由查询的谓词来决定,理论上来说回表的行数越多,执行时间就会越久。回表的扫描是随机 IO,所以回表一行的代价通常会比顺序扫描索引一行的代价要高。
在传统关系数据库中,扫描索引的行数和回表的行数都是通过优化器中维护的统计信息来计算谓词选择率得到(或者通过一些更加高级的方法比如动态采样)。
举个简单的例子,给定联合索引(a,b)和查询谓词 a > 1 and a < 5 and b < 5, 那么谓词 a > 1 and a < 5 定义了索引扫描开始和结束的位置,如果满足这两个条件的行数有 1w 行,那么扫描索引的代价就是 1w 行顺序扫描,如果谓词 b < 5 的选择率是 0.5,那么回表的代价就是 5k 行的随机扫描。
那么问题来了:传统的计算行数和代价的方法是否适合基于 LSM-TREE 的存储引擎?
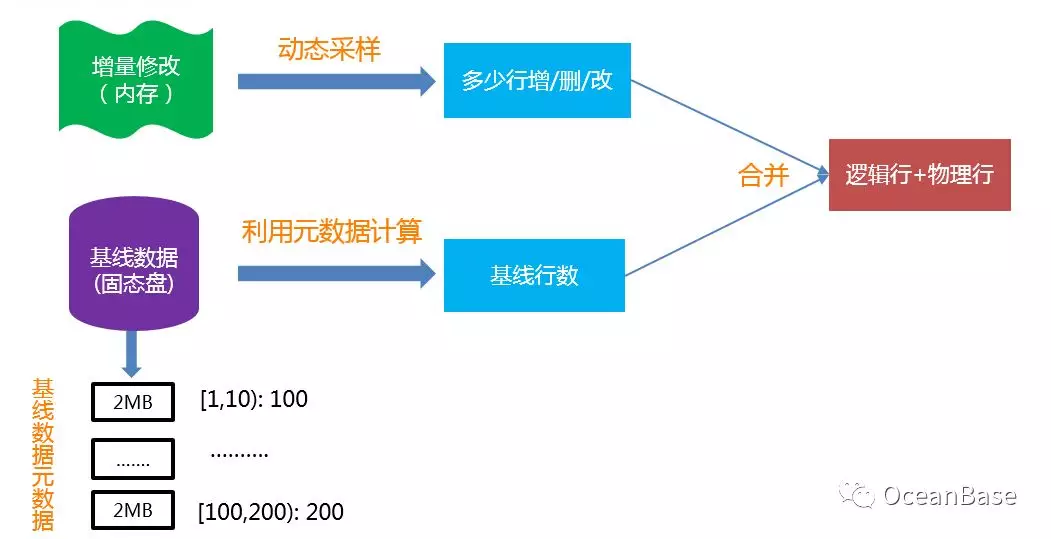
LSM-TREE 存储引擎把数据分为了两部分(如下图所示),静态数据(基线数据)和动态数据(增量数据)。其中静态数据不会被修改,是只读的,存储于磁盘;所有的增量修改操作(增、删、改)被记录在动态数据中,存储于内存。静态数据和增量数据会定期的合并形成新的基线数据。在 LSM-TREE 存储引擎中,对于一个查询操作,它需要合并静态数据和动态数据来形成最终的查询结果。

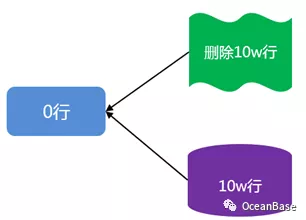
考虑下图中 LSM-TREE 存储引擎基线数据被删除的一个例子。在该图中,基线中有 10w 行数据,增量数据中维护了对这 10w 行数据的删除操作。在这种场景下,这张表的总行数是 0 行,在传统的基于 Buffer-Pool 的存储引擎上,扫描会很快,也就是说行数和代价是匹配的。但是在 LSM-TREE 存储引擎中,扫描会很慢(10w 基线数据 + 10w 增加数据的合并),也就是行数和代价是不匹配的。
这个问题的本质原因是在基于 LSM-TREE 的存储引擎上,传统的基于动态采样和选择率信息计算出来的行数不足以反应实际计算代价过程中需要的行数。
举个简单的例子,在传统的关系数据库中,我们插入 1w 行,然后删除其中 1k 行,那么计算代价的时候会用 9k 行去计算,在 LSM-TREE 的场景下,如果前面 1w 行是在基线数据里面,那么内存中会有额外的 1k 行,在计算代价的时候我们是需要用 11k 行去计算。
为了解决 LSM-TREE 存储引擎的计算代价行数和表中真实行数不一致的行为,OceanBase 提出了“逻辑行”和“物理行”的概念以及计算它们的方法。其中逻辑行可以理解为传统意义上的行数,物理行主要用于刻画 LSM-TREE 这种存储引擎在计算代价时需要真正访问的行数。
再考虑上图中的例子,在该图中,逻辑行是 0 行,而物理行是 20w 行。给定索引扫描的开始/结束位置,对于基线数据,因为 OceanBase 为基线数据维护了块级别的统计信息,所以能很快的计算出来基线行数。对于增量数据,则通过动态采样方法获取增/删/改行数,最终两者合并就可以得到逻辑行和物理行。下图展示了 OceanBase 计算逻辑行和物理行的方法。
相比于传统的基表访问路径方法,OceanBase 的基于逻辑行和物理行的方法有如下两个优势:
优势一:实时统计信息
因为同时考虑了增量数据和基线数据,相当于统计信息是实时的,而传统方法的统计信息搜集是有一定的滞后性的(通常是一张表的增/删/修改操作到了一定程度,才会触发统计信息的重新搜集)。
优势二:解决了索引列上的谓词依赖关系
考虑索引(a,b)以及查询条件 a = 1 and b = 1 , 传统的方法在计算这个查询条件的选择率的时候必然要考虑的一个问题是 a 和 b 是否存在依赖关系,然后再使用对应的方法(多列直方图或者动态采样)来提高选择率计算的正确率。OceanBase 目前的估行方法默认能够解决 a 和 b 的依赖关系的场景。
OceanBase 原生就有分布式的属性,那么它必然要解决的一个问题就是分布式计划优化。很多人认为分布式计划优化很难,无从下手,那么分布式计划优化跟本地优化到底有什么区别?分布式计划优化是否需要修改现有的查询优化框架来做优化?
在笔者看来,现有的查询优化框架完全有能力处理分布式计划优化,但是分布式计划优化会大大增加计划的搜索空间,主要原因如下:
1、在分布式场景下,选择的是算子的分布式算法,而算子的分布式算法空间比算子本地算法的空间要大很多。下图展示了一个 Hash Join 在分布式场景下可以选择的分布式算法。
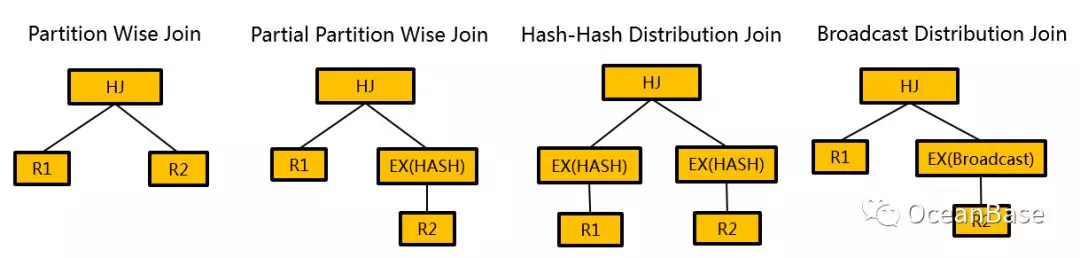
2、在分布式场景下,除了序这个物理属性之外,还增加了分区信息这个物理属性。分区信息主要包括如何分区以及分区的物理信息。分区信息决定了算子可以采用何种分布式算法。
3、在分布式场景下,分区裁剪/并行度优化/分区内(间)并行等因素也会增大分布式计划的优化复杂度。
OceanBase 目前采用两阶段的方式来做分布式优化。在第一阶段,OceanBase 基于所有表都是本地的假设生成一个最优本地计划。在第二阶段,OceanBase 开始做并行优化, 用启发式规则来选择本地最优计划中算子的分布式算法。下图展示了 OceanBase 二阶段分布式计划的一个例子。

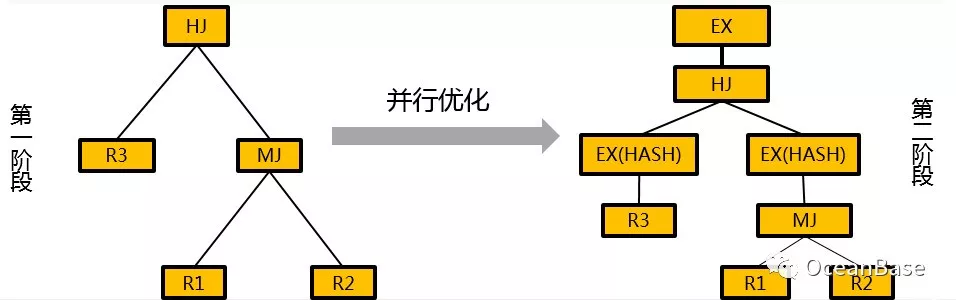
OceanBase 二阶段的分布式计划优化方法能减少优化空间,降低优化复杂度,但是因为在第一阶段优化的时候没有考虑算子的分布式信息,所以可能导致生成的计划次优。目前 OceanBase 正在实现一阶段的分布式计划优化:
1、在 System-R 的 Bottom-up 的动态规划算法中,枚举所有算子的所有分布式实现并且维护算子的物理属性。
2、在 System-R 的 Bottom-up 的动态规划算法中,对于每一个枚举的子集, 保留代价最小/有 Interesting order/有 Interesting 分区的计划。
一阶段的分布式计划优化可能会导致计划空间增长很快,所以必须要有一些 Pruning 规则来减少计划空间或者跟本地优化一样在计划空间比较大的时候,使用遗传算法或者启发式规则来解决这个问题。
OceanBase 基于蚂蚁/阿里真实的业务场景,构建了一套完善的计划缓存机制和计划演进机制。
OceanBase 计划缓存机制
如下图所示,OceanBase 目前使用参数化计划缓存的方式。这里涉及到两个问题:为什么选择参数化以及为什么选择缓存?
1、参数化:在蚂蚁/阿里很多真实业务场景下,为每一个参数缓存一个计划是不切实际的。考虑一个根据订单号来查询订单信息的场景,在蚂蚁/阿里高并发的场景下,为每一个订单号换成一个计划是不切实际的,而且也不需要,因为一个带订单号的索引能解决所有参数的场景。
2、计划缓存:计划缓存是因为性能的原因,对于蚂蚁/阿里很多真实业务场景来说,如果命中计划,那么一个查询的性能会在几百 us,但是如果没有命中计划,那么性能大概会在几个 ms。对于高并发,低时延的场景,这种性能优势是很重要的。

