蚂蚁金服技术团队
分类: 数据库开发技术
2019-01-28 14:47:56
颜然,蚂蚁金服 OceanBase 团队资深技术专家,OceanBase 初创成员之一,目前负责事务引擎以及性能优化相关的研发工作。
以下为演讲实录:
首先,我们先来聊一个大家都很感兴趣的话题:跟已有的经典数据库比如:Oracle、SQL Server等,OceanBase跟他们最大的区别在哪里?OceanBase是一个云原生的数据库。而我们所做的软件全部是基于硬件的基础之上。那么,我们首先就需要了解现在的硬件到底处在什么水平?

如上图所示,IBM的解决方案是最为大家所熟识的,从五十多年前的System 360到去年新出的IBM z14,时至今日依然还有很多机构在沿用这套解决方案。

我们每天都在说云计算,那么到底什么是云计算?云计算不是从石头缝里蹦出来的解决方案,它最早起源于DEC的小型机。DEC是和IBM大型机同时代的产物,以较低的价格解决存储和计算的需求。它与IBM大型机的区别在于:DEC价格低,获得方式更灵活。
DEC之后被基于芯片的解决方案打破了,诸如SUN工作站的解决方案提供了更好的性能和更低价格,平台也更通用。再之后PC Server接过接力棒,此时的CPU、内存、存储可以来自于不同的厂商,但大家组合起来以后仍然可以提供一套标准化的计算和存储的平台。
相比较IBM大型机,基于PC Server的数据中心以一种更产业链化的方式提供了计算和存储的解决方案,具有更好的性价比,也更易于扩展。但是IBM大型机是软硬一体化设计,这也是大型机满足需求可以采用很多硬件层面的解决思路。例如,金融业务对于高可靠性的需求,大型机是在硬件层面做了多种可靠性保障,从存储到内存甚至CPU都是有冗余策略来支持。但是PC Server的单台机器的故障率相对来说是高的,所以需要使用完全不同的思路来解决业务高可靠和高可用的需求。
此处引用OceanBase团队创始人阳振坤的一句话——“计算机天然不适合数据库,但数据库天然选择了计算机”。为什么计算机天然不适合数据库?因为在处理数据的时候,一个非常关键的问题就是数据的可靠安全和一致。而计算机的硬件天然具有各种概率的损坏,不管是掉电,软件出Bug,操作系统有问题,还是整个机房都挂掉,计算机是天然会出错的。但我们要解决的问题又是不能出错,所以在计算机上去解决数据库的可靠安全一致性的问题,其实是一个非常大的挑战。
要在一个更低可靠性的机器上实现更可靠的数据库的事务服务能力,这就是我们当前所面临的严峻挑战。
当然,有挑战的地方就有机遇。OceanBase在面对这样的挑战之下我们做了什么?在这样的一个基于PC Server的云化环境下,OceanBase实现了弹性扩展的能力,同时实现了不依赖高端硬件解决数据库事务的高可靠和高可用的能力。
OceanBase所依赖的硬件条件是一套通用的云化环境。但在这个硬件基础上,我们依然可以做到数据库的事务,同样能够实现高性能,甚至能够支撑金融级的可靠性。
何谓金融级可靠性?每个人都会有切身的感受。比如说你发了一条帖子,但是这条帖子丢了,你可能会不爽,但是不至于非常难受。再换一个场景,今天你给朋友转账100元,你朋友却只收到98元,此时你的内心一定是恐惧的。所以在这种金融级场景下,必须做到的就是为用户提供充足的保障,这就叫做金融级可靠性。但金融级可靠性的难度在于对细节的处理能力。细节是魔鬼,我们在做数据库软件的时候,需要对细节的把控能力极强。

这里要重点提到的几点,其实就延续着数据库事务的几个重要的特性。
OceanBase的架构基于LSM Tree。为什么会基于LSM Tree?它有哪些特点?
在经典的数据库里,所有的数据是分片保存在持久化存储里的,比如磁盘或者SSD。在读取数据的时候,一定要先把它放在内存里。当需要做修改的时候,也要把一块数据放在内存里。如果内存满了之后,就会把这个页面刷回去。

OceanBase所基于的LSMTree,可以把更多的修改更集中地放在一个内存结构里。我们的做法是在后台定期地做这件事情,前台把数据尽可能存更久的时间,然后再让后台去做合并。OceanBase有一个机制叫每日合并,也就是说如果前台能存一天的时间,我们到了每天夜里才做后台合并这件事情。
OceanBase会在系统内部做调度,第一台机器在后台刷脏页的时候,让业务的流量都跑在其他机器上,就可以不影响前台的业务。当第一台完成后,再把业务的流量切回来,然后让第二台机器做后台刷脏页的操作。我们通过这种“轮转合并”的方法解决在集群环境下利用不同机器不同服务的时间差去做刷脏页这件事情。
OceanBase事务引擎设计也利用了LSM Tree的结构,让事务的所有执行状态都保存在内存中,只有事务提交之后才会把事务修改的数据持久化。所以在实现事务原子性时,不需要做undo。这样OceanBase可以以一个更简洁的方式来做数据库的事务。这个就是OceanBase存储引擎的整体逻辑。
OceanBase的事务执行操作都在内存里发生。内存跟硬盘一个最大的差别,就是内存是可以以字节为单位进行随机寻址的,而这带来的一个非常大的好处就是使得数据结构更丰富了。
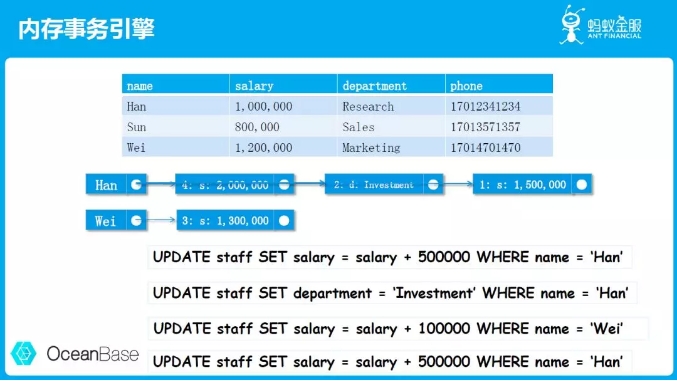
举个例子,如上图表格中的数据,现在要对第一行数据进行更新:条件是给Han加50万薪水。现在需要给这张表格中这一列对应的Han写一个新的值。在内存里的表示方法就是这样一个链表。如果Han涨了薪水以后突然希望换部门接受全新的挑战,我们就需要再做一次更新操作。只需要在这个列表里串上一次新的更新把他的部门进行更改。他从研发部门转到投资部门了,那我们就把这一列对应的修改记录在这里。
这个是数据库内部基于多版本的一种并发控制,记录了每一次更新发生的时间,保证了修改操作跟读取操作不会互相影响。因为即使一行数据被改了,我们还是可以直接拿到历史数据。基于链表的数据结构对程序员来说是非常友好的。
相比较经典的基于硬盘的数据库,无论数据读取还是写入都是定长数据块为单位的操作,表达信息的方式也是基于块的。OceanBase的方式带来的一个最大的好处就是大大提升了表达的简洁性,也就是它本身的操作效率要高特别多。这也解释了了为什么OceanBase能在目前的硬件环境下提供更强的事务处理能力,这是其中一个很重要的原因。
我们再回顾一下OceanBase的架构,OceanBase把数据分片了之后,可以在多个集群里的多台机器上把数据扩展出去做存储,它提供了线性扩展能力。

像上图所示同样一份数据会有多个副本,比如P0在三台机器上,这三台机器可能在同一个机房,也可能来自不同机房。但是它们会服务于同一份数据,其中只有一个是当前的主,它负责做数据库的操作,并且把数据库事务的修改同步到其他的机器上。我们这里提到OceanBase的数据组织与分布的目的就是要解决后面数据库的可靠性问题。
高可靠和高可用是被所有数据库产品广泛提及的概念。那么,可靠性和可用性到底意味着什么?
传统的数据库,ACID的理论里并没有availability这个概念,只保证了durable。但是数据不丢,却不一定能保证服务的连续性。但是failover的能力在实际的系统中却是非常重要的。所以所有的商业数据库都有对应的解决可用性的方案。其中经典的就是基于主备同步的方案,当主坏掉的时候,备可以继续提供服务,这就是在解决可用性的问题。

OceanBase采用Paxos协议来解决可靠性和可用性的问题。任何一个数据库的事务要做持久化,事务的日志都需要持久到多个副本上。在三个副本之中,我们认为只要持久化到两个副本的硬盘上,就定义为这个事务是成功的。也就是说有任何一台机器坏了的时候,至少还有一个副本在。
那么,反过来思考是不是同步到越多的机器上越好?如果三个副本都同步到,是不是就更加可靠了?这就是可用性所带来的问题,如果其中有一台机器网络出现故障,或者系统负载太高无法响应,你是否认为这个事务成功?
如果要求三个都成功的话,就不能认为它成功,因为有一台机器没响应。Paxos协议只要求两个机器同步到,就是即便有一个没有应答,我们依然认为这个事务是成功的,因为多数派成功了。
保证三个里面有一个坏掉是不受影响的,同时也不影响系统的持续服务。这是在可靠性和可用性中间的一个很好的平衡。如果你需要更高的保障,就可以选择五个副本的方案,这样可以保证有两台机器出故障的时候,同样既不影响可靠性,也不影响可用性,这是一个很重要的平衡点。
所以我们在ACID里再加入一个A,也就是我们既要让事务有可靠性,也要让事务的处理能力有可用性。
数据库在单机上写日志一定是只写自己机器上的日志文件,如果写成功了就成功,不成功就失败。但是在多台机器上的时候就涉及到:A机器成功了,B机器失败了。这件事情该怎么办?

两阶段提交协议的存在就是为了解决这个问题,也就是说提交再也不能是一次性就成功的,它要涉及到多个机器之间达成一致,每台机器都成功了最终才能定义为成功。
事实上,两阶段提交协议在实际应用中非常少。为什么呢?主要因为它很复杂,虽然理论很漂亮,但是存在的细节问题特别多。但是在OceanBase的业务场景下又一定要用两阶段提交协议来解决。
OceanBase的基础是每一个参与者都是高可用的,因为OceanBase使用了Paxos协议保证了Partition高可用,所以任何一台机器的故障不会导致服务停止,这是一个很重要的前提。另外,因为Paxos同步引入了跨网络、跨机房的同步延迟,原始的两阶段提交协议多次写日志会带来较多的开销,OceanBase做了一件事情就是让协调者不写日志,只保留内存状态。它带来的一个非常重要的好处就是commit延迟低。同时因为所有参与者都是高可用的,我们不会出现两阶段状态一般会出现的问题,比如协调者宕机卡住的问题。
事务隔离涉及到事务的并发控制怎么做,OceanBase使用的是多版本并发控制。读取请求会拿到当前系统的publish version作为读取的快照版本。事务提交的时候会生成一个版本号,版本号是连续递增的,作为本事务所有修改数据的版本。

单机场景下,一条日志就能决定这个事务最终是否能够提交。那么这条日志的位置就决定了这个事务的版本号,它的版本号一定是递增连续的。但是在分布式事务参与进来之后,举个例子,就会出现230可能是一条prepare日志,prepare日志不代表这个事务能够提交,但是232可能是另外一个事务的commit日志,这也就意味着这个事务要commit的话,232版本就需要可读,但是230又处在行锁未解事务进行中的状态。这个时候就需要另外一种控制方法,对于两阶段提交的prepare和commit之间的事务,这些事务所有操作的行要锁住,不允许读取。
这个影响很小是因为在prepare和commit之间不涉及到用户的任何干预,是一个毫秒级的操作,也就是说,这个行在提交的过程中会在一个很短的瞬间被锁住。这个瞬间里读取操作会等待事务提交掉,再去判断该不该读这一行的数据。
基于以上的技术创新,OceanBase真正实现了在云环境下事务的高可靠、高可用,同时还具有很好的性能。希望OceanBase可以帮助更多的业务解决数据存储和查询的需求,不再受困于传统商业数据库的价格高、扩展性差的问题。
