蚂蚁金服技术团队
分类: IT业界
2019-02-23 19:45:42
摘要:以“数字金融新原力(The New Force of Digital Finance)”为主题,蚂蚁金服ATEC城市峰会于2019年1月4日上海如期举办。金融智能专场分论坛上,蚂蚁金服数据平台部高级数据技术专家李俊华做了主题为《蚂蚁金服数据治理之数据质量治理实践》的精彩分享。
演讲中,李俊华介绍了蚂蚁金服数据架构体系的免疫系统——数据质量治理体系,此外还着重介绍了数据质量实施的相关内容,以及蚂蚁的数据质量治理实践与所面对的实际挑战。

李俊华 蚂蚁金服数据平台部高级数据技术专家
本文将主要围绕以下三部分进行分享:
1. 数据治理概况
2. 数据质量治理挑战
3. 数据质量治理实践
近年来,蚂蚁金服不断在数据架构上进行升级改造,其目的在于解决蚂蚁所面临的数据物理孤岛问题。如今,蚂蚁以及整个阿里巴巴集团的底座都统一到了同一个平台上,这样当实现第五代数据架构体系升级时,就降低了一站式研发的整体门槛,并使得蚂蚁金服的所有工程师都可以在平台上轻松玩转数据。如今,在蚂蚁的数据架构中已经能够很好地解决数据孤岛问题,而如今在数据治理体系中所需要关注的就是逻辑的孤岛。

在对数据治理展开论述之前,先谈一谈数据价值。之前的情况是,当数据首先需要经过专门团队负责处理,删除没有价值的数据,负责上线或者下线数据。但是,对于数据价值的判断也是一个非常令人头疼的问题,大部分的数据只会上线不会下线,这样就造成了大量没有价值的数据的堆积。而如今,蚂蚁不仅关心下线没有价值的数据,同时也侧重数据资产的价值最大化。在数据价值方面,蚂蚁有一套完整的数据资产等级以及数据资产的易用模型,这样就能够驱动自身充分利用数据资产,来创造更多的价值。但是如果这些数据被使用了,但是质量却很低,这样就会使得数据资产的价值大打折扣。
数据质量产生分析
接下来将重点介绍蚂蚁金服在数据治理质量领域的实践思路和方案,并与大家分享两个案例。如下图所示的是抽象数据抽取的全流程图。当某个业务同学录入数据的时候出现一点错误,就会造成数据的质量问题,比如把客户的行业信息填错或者打错了一个字都会造成数据质量问题,而这样的问题很容易出现。在基于传统数据库资产开发数据应用的时候,基本都是从数据源端产数据过来,经过加工、分析再将数据发送出去,也就是“从业务中来,最后回到业务中去”。现在的方案与之前存在很大区别,以前做数据处理时,从数据生产的采集数据来,加工之后就给出去了,而如今蚂蚁很多数据应用将数据处理之后还会回到数据系统中。比如芝麻信用分的计算中存在很多大家看不到的场景,这些数据处理之后还会回到系统之中,而这个过程中每个环节都可能存在数据质量问题。

在下图中的左侧展示了蚂蚁的业务形态。如今,蚂蚁的业务场景已经不再仅限于统计分析,而在蚂蚁的芝麻分、花呗、借呗以及“310”放款的背后都是数据在进行支撑并驱动着其发展。今天,蚂蚁的业务形态成为了“技术+数据+算法”三者的融合来追求价值最大化。与此同时,数据质量治理也存在着诸多挑战,它们来自于业务方面、数据方面、用户方面。

