蚂蚁金服技术团队
分类: 大数据
2019-03-14 14:06:20
小蚂蚁导读:在刚过去不久的春节,你是否也参与了支付宝春节集五福的活动呢?不少小伙伴发现,今年的支付宝扫福更严格、更快也更准确了,这背后的技术是怎么做到的呢?
本期稿件小蚂蚁邀请到了支付宝多媒体技术部创新组的算法专家嘉睿与大家分享支付宝春节集五福背后的技术,如果你也对此感兴趣,欢迎投简历加入我们!该团队目前正在招聘目标检测识别、文字检测识别方向的专业人才,有兴趣可以发邮件至:qiang.heq@antfin.com

集五福这个新年俗在2018年又与大家见面了,还是那个熟悉的味道-扫福集福,背后却是全新的技术架构,技术变革的背后隐藏着哪些故事呢?心历路程请听我慢慢道来。

2017年扫福任务,由最初定位为获得福卡的一个小功能点,上升到主流玩法,技术上也是猝不及防。手写行不行?窗花福行不行?任意的福字包罗万象,初次应对这么大型且复杂的识别任务,做到什么程度心里也没底,期间和产品讨论了很久。这块简单描述一下我们采用的什么措施来识别的。
回顾2017年扫福,一个很重要的举措就是我们引入了客户端福字检测的兜底预案,当服务端扛不住了就全走客户端,识别效果差点也总比限流都出不来强吧。事实证明我们这个预案派上了大用场,原计划在大年30高峰期开启的降级预案,由于用户的热情,在活动第一天中午就被迫启动了。
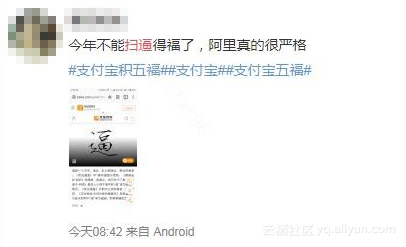
由于客户端识别的简单方案,扫福被小部分网民恶搞了:

2018年扫福除了要保证绝大部分用户能够快速顺畅的扫福字外,还面临着AR同一入口存在更多业务并发的压力,以及去年负面舆情问题。汇总下来新的一年要解决的问题主要如下:
(1)兼顾福字多样性的同时避免非福字尤其是相似字误识。
(2)高并发:去年虽然也考虑了有着亿级用户的支付宝扫一扫入口会有非常大的并发量,但是由于是第一年扫福还是低估了用户的参与热情,最终作出部分降级。依据去年的调用量看对于图像识别算法,如此高的并发是相当有挑战的,因此今年在整体方案设计中首要考虑的就是客户端与服务端如何联动,提供高并发识别服务,尽量在不降级的情况下保证用户顺畅的扫出福字抽福卡。
(3)AR入口承担更多识别任务:支撑扫福、扫人脸手势、AR平台运营活动;其中AR平台运营活动线上运营活动图片也有几百张,需要避免不同业务误识。
带着众多问题,2018年扫福,不能重走老路,我们给自己定了一个小目标:
基于上述分析,在方案设计时,从精度角度出发,有两种选择,一种是相对复杂的深度学习目标检测方法,另一种是轻量的检测方法+一个小型的校验网络,由于复杂一些的深度学习目标检测网络虽然误检低,但是不能覆盖低端机型(速度和内存等原因),因此最终选择传统的检测算法,这一步只需要保证快速的检测出福字候选区域,尽量不漏检,下一步则通过一个相对小的网络去校验。最终福字识别的客户端与服务端流程如下图:
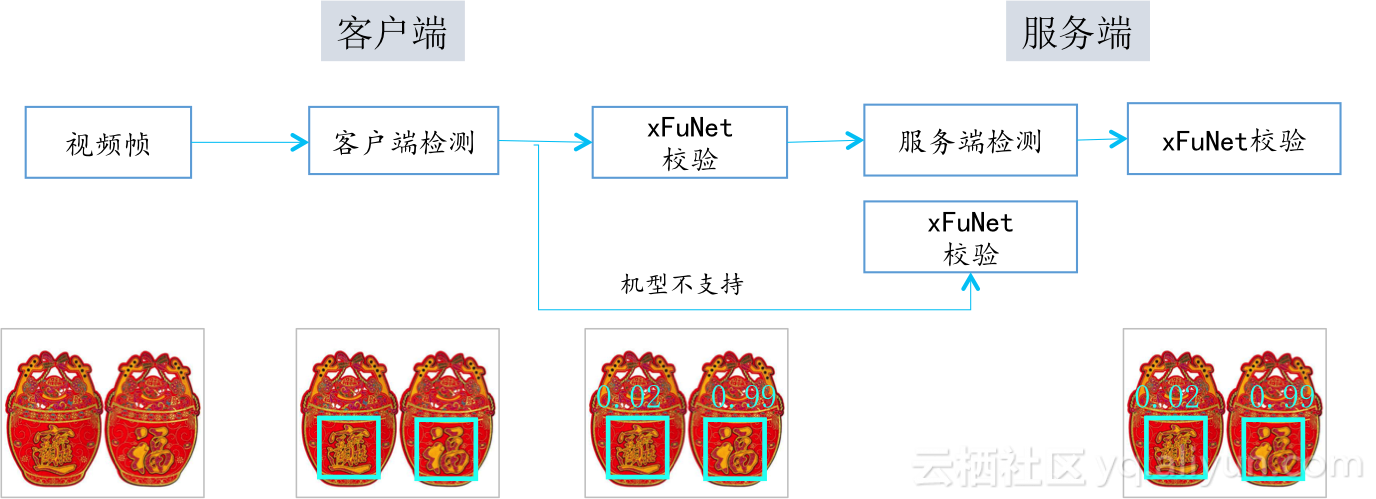
客户端:
a. 检测部分快速检出福字候选区域,全机型覆盖,侧重点在于尽量多的检出福字(90%以上)误检可以存在。
b. xFuNet校验,去掉上一步检测出来的误检,判断检测结果是否为福字,少量不确定部分先流转到其他业务,超过一定时间没有命中任何业务,则上传到服务端进行服务端检测校验。
服务端:
a. 检测部分主要是与客户端的检测算法互补,侧重点在客户端无法检测的少量福字的检测上,这部分使用基于小网络的深度学习目标检测算法,同样会有部分误检存在,因此也需要进行二次校验。
b. 服务端校验负责:对于少量客户端不支持xFuNet校验的机型,将客户端检测结果送至服务端进行xFuNet校验。服务端检测结果的二次校验。
如上文所述我们目前需要一个轻量级的校验网络,为了确保客户端快速高精度的分类效果,我们对业界主流的深度学习网络进行了评估,最符合项目需求的要算是MobileNet0.25了。但是其训练速度较慢,同时由于多个业务轮询,我们希望速度能低于10ms。基于这些现状,我们自研了一套轻量级的深度学习网络xFuNet,它是基于resnet18改造而来。
xFuNet的主要设计思路是:
a. 尽早缩小feature map大小
b. 控制参数数量(kernel size 和num output)
c. 控制卷积层数目
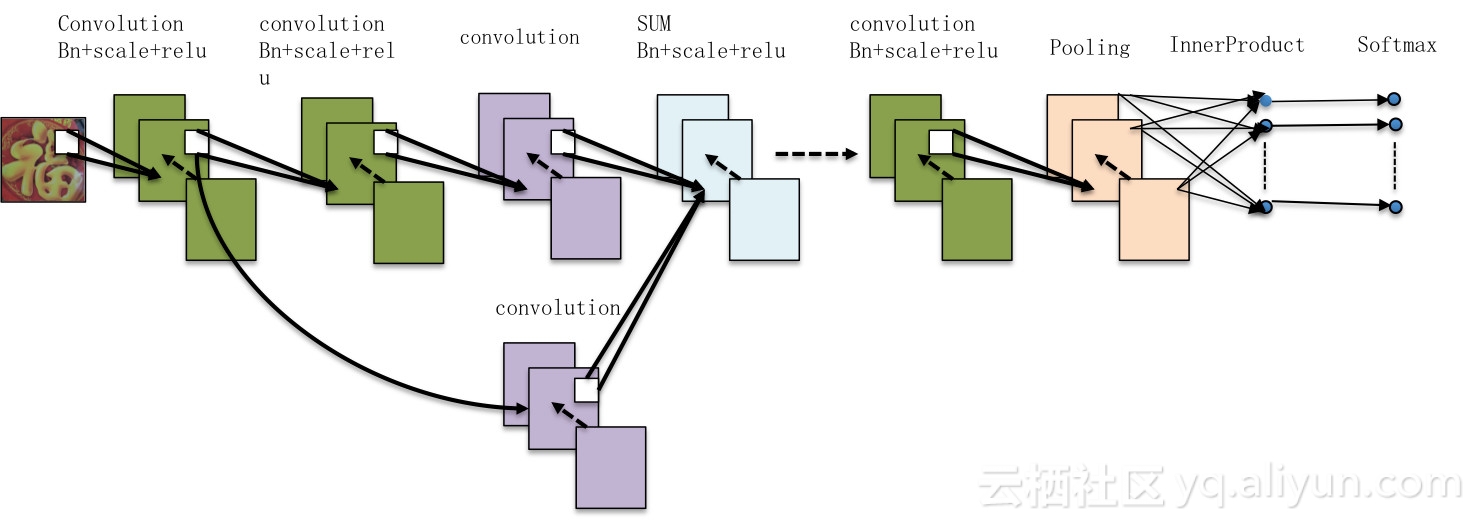
xFuNet性能特点如下:
-速度快(10ms),模型小(120k,可进一步压缩),识别率高,迭代快(低于2h)。
-服务业务场景:福字、手势、AR平台其它场景。
在福字识别的场景中,我们同MobileNet0.25进行了比较:

可以看出xFuNet虽然非常小,但是在特定场景校验部分表现的非常好,不逊色于一些开源的网络,更适合我们客户端需求大的场景。
在此前的活动中,我们积累了大量实拍的福字图片。为了实现识别率高、误识率低的目标,针对福字分类的训练投入了大量精力。
校验网络的目标是区分出形态各异的福字(敬业福、窗花、手写、门贴)、诸如“逼”、“祸”这类的负面相似字、其他负样本图,下图列出部分示例图:

不得不感慨汉字的博大精深,同一个字真的可以写出花来,但这同时加大了校验的难度,到底应该分为几类更合适?后续出现舆情如何能快速的增加特定图片同时尽量减少对福字识别率的影响。
分两类?所有的福字一类,非福字一类,显而易见这个方案不靠谱,类内差别过于大。那么福字与非福字具体怎么分合适呢?
福字:手写福(相对正规的打印福)和非手写福比划粗细结构各方面会有较大的不同,每个用户的手写福都有差别,连体多的手写福同逼字本身很难区分,因此福字至少分为两类,而敬业福属于特定设计福字,与其他福字分为一类也不合适,因此单独作为一类,这样福字分为三类。
非福字:对于非福字最简单的是分为一类,但是考虑到大部分用户不会完全随意的拍摄,我们的重点是逼、祸或者其他相似的字,同时舆情也大部分集中在这些字上面,因此将字类负样本同非字类分开。字类负样本和手写福字单独成类的另一个主要原因是增加了动态控制能力,这两类本身是容易分错出现舆情的类别,万一出现问题可以通过阈值的调整快速的解决一部分;同时后续优化模型的时候可以通过少量针对性样本进行finetune,训练快同时最有效;如果混为一类,当临时增加负样本时finetune样本比例不好控制,很可能引起保证福字检出率负样本的拦截率就不够,反之则会出现大幅度降低福字检出率的情况。
通过一系列的努力,2018年的扫福获得了不错的效果,相比2017年来说,相关指标——包括识别率和识别速度均有了大幅提升,实现了低于1%的误识率。回到开头,围绕扫福的负面声音今年也得到了有效控制,通过微博舆情监控我们可以明显感受到我们的努力没有白费。
有了去年的经验,经过一年的技术沉淀,2018年春节扫福字活动圆满结束,虽然过程中还是会碰到许多预期之外的问题,但是在团队共同努力下也都一一得到解决。在此,感谢红包项目各兄弟团队的鼎力支持和帮助,尤其是得益于多媒体部的另一项利器,XNN引擎对我们训练好的xFuNet网络模型进行有效的压缩,支撑其在客户端高效运行。
接下来,我们将继续丰富支付宝AR平台能力,比如红包期间沉淀的手势识别能力即将登陆AR平台,敬请期待。
点击[],查看更多详情