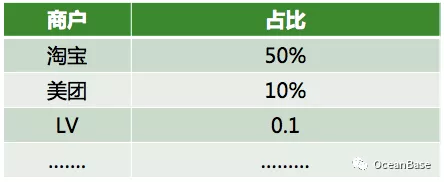
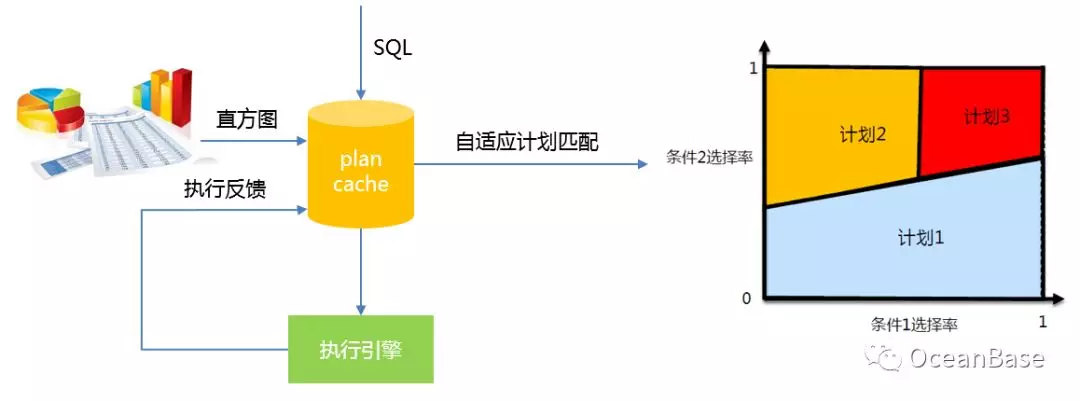
OceanBase 使用参数化计划缓存的方式,但是在很多蚂蚁真实的业务场景下,对所有的参数使用同一个计划并不是最优的选择。考虑一个蚂蚁商户域的业务场景,这个场景以商户的维度去记录每一笔账单信息,商户可以根据这些信息做一些分析和查询。这种场景肯定会存在大小账号问题,如下图所示,淘宝可能贡献了 50% 的订单,LV 可能只贡献了 0.1% 的订单。考虑查询“统计一个商户过去一年的销售额”,如果是淘宝和美团这种大商户,那么直接主表扫描会是一个合理的计划,对于 LV 这种小商户,那么走索引会是一个合理的计划。
为了解决不同参数对应不同计划的问题,OceanBase 实现了如下图所示的自适应计划匹配。该方法会通过直方图和执行反馈来监控每一个缓存的计划是否存在不同参数需要对应不同计划的问题。一旦存在,自适应计划匹配会通过渐进式的合并选择率空间来达到把整个选择率空间划分成若干个计划空间(每个空间对应一个计划)的目的。
OceanBase 计划演进机制
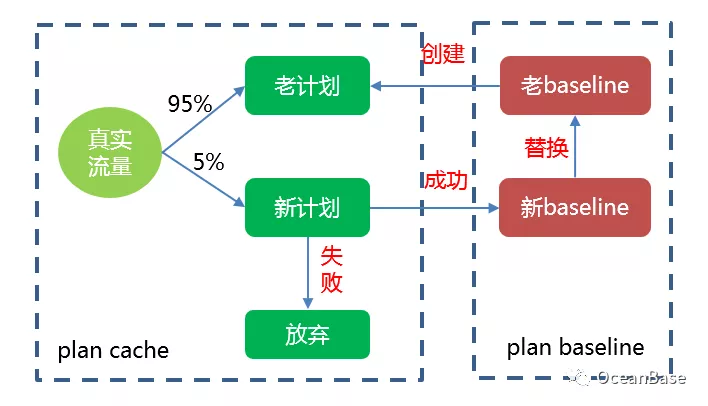
在蚂蚁/阿里很多高并发,低时延的业务场景下,OceanBase 必须要保证新生成的计划不会导致性能回退。下图展示了 OceanBase 对新计划的演进过程。不同于传统的数据库系统采用定时任务和后台进程演进的方式,OceanBase 会使用真实的流量来进行演进,这样的一个好处是可以及时的更新比较优的计划。比如当业务新建了一个更优的索引时,传统数据库系统并不能立刻使用该索引,需要在演进定时任务启动后才能演进验证使用,而 OceanBase 可以及时的使用该计划。
OceanBase 查询优化器的实现立足于自身架构和业务场景特点,比如 LSM-TREE 存储结构、Share-Nothing 的分布式架构和大规模的运维稳定性。OceanBase 致力于打造基于 OLTP 和 OLAP 融合的查询优化器。从 OLTP 的角度看,我们立足于蚂蚁/阿里真实业务场景,完美承载了业务需求。从 OLAP 的角度看,我们对标商业数据库,进一步打磨我们 HTAP 的优化器能力。