数据质量治理思路
从事金融业务的同学往往深有感触,互联网金融时代业务的生命周期缩短了很多,并且变化也非常频繁,相比于原本银行的节奏显得非常快。此外,目前无论是蚂蚁金服还是阿里巴巴都在谈“数据业务化、业务数据化”,数据和业务一同共同发展和前进,并且已经进入了发展的深水区。之前的几年,蚂蚁在业务上偏向于“T+1”,而如今,原来的架构体系不足以支撑蚂蚁未来继续发展以及高时效性的诉求。同时,如今蚂蚁的数据体量很大,而数据业务也驱动蚂蚁的整个人才体系的升级。现在,除了本身做数据算法研发的同学之外,其他的技术同学也都会在平台上使用数据,这些同学可能对于数据的认知不同,那么在数据驱动下真正保证数据质量就显得异常重要。
那么如何实现数据质量治理呢?首先,需要有一套明确的组织,这是持续建设企业文化的土壤,而数据质量治理文化的建设一定是一个确定的、有组织的并且需要长期持续推进的事情。在组织保障和质量文化的基础之上,蚂蚁还侧重了研发流和数据流。在金融领域,研发流的管控更严格,也更严谨。而对于如今的互联网金融而言,也需要进行强管控,这是因为业务形态决定了研发周期很短,现在蚂蚁在研发流做了强管控,在一站式数据研发平台上,使用了分级管控。需求提出之后就会被等级管理,并且进行打标,进而走入不同流程。此外,研发流上还侧重分级管控,在同一套标准上定义级别,拉平不同的研发流。对于数据流而言,当一个应用发布到生产环境之后,大部分精力花费在数据流中,每天需要从生产环境将数据采集到处理平台,然后运行算法计算,之后将数据返回到生产环境中,走这样的闭环。如今,蚂蚁在数据流链路上做了很多事情,也建设了很多能力。对于数据流而言,如果源头被污染了,如果不能控制其污染到下游,那么越往下修复成本就越大。
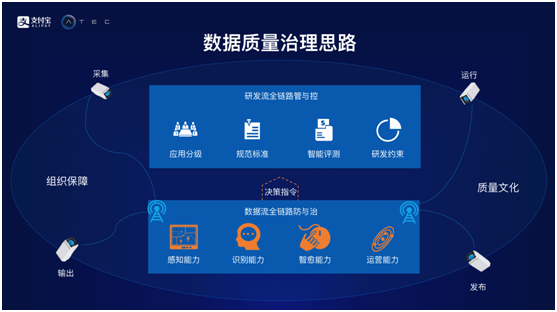
基于以上的数据质量治理思路,蚂蚁金服做了很多有意思的东西,在数据平台运行时会将整个体系监控起来,如果出现数据质量故障,就能够及时进行修复。此外,从研发到生产的各个环节,蚂蚁都做了大量的工作,这是因为基于平台进行数据研发的同学很多,需要尽量降低使用门槛。对于全数据流而言,主要建设了四大能力,包括感知能力、识别能力、智愈能力和运营能力。平台需要能够感知发布任务的故障问题以及数据质量问题,此外,平台需要能够识别出潜在风险,因为需要非常及时地了解被破坏的数据。当风险被识别出来之后,就需要智愈能力,之所以使用“智”,是因为原本数据处理任务往往是离线的,可能从凌晨开始到早上8点钟左右属于数据生产高峰,在这段时间里会有人员参与质量保障任务。而智愈能力就希望通过AI算法来配合数据处理工作,使得感知能力叠加算法能力,能够对于数据感染进行自愈。最后是运营能力,数据质量不会被展现在前台,如果数据质量足够好,完全可以实现无感知,使用者不用再担心数据能不能用,也不会出现敢不敢用的疑惑,因此数据质量对于运营而言也非常重要。其实,数据质量问题既不仅属于研发也不仅属于业务,而是需要全员参与,共同来解决,这就是数据治理的思路。
蚂蚁数据质量治理架构
如下图所示的是蚂蚁金服的数据质量治理架构体系。在系统层,按照上述所谈到的具体思路,研发阶段主要集中在数据测试、发布管控以及变更管理等方面的建设,这里着重提及变更问题,数据的变更不仅仅设计到系统层的变更管理,也会涉及到在线系统的相互打通。如今,在线数据源的变更,也会使得数据运营发生变更,更可能会导致数据运营的数据质量问题。在线研发部分为数据运营系统提供了一些相关的接口,能够通知使用者线上的哪些变更会影响到数据运营。对于发布管控能力而言,蚂蚁投入了大量精力进行研发。目前在蚂蚁已经没有专职负责数据测试的同学,基本上全部都是全栈工程师,所以对于研发而言可能管控不是非常强,但却实现了强大的发布管控能力,将与经验、规范、性能以及质量相关的检测全部在这部分执行。
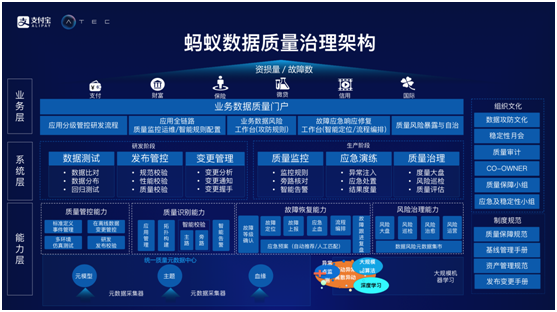
在生产阶段,则主要侧重于质量监控、应急演练以及质量治理这三个系统能力。质量监控告警系统能力在大部分的数据系统架构中应该都有,其功能类似于汽车的刹车功能,因此肯定是存在的。而蚂蚁却做了一件很有意思的事情——数据攻防演练,工程师会人为创造故障,然后测试系统能否在短时间内发现故障并进行有效修复,这部分也是目前蚂蚁在重点进行建设的能力。在质量治理部分,会根据不同应用的级别,发布到生产环境之后进行定期巡检,分析是否会影响数据质量。总之,对于数据质量架构体系的系统层而言,不仅原数据非常重要,如今更是结合机器学习来自动配置一些相关策略。
数据质量治理方案
如下图所示的是蚂蚁金服在实践中的事前、事中、事后的数据质量质量方案。整体而言,事前包括需求、研发、和预发三个阶段,而如今蚂蚁在事前可以做到的可管控、可仿真、可灰度。在事中,监控问题是重点建设的,出现问题不可怕,但是需要实现自主发现问题。而为了使得防御能力更强,蚂蚁实现了主动的攻击演练,而正是通过攻防演练,帮助蚂蚁发现了自身很多薄弱的地方。除此之外,还在事中提供了强大的应急能力,某些事件将会触发应急预案,在这部分,保证数据质量其实就是把不确定的数据风险变成确定的东西。在事后,数据质量也非常重要,事后需要通过有效的指标和管控手段来进行审计和度量,以此发现整个链路上不完善的地方并持续完善。

数据质量治理案例
最后为大家分享蚂蚁金服在数据质量治理方面的两个案例:
