蚂蚁金服技术团队
分类: 高性能计算
2019-05-14 16:07:00

SQLFlow 的目标是将 SQL 引擎和 AI 引擎连接起来,让用户仅需几行 SQL 代码就能描述整个应用或者产品背后的数据流和 AI 构造。其中所涉及的 SQL 引擎包括 MySQL、Oracle、Hive、SparkSQL、Flink 等支持用 SQL 或其某个变种语言描述数据,以及描述对数据的操作的系统。而这里所指的 AI 引擎包括 TensorFlow、PyTorch 等深度学习系统,也包括 XGBoost、LibLinear、LibSVM 等传统机器学习系统。
SQLFlow 开源项目链接:
SQLFlow 的研发团队认为,在 SQLFlow 和 AI 引擎之间存在一个很大的空隙——如何把数据变成 AI 模型需要的输入。谷歌开源的 TensorFlow 项目开了一个好头,TFX Data Transform 和 feature column API 都是意图填补这个空缺的项目。但是这个空缺很大,是各种 SQL 引擎和各种 AI 引擎的笛卡尔积,远不是 TensorFlow 的这两个子项目就足以填补的,需要一个开源社区才行。要填补好这个空缺,需要先让用户意识到其重要性,这也是蚂蚁金服开源 SQLFlow 的意图之一。
SQLFlow 位于 AI 软件系统生态的最顶端,最接近用户,它也位于数据和数据流软件生态之上。
其实,将 SQL 和 AI 连接起来这个想法并非 SQLFlow 原创。谷歌于 2018 年年中发布的 BigQueryML 同样旨在“让数据科学家和分析师只用 SQL 语言就可以实现流行的机器学习功能并执行预测分析”。除了 Google 的 BigQueryML,微软基于 SQL Server 的 AI 扩展,以及 Teradata 的 SQL for DL 同样旨在连接 SQL 和 AI,让人工智能的应用变得像 SQL 一样简单。而 SQLFlow 与上述各个系统最根本的差异在于:SQLFlow 是开源的,以上系统都不是。
蚂蚁金服和很多互联网公司一样,不同产品背后有很多功能都依赖于 AI,比如用户信用的评估就是一套预测模型。到目前为止,每一个这样的功能的实现,都依赖一个工程师团队开发多个子系统——读取数据库或者在线日志流、这两类数据的 join、各种数据筛选、数据到模型输入(常说的 features)的映射、训练模型、用训练好的模型来做预测。整个过程下来耗时往往以月计,如果加班加点放弃写 unit test 代码,可能缩短到以周记。
以上问题正是 SQLFlow 系统希望替工程师们解决的问题。蚂蚁金服拥有数千数据分析师,他们日常工作用的就是 SQL 语言。虽然数据分析师在互联网行业往往不像用 Python、Java、C++ 的工程师那样醒目,但是在很多有面向商业伙伴的业务的公司里,比如 LinkedIn,他们的贡献和人数都能与工程师相匹敌。SQLFlow 最早的初衷,就是希望解决分析师既要操作数据又要使用 AI、往往需要在两个甚至更多的系统之间切换、工作效率低的窘境。
SQLFlow 旨在大幅提升效率,让上述功能实现所花费的时间进一步缩短到能以日计,甚至以小时计的程度。
要达到这样的效率,必须有一种效率极高的描述工作意图的方式。SQL 是一种典型的描述意图,而不描述过程的编程语言。用户可以说我要 join 两个表,但是不需要写循环和构造 hash map 来描述如何 join 两个表。这个特性使得 SQL 能极大地提升开发效率,这正是 SQLFlow 选择扩展 SQL 语法支持 AI 这条思路的原因。
不过,高效率的背后是更大的工程技术挑战。SQLFlow 需要做到能根据用户的意图,自动生成达到意图的 Python、C++、Go 语言的程序。

设计目标
在连接 SQL 和 AI 应用这一方向上,业内已有相关工作。开发者可以使用像 DOT_PRODUCT 这样的运算符在 SQL 中编写简单的机器学习预测(或评分)算法。但是,从训练程序到 SQL 语句需要进行大量的模型参数复制粘贴的工作。目前在一些商业软件中,已经有部分专有 SQL 引擎提供了支持机器学习功能的扩展。
但上述已有的解决方案都无法解决蚂蚁金服团队的痛点,他们的目标是打造一个完全可扩展的解决方案。
应对上述挑战的关键在于打造一套 SQL 扩展语法。研发团队首先从仅支持 MySQL 和 TensorFlow 的原型开发开始,后续计划支持更多 SQL 引擎和机器学习工具包。
从 SQL 到机器学习
SQLFlow 可以看作一个翻译器,它把扩展语法的 SQL 程序翻译成一个被称为 submitter 的程序,然后执行。 SQLFlow 提供一个抽象层,把各种 SQL 引擎抽象成一样的。SQLFlow 还提供一个可扩展的机制,使得大家可以插入各种翻译机制,得到基于不同 AI 引擎的 submitter 程序。
SQLFlow 对 SQL 语法的扩展意图很简单:在 SELECT 语句后面,加上一个扩展语法的 TRAIN 从句,即可实现 AI 模型的训练。或者加上一个 PREDICT 从句即可实现用现有模型做预测。这样的设计大大简化了数据分析师的学习路径。
此外,SQLFlow 也提供一些基本功能,可以供各种 submitter 翻译插件使用,用来根据数据的特点,推导如何自动地把数据转换成 features。这样用户就不需要在 TRAIN 从句里描述这个转换。
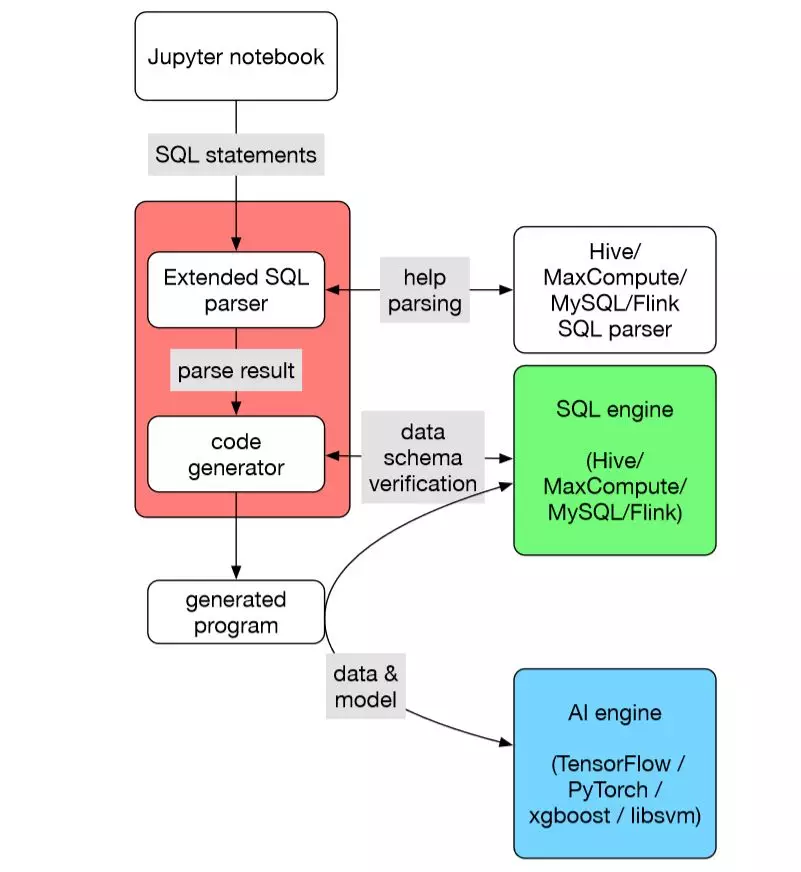
以上这些设计意图在 SQLFlow 的开源代码中都有体现。当然,SQLFlow 开发时间还比较短,仍然存在很多做的不够细致的地方。蚂蚁金服将其开源的另一个目的,就是希望能够和各个 SQL 引擎团队和各个 AI 团队一起打造这座横跨数据和 AI 的桥梁。
基于 Go 语言开发
据介绍,SQLFlow 基于 Go 语言开发,Go 语言的众多优点使其成为了 SQLFlow 研发团队的首选。除了 Go 社区讨论较多的优势以外,以下两点被重点提及:
首先 Go 容易学习却拥有极高的开发效率。它的 keyword 数量比 C 语言还要少,但是描述能力(平均每一行代码能表示的意图)接近 Python。
另一个原因是 Go 的代码库易于长期维护。一项工作用 Python 或者 C++ 来写,会有很多种写法,都能跑。用 Go 来写,往往只有一种写法。这就使得 Go 程序员社区里不会有很多风格共存,也就不需要 Google C++ style 这样的代码规范来限制不许用 C++ 的哪些特性,也不会像 Python 代码开发时那样,各种代码风格之间形成鄙视链,在 code review 过程里带来不必要的争执。
与阿里 PAI 的关系
SQLFlow 研发团队认为,AI 和机器学习的生态可以分为很多层。其中 TensorFlow、PyTorch、XGBoost、LibLinear 这些系统位于最底层,距离终端用户最远,只有很硬核的用户才能熟练掌握和使用,而这部分用户在互联网从业者里占的比例较小。
SQLFlow 和阿里推出的机器学习平台 PAI 均位于生态的最顶层,需要调用下层的技术栈,二者均直接面对最终用户,而这些用户中可能有大量并不具备 AI 背景知识。
PAI 系统通过先进的图形用户界面来解决 AI 难理解、难应用的挑战——比如托拽基础 AI 组件来构造复杂的模型和数据流。
SQLFlow 则通过写 SQL 程序的方式来实现这一目标。有能写下来的程序,就容易存档,容易 Code Review,容易分享知识,容易集思广益,容易高效率迭代。此外,敲键盘写程序比动鼠标拖拽快。
SQLFlow 项目负责人表示,SQLFlow 和 PAI 都是有意思且有意义的尝试,二者的发展都值得持续观察。
SQLFlow 目前依赖 TensorFlow 等底层引擎来实现训练和预测。为了提升 SQLFlow 在机器学习模型的训练和预测性能,蚂蚁金服有一个团队专门做硬件加速 AI 计算的工作,最近已经有了一些令人惊喜的成绩,希望在不久的将来可以和大家分享细节。另外还有一个兄弟项目专门维护蚂蚁金服对 TensorFlow 的功能扩展,也和性能相关。
SQLFlow 项目负责人表示,训练和预测只是整个 AI 产品功能长长的链条中的两个环节。SQLFlow 这个项目是为解决整个链条构建而打造的,其中有很多环节的耗时比 AI 的训练和预测多得多,因此还有极大的性能提升的空间。比如很多 SQL 引擎并不支持让一个分布式 AI 程序并发读取其中的数据,如果 SQLFlow 能够解决类似的吞吐量限制,AI 的总体效率能提高数倍甚至数十倍。
在对机器学习算法的支持方面,SQLFlow 设计的初衷就是要复用各个 AI 引擎各自的模型库。目前 SQLFlow 支持 TensorFlow Estimator 规范的模型。比如 SQLFlow 扩展语法中 SELECT ... TRAIN DNNClassifier ... 这个写法,DNNClassifier 就是一个 Python class 的名,在这个例子中是一个派生自 tf.Estimator 的 class。SQLFlow 研发团队也正在做支持 Keras 模型的相关工作,团队也在考虑规范 XGBoost 模型的程序写作,使其可以被 SQLFlow 用户方便地调用。
这些工作背后的思路是希望互联网行业常见的三类技术角色:分析师、研究员、工程师的分工更清晰,从而能更专注发挥各自特长:分析师因为了解数据所以写 SQL,调用 DNNClassifier 这样由研究员用 Python 写的模型;研究员不用操心分布式计算和模型到底是如何被分布式训练(或预测)的,这部分工作留给工程师。与此同时,SQLFlow 作为一种粘合剂,把这三类角色的产出有机结合,以便更加高效地构造产品。
SQLFlow 当前已经能够带来研发效率的提升,但尚不完美,目前 SQLFlow 还存在以下问题有待解决:
第一个问题是 parsing。SQLFlow 目前已经对接 MySQL,正在对接 Hive 和 阿里云上的 MaxCompute,将来还希望能对接更多公司正在使用的 SQL 引擎。这些引擎的 SQL 语法大都符合 SQL 标准,但是总有一些自己独特的扩展,而用户往往不知不觉地用到了这些特点。SQLFlow 希望用户能在已有的 SELECT 语句之后,通过简单地添加一个 TRAIN 或者 PREDICT 从句,即可实现数据和 AI 的互联,这就要求 SQLFlow 支持各个 SQL 引擎独到的语法特点。
第二个问题是数据到 feature 的映射的自动化。目前 SQLFlow 是根据 SQL 字段的类型(INT、FLOAT、TEXT、BLOB)来自动化映射到 feature column API,比如 numeric_column 或者 categorical_column_with_vocabulary 或者 bucketized_column。其实很多 TEXT 字段里存储的信息很复杂,可能是一个 yaml 或者 json,所以需要扫描(至少一部分)数据,才能精准地判断这个映射。类似的,一个 BLOB 字段里可能是 protobuf message 的 encoding,encode 的是一个 TensorFlow 的 tensor。
第三个问题是 AI 引擎。 TensorFlow、PyTorch、XGBoost、LibLinear 这些 AI 引擎的分布式计算能力都有一些问题。TensorFlow 原生支持分布式训练,但不支持容错,一个进程挂了,整个作业就挂了。虽然这还可以通过 checkpointing 解决,但是不容错就不能弹性调度,不能弹性调度就意味着集群利用率可能极差。比如一个有 N 个 GPU 的集群上在运行一个作业,使用了一个 GPU;此时一个新提交的作业要求使用 N 个 GPU,因为空闲 GPU 个数是 N-1,所以这个新的作业不能开始执行,而是得一直等数小时甚至数天,直到前一个作业结束、释放那个被占用的 GPU。这么长时间里,集群利用率< 1/N。关于这个问题的解决方案,百度 PaddleEDL(https://kubernetes.io/blog/2017/12/paddle-paddle-fluid-elastic-learning/)和阿里集团的 XDL()做了一些很有益的探索。希望业界把过分集中于 AI 运行时间优化的眼光,分一部分到减少等待时间上。
接下来蚂蚁金服将致力于推动 SQLFlow 在蚂蚁金服业务和蚂蚁金服以外的公司的使用,让 SQLFlow 项目成为整个社区的共同工作,从中收获更多的反馈,引导项目的发展方向,也帮助明确各项工作的优先级。
令 SQLFlow 团队感到欣喜的是,虽然 SQLFlow 刚开源,但目前已经有来自美国和中国几大互联网公司的贡献者参与到社区工作中来。由于每个公司使用的 SQL 引擎不同,如果 SQLFlow 核心团队能提供比较好的数据层抽象,那么来自不同公司的贡献者就能比较容易地把 SQLFlow 适配到自己公司的引擎上。类似的,支持多种 AI 引擎的方式也是如此。
此外,SQLFlow 团队希望各个公司的研究员们能够参与到开源项目中来,分享各自的模型,未来 SQLFlow 会支持各种形式的模型,以便分析师使用。
过去这几年,蚂蚁金服一直积极参与开源社区共建,自 2011 年宣布第一波开源项目以来,开源项目数量每年皆有增长。目前蚂蚁金服已有 30 多个开源项目,其中,Ant Design项目已获三万多 Star,有 600 多人参与项目建设,EggJS 和 SOFA 系列也成为了社区热门。
在 SQLFlow 的 GitHub 项目中,蚂蚁金服提供了 SQLFlow 的安装指引以及快速入门的示例,对此项目感兴趣的开发者不妨一试。也欢迎留言反馈你对 SQLFlow 项目的建议和使用感受。
再次附上 SQLFlow 开源项目链接:
