欢迎加入IT云增值在线QQ交流群:342584734
分类:
2006-04-24 17:18:55
2005年11月14日,Sun公司在美国旧金山宣布,最终产品名称确定为UltraSPARC T1的“Niagara”处理器芯片正式问世,这也是全球第一款商用CMT处理器芯片,标志着处理器发展发展历史上新纪元的到来。
“Niagara”这个代号取自位于美加边界的尼亚加拉大瀑布,意为“急流、洪水”,Sun公司用Niagara这一名称来形象的展现这一处理器在吞吐量方面的超前优势。本文将通过一系列文章向大家介绍:
•UltraSPARC T1中所采用的CMT(Chip Multithreading芯片多线程)技术,以及CMT技术所带来的服务器吞吐量方面的革命性变化。
•UltraSPARC T1的构造以及UltraSPARC T1的超高带宽,片上服务器(Server-on-a-chip)的技术特色。
•如何利用CMT技术,怎样在CMT系统上实现系统性能调优。
第一篇:什么是CMT技术
在本系列的第一篇中,我们将来探讨CMT诞生的背景,CMT技术的实质及其优势。
1.传统微处理器的发展瓶颈
当前,微处理器的发展日新月异。我们结合传统的X86处理器的发展局限性以及计算机应用的发展趋势向大家介绍CMT技术提出的背景。
1.1 传统通用微处理器体系结构的局限性
我们日常所见的以X86为代表的通用微处理器均是采用冯-诺依曼模型的单处理器单指令流芯片,以计算为中心的冯-诺依曼体系结构规定了计算机存储式程序(Stored Program)的运作方式,即CPU的处理所需的指令和数据只能经由存储器获得。
当前,传统的微处理器主要有如下三方面的发展局限性:
•内存带宽和访问延迟的限制
在摩尔定律的推动下,CPU的速度差不多每隔两年就提升一倍。然而,从目前的技术发展现状看,存储器的速度提高得很慢,基本上内存访问速度每隔六年才提升一倍。因此,这两者差距越拉越大,从而造成了CPU空算等待存储器的时间占了很大的比例。根据统计数据,在高主频的计算机中,有可能高达85%的时间浪费在等待内存的存取上。如果将处理器比作一个工厂的流水线,那么这就意味着,整个流水线大部分的时间都是空闲着,因为不能获取需要处理的原材料。
•指令级并行遭遇危机
为了提高处理器的性能,传统的解决方法是力图不断提高处理器的指令级并行性(ILP,Instruction Level Parallelism)。所谓ILP是指在处理器中引入多个功能部件(注意:是功能部件而不是处理器内核),例如:整型处理部件、浮点处理部件、加载/存储部件等,为处理器提供并发利用这些功能部件执行多条指令的能力。处理器负责挖掘指令间的并行执行能力,即:找出能够同时分别使用这些部件的不相干指令,在每个时钟周期内发送和执行尽可能多条指令。近年来,人们为了提高处理器的指令级并行度更是做了不懈的努力:一方面将一些原来应用于大型机的体系结构技术,例如:超标量,多级缓存,预测执行等指令级并行处理技术引入到微处理器芯片;另一方面,引入深度流水,将指令的执行划分为更多更细的流水级。
然而,相关技术的副作用以及计算类型的转变使得ILP技术已经难以满足处理器性能进一步增长的需求并可能成为约束处理器性能增长的主要因素。一方面,超长流水线引入了超大指令窗口,一旦转移预测失败,就势必要将多个预先加载的指令清空并重新加载新的指令,这一操作过程对于处理器的性能的影响是非常大的,往往会带来不可忽视的性能损失;另一方面,ILP本身也不再适应计算应用类型的变化了:ILP技术更多的适用于传统的计算密集型应用,这类应用中ILP程度较高,能够利用ILP类型的处理器提升应用的性能。而当代以商用事务处理和Web应用为代表的数据密集型的应用,其控制流非常不规则,ILP非常低,难以有效利用ILP技术提升性能。
•处理器主频的提升不再有效
伴随着指令流水线的不断细化,以及集成电路工艺水平的不断提高,微处理器的主频也在迅速提升。近年来,主频更是成为提升微处理器的性能的主要推动力:微处理器的主频迅速的完成了由90年33MHz到现在2GHz以上主频的飞跃。
但是,时至今日,主频的增长速度正日益趋缓,主频增长带来的副作用却日益显著。首先,主频的增长是以硬件设计和工艺的复杂度的提升为前提的。随着芯片集成度的增加和线宽变窄,处理器的设计、验证和测试变得越来越困难,为提高性能而增加的硬件资源利用率不高,性能的增长空间有限。相对而言,主频增长所带来的功耗的增长比性能的增长则要快得多。例如,从Intel 80486、Pentium、Pentium III到Pentium IV这4代处理器,整数性能提高了5倍左右,而晶体管数增加了15倍,相对功耗则增加了8倍。微处理器芯片呈现出更快、更大、更热的发展趋势。其次,主频增长依赖的超长流水线技术也使得分支预测失败后流水线指令清空和重新加载所需要的周期大为延长,所带来的性能损失大大削弱了主频提升所带来的性能增益。
不可否认,ILP技术以及主频的提升在一定程度上、一定时间内提高了计算机对于单一线程执行速度。然而,相对于CPU主频、复杂程度的提升,计算机的整体性能并没有取得相匹配的增长。这其中的主要原因就在于:从计算机体系结构的角度来看,传统的技术并不能有效、充分的利用计算机的整体硬件能力。
1.2 计算机应用的演变
时至今日,以商用事务处理和Web服务为代表的应用日益成为服务器应用的主流。回顾计算机的近30年发展历史,我们不难发现,计算机应用已经从传统的以SPEC CPU2000为代表的计算密集型的科学技术应用,发展到了现今的以SPEC JBB2000为代表的数据密集型应用,表现出完全不同的执行和数据访问的特征。
传统的计算密集型应用,对于数据的运算操作远远多于数据的装入操作,因而具备很高的代码和数据访问的局部性,能够有效的利用预取操作数、Cache等技术来弥补内存带宽的不足以及内存访问未命中所造成的时间延迟。
当前面向商用事务处理的主流服务器应用,则是数据密集型的应用。也就是说,这些应用所需数据的时间和空间局部性很差,数据重用的可能性很低。这时,传统的高性能计算机的构造方法就不能适应新的应用的需求了,具体表现在如下几个方面:
•传统的以计算为中心的体系结构(冯-诺依曼体系结构),不适应新应用类型中不规则的计算和内存访问特性,不适应这些应用中代码和数据局部性的变化。
•应用的并行算法模型与实际的并行体系结构不匹配,需要寻求与当前的新应用类型相匹配的有效并行算法和体系结构。
•计算,存储,I/O 的速度越来越不匹配,平衡体系结构的设计越来越困难。当前主流的商用微处理器主频均在GHz以上,存储总线主频还在MHz水平;处理器速度每年增长60%,存储器存取延迟每年仅改善7%。由通信带宽和延迟构成的“存储墙(Memory wall)”成为提高系统性能的最大障碍。
•传统的体系结构方法已跟不上摩尔定律的发展,大量浪费了摩尔定律所提供的计算潜力。
因此,和计算机应用的演变相适应,高端计算机的核心评价指标正在发生根本性的变化,从高性能计算(High-Performance Computing)转向高效能计算(High-Productive Computing),从强调单任务的性能到更多的强调多任务处理的吞吐量(Throughput)。正是基于这一认识,早在2003年,Sun公司在发布其今后处理器产品蓝图时,就已经将系统吞吐量计算(Throughput-computing)作为今后研发的重点。
所以,构建高主频、复杂的ILP处理器,并不能够解决传统的处理器体系结构中固有的问题。为了提高系统整体的性能,就势必要求突破传统的思路,开发ILP之外的更粗粒度的并行性。
2.TLP的提出
在这种情况下,线程级并行(Thread Level Parallelism, TLP)技术应运而生。TLP技术将处理器内部的并行由指令级上升到线程级,旨在通过线程级的并行来增加指令吞吐量,提高处理器的资源利用率。TLP处理器的中心思想是:当某一个线程由于等待内存访问结构而空闲时,可以立刻导入其他的就绪线程来运行。这样,处理器流水线就能够始终处于忙碌的状态,系统的处理能力提高了,吞吐量自然也相应提升了。我们可以从下面示意图的比较看出TLP相对于ILP的优势。
图1中,传统的ILP方式下,单纯的提高CPU的运算速度,对于整个系统性能的提升所起到的作用微不足道。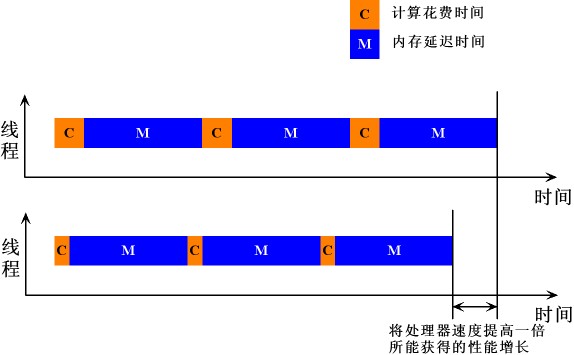
图1:考虑到内存访问所耗费的时间,将单线程处理器的运算速度提高一倍,对于整个应用处理速度的提升所起的作用非常有限。
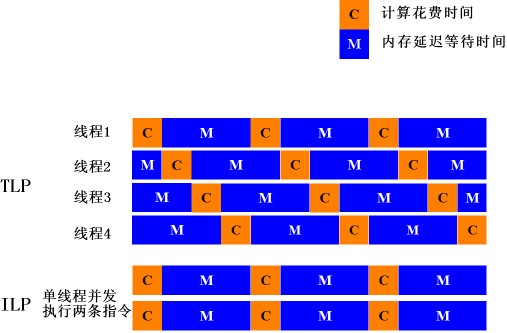
图2: TLP通过注入多个线程来削减系统内存访问延迟带来的副作用
在图2示意的TLP处理器的理想状态中,由于内存访问而导致的延迟可以经由导入其他线程的执行而抵消。相对而言,ILP只能够缩短指令在CPU中的执行时间,却不能有效改善由于内存等待而造成的延迟。(注:使用乱序执行(out-of-order)的ILP处理器能够小幅度利用内存等待的延迟来执行指令)。当前处理器的运行速度普遍都在GHz的水平,性能瓶颈转移到内存和I/O的延迟,较之于ILP,在解决I/O和内存访问延迟方面,TLP具备显著的优势。
TLP不仅仅是单纯从技术角度提出的学术观点,而且也符合了服务器应用的特征。现今的网络计算环境从本质上来说就是多线程的,这就决定了相对于整体的吞吐量而言,单个线程的执行速度并不那么重要了。这也可以解释:对于服务器端的企业级商务应用,传统的ILP方式的高主频系统并不能够有效的提升系统的效能。下表给出了一些实际服务器应用的具体情况。从表中可以看出,许多典型的服务器端应用需要处理大量的并发线程的能力,而并不是提高单线程的执行速度。换言之,对于服务器的并发工作环境,TLP才是提升性能的王道。
|
负载特性 |
Web-Centric |
Application-Centric |
Data-Centric | |||
|
性能指标 |
Web (SPECweb99) |
Application (SPECjAppServer2002) |
SAP-SD 2Tier |
Data TPC-C |
SAP_SD 3Tier (DB) |
DSS TPC-H |
|
应用类型 |
Web服务器 |
应用服务器 |
ERP |
OLTP |
ERP |
DSS |
|
指令级并行度 |
低 |
低 |
中 |
低 |
低 |
高 |
|
线程级并行度 |
高 |
高 |
高 |
高 |
高 |
高 |
|
指令/数据工作集 |
大 |
大 |
中 |
大 |
大 |
大 |
|
数据共享 |
低 |
中 |
中 |
高 |
高 |
中 |
表1:常见的服务器端企业级应用中的指令级并行度和线程级并行度的比较
现在,业界普遍认为,TLP将是下一代高性能处理器的主流体系结构技术,ILP将仅仅成为TLP中表示性能的辅助参数。
3.SMP技术
SMP的全称是“对称多处理”(Symmetrical Multi-Processing)技术,可以看作是一种从宏观角度支持TLP的体系结构技术。SMP是指在一个计算机上汇集了多个CPU,各CPU之间共享内存子系统以及总线结构。它是相对非对称多处理技术而言的、应用十分广泛的并行技术。在这种架构中,一台电脑不再由单个CPU组成,而同时由多个处理器运行操作系统的单一复本,并共享内存和一台计算机的其他资源。虽然同时使用多个CPU,但是从管理的角度来看,它们的表现就像一台单机一样。系统将任务队列地分布于多个CPU之上,从而极大地提高了整个系统的数据处理能力。所有的处理器都可以平等地访问内存、I/O和外部中断。在对称多处理系统中,系统资源被系统中所有CPU共享,工作负载能够均匀地分配到所有可用处理器之上。SMP技术是高性能服务器和工作站级主板架构中提升性能的有效手段,像某些UNIX服务器可支持高达256个CPU的SMP系统。
然而,传统的SMP系统内部的多个处理器通过片外总线互连,共享总线带宽,传统总线所固有的低带宽、高延迟已经成为SMP系统的性能瓶颈。在SMP方面的一种发展趋势就是将SMP系统搬到一块芯片内部,利用片内的高带宽总线来代替片外总线,实现片内高带宽的SMP超级计算机。
4.CMT=CMP+MT
4.1 CMP-单芯片多处理器=片内SMP
TLP的研究已经开展许多年了,学术界提出了多种实现方式,其中又以Stanford大学的单芯片多处理器(CMP, Chip Multi-Processor)的Hydra CMP为典型代表。CMP的基本思想是在单个芯片上实现SMP,每一个处理器核心实质上都是一个相对简单的单线程处理器。CMP允许线程在多个处理器内核上并行执行,从而利用线程级并行性来提高系统性能。下图是Hydra CMP的体系结构。可以看出CMP主要是依赖SMP体系结构来实现TLP的。
图3. Hydra CMP的结构示意图
4.2 MT-多线程处理器(Multi-threading Processor)
为了理解CMT,我们还有必要看一下多线程处理器(Hardware Multithreading)。顾名思义,多线程处理器是在一个处理器内核中提供支持多个“硬”线程(Hardware Thread)的能力,通常由处理器内核为每个线程维护独立的处理器状态,包括寄存器与程序计数器PC等,并能够快速地切换线程上下文。由于多线程处理器在遇到延迟事件时,可以将线程迅速切换去执行另外一部分程序代码,从而有效避免了将时间浪费在延迟等待上。下图中给出了一个支持硬件多线程技术的CPU在四个硬线程之间切换的情况,可以看出,在这种方式下,处理器的流水线始终保持在满负荷的工作状态,即便是某些线程由于内存访问被阻塞。图3. Hydra CMP的结构示意图
4.2 MT-多线程处理器(Multi-threading Processor)
为了理解CMT,我们还有必要看一下多线程处理器(Hardware Multithreading)。顾名思义,多线程处理器是在一个处理器内核中提供支持多个“硬”线程(Hardware Thread)的能力,通常由处理器内核为每个线程维护独立的处理器状态,包括寄存器与程序计数器PC等,并能够快速地切换线程上下文。由于多线程处理器在遇到延迟事件时,可以将线程迅速切换去执行另外一部分程序代码,从而有效避免了将时间浪费在延迟等待上。下图中给出了一个支持硬件多线程技术的CPU在四个硬线程之间切换的情况,可以看出,在这种方式下,处理器的流水线始终保持在满负荷的工作状态,即便是某些线程由于内存访问被阻塞。
图3. Hydra CMP的结构示意图
4.2 MT-多线程处理器(Multi-threading Processor)
为了理解CMT,我们还有必要看一下多线程处理器(Hardware Multithreading)。顾名思义,多线程处理器是在一个处理器内核中提供支持多个“硬”线程(Hardware Thread)的能力,通常由处理器内核为每个线程维护独立的处理器状态,包括寄存器与程序计数器PC等,并能够快速地切换线程上下文。由于多线程处理器在遇到延迟事件时,可以将线程迅速切换去执行另外一部分程序代码,从而有效避免了将时间浪费在延迟等待上。下图中给出了一个支持硬件多线程技术的CPU在四个硬线程之间切换的情况,可以看出,在这种方式下,处理器的流水线始终保持在满负荷的工作状态,即便是某些线程由于内存访问被阻塞。
图3. Hydra CMP的结构示意图
4.2 MT-多线程处理器(Multi-threading Processor)
为了理解CMT,我们还有必要看一下多线程处理器(Hardware Multithreading)。顾名思义,多线程处理器是在一个处理器内核中提供支持多个“硬”线程(Hardware Thread)的能力,通常由处理器内核为每个线程维护独立的处理器状态,包括寄存器与程序计数器PC等,并能够快速地切换线程上下文。由于多线程处理器在遇到延迟事件时,可以将线程迅速切换去执行另外一部分程序代码,从而有效避免了将时间浪费在延迟等待上。下图中给出了一个支持硬件多线程技术的CPU在四个硬线程之间切换的情况,可以看出,在这种方式下,处理器的流水线始终保持在满负荷的工作状态,即便是某些线程由于内存访问被阻塞。图3. Hydra CMP的结构示意图

图3. Hydra CMP的结构示意图
4.2 MT-多线程处理器(Multi-threading Processor)
为了理解CMT,我们还有必要看一下多线程处理器(Hardware Multithreading)。顾名思义,多线程处理器是在一个处理器内核中提供支持多个“硬”线程(Hardware Thread)的能力,通常由处理器内核为每个线程维护独立的处理器状态,包括寄存器与程序计数器PC等,并能够快速地切换线程上下文。由于多线程处理器在遇到延迟事件时,可以将线程迅速切换去执行另外一部分程序代码,从而有效避免了将时间浪费在延迟等待上。下图中给出了一个支持硬件多线程技术的CPU在四个硬线程之间切换的情况,可以看出,在这种方式下,处理器的流水线始终保持在满负荷的工作状态,即便是某些线程由于内存访问被阻塞。
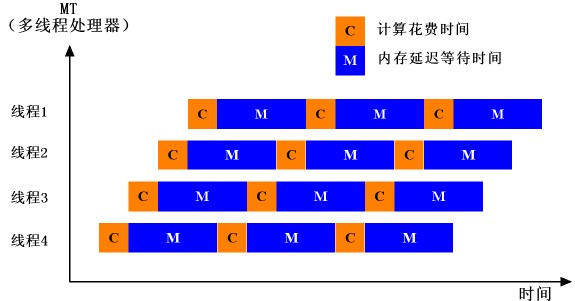
图4:多线程处理器在不同的硬线程间切换,这样就能保持CPU满负荷的工作,即便是某些线程由于内存访问延迟被阻塞。
我们小结一下,多线程处理器MT赋予CPU在多个线程中转换处理的能力,是一个超标量处理器内核。一个CMP是由若干个单线程处理器以SMP(对称多处理器系统)方式构成的支持TLP的系统,如果我们用MT处理器去置换CMP中的一个个的单线程处理器内核,使用多线程处理器来构造SMP方式的TLP系统,岂不是锦上添花?没错,这种将CMP和MT相结合的创新就是CMT技术。
4.3 片上多线程Chip Multi-threading (CMT)
简言之,CMT就是在一块芯片上集成多个MT处理器内核所构造的支持TLP的SMP系统。和极为复杂的传统单线程处理器不同,CMT技术采用相对简单的多线程处理器核心。每个处理器核心都维护多个线程,线程一直保持运行状态直到被阻塞,这时流水线将立即切换到另外一个就绪的线程。CMT处理器的一个天生优势是:由于这些单个的处理器核心的流水线相对简单,它们的制备不那么复杂,因而能耗低,散热量小。下图示意了一个4核的CMT技术的CPU,支持并发16个线程。

图5:采用4核,每核4线程的CMT处理器能够支持16个并发执行的硬线程
由于CMT采用了可以采用相对简单的多线程微处理器作为处理器核心,使得CMT主要具有以下优点:
•设计和验证周期短:微处理器厂商可以基于成熟的多线程处理器作为处理器核心,从而缩短设计和验证周期。
•控制逻辑简单,扩展性好,易于实现。
•功耗低:一方面,CMT技术是通过TLP方式来追求高吞吐量的效能计算,无需过分追求单个内核的高主频,不存在高主频引起的高功耗;另一方面,还可以通过动态调节电压/频率、负载优化分布等,有效降低处理器的功耗。
•片内高带宽通讯:CMT处理器相当于是将一个SMP系统集成于一块芯片内部,绝大部分信号局限于处理器核心内,包含极少的全局信号,因此线延迟对其影响比较小。利用现有的工艺水平,可以提供片内高带宽的通讯方式。
4.4 CMT:吞吐量运算和性能的有力保障
CMT技术,通过引入全新的体系结构来尽可能充分的利用系统的资源,提高系统的吞吐量。一方面,系统由多个实实在在的处理器内核构成,确保系统多发射的有效执行。另一方面,每一个内核内部又是多线程的,执行部件在各个硬线程之间迅速切换,又能够进一步提高系统的利用率,提高并发执行的指令数目,提升系统的吞吐量。可以说,这种全新的体系结构为提升应用程序的性能提供了有效的保证。我们来具体看一下CMT处理器体系结构的运行特征。
首先,相对于传统的单内核处理器,CMT处理器中提供了物理上而非逻辑上的多个处理器内核,提供了多套执行部件。这样的系统,无需借助复杂的硬件分析设备或者复杂的编译器,就能够真正并发处理多个指令,而不用考虑指令之间的相关性。
其次,相对于单线程的处理器而言,CMT处理器能够大幅度抵消内存访问延迟带来的副作用。当某一个线程由于内存访问而必须等待时,传统的单线程机器必须作一系列的空闲操作等待内存访问的结果,而CMT则可以迅速切换到另外一个就绪的线程,忽略前一个被阻塞的线程,这样,内存访问所造成的延迟就有可能最大程度上的被CMT的线程切换能力所屏蔽了。如果从CMT内部来看,则是每一个多线程处理器内部的流水线都能够经常性的保持满负荷的运作,不断的处理就绪的线程。所以,CMT处理器内部的处理效能就大大提高了,不用把能耗浪费在无用的空闲操作上。
另一方面,我们也必须牢记CMT的设计初衷:CMT是为了提高系统的吞吐能力,而不是为了提高单个线程的执行速度。正因为如此,单线程的程序在CMT上运行一个实例时的性能可能不如在传统的单线程处理器上运行的性能好。这主要是由两方面的原因造成的:
•首先,单一的线程并不能独享处理器的所有资源,而必须和其他的硬线程来分享,为其他的硬线程让出一些时间片,所以整体的运行时间反而慢了。(注:对于良好设计的CMT处理器,可以通过软件指令动态关闭单个内核中的多个线程,使得各个内核以单线程方式来运行)。
•其次,在绝大多数的CMT处理器中,每个处理器内核的流水线都相对简单,不如同时期的单线程处理器来得复杂和功能强大,这也是造成单线程应用在CMT上运行较慢的原因。
所以,必须牢记:CMT处理器实质上是一种TLP系统,利用并发运行多个线程所获得的吞吐量来换取性能的。为了充分利用CMT,就必须使得系统能够获得充足的线程级并发任务输入,确保系统能够“吃饱”,才能够让系统“跑得快”!例如:针对上面的单线程应用的特殊例子,我们可以同时在CMT系统上同时运行该应用的多个实例。这样,虽然单个实例不如在某些单线程处理器系统上跑的快,但是,就整体而言,系统的吞吐量却能够取得质的飞跃。具体的技术我们会在后面介绍。
第四点,由于在CMT的每个处理器内核中,多个硬线程会共享核内的某些部件,所以某一个线程的性能会受到其他运行线程的影响,这些影响可以是正面的,也可能是负面的。下面列举了一些典型的情况:
•如果一个线程由于内存访问被阻塞了,原本分给它的时间片会立即转让给该核内的其他就绪线程,提升系统的利用率。
•如果多个线程都在运行同一个应用程序(这种情况在服务器应用中非常普遍),这些线程能够在片内的L2级缓存中共享代码和数据,并由此获得很多性能增益。
•如果同一个内核中的多个硬线程都不曾出现内存或I/O访问阻塞(这在当前的商用服务器应用中非常少见),那么各个线程只能均分该处理器内核的处理能力。
•如果一个内核中的某个硬线程不当的刷新了核内的相关缓存以及TLB(注:TLB (Translation Look-aside Buffer)是处理器内部的一片存储区域,用若干个表项存储处理器最近访问过的页面信息,每一项中包括了程序中的虚地址和对应的内存中的绝对地址。由于使用TLB来查询地址可以无需经过传统的地址转换流程,所以能够加速内存访问,提高处理速度),该核内的其他线程可能会因此收到影响而降低性能,这种情况被称作“破坏性共享(Destructive Sharing)”
4.5 什么样的程序适合在CMT处理器上运行
CMT处理器适应于追求吞吐量的应用,特别是面向Web和商用事务处理的应用。那么是不是只有基于多线程技术的应用程序才能够利用CMT处理器的特征,提升性能呢?答案并不是这么简单。我们在下面列举了一系列适用于CMT处理器的应用类型。
•多线程的本地应用(Native application):这种多线程的应用的特征是具备一定数量的多线程进程,线程之间可以通过共享全局变量进行通讯,通过操作系统对线程的调度让负载在系统中很好的分布。这样的多线程应用包括IBM的Lotus Domino以及Siebel的CRM系统。
•多进程应用(Multi-process application):多进程的应用由多个单线程的进程组成,这些进程之间的通讯多使用共享存储(Shared Memory)或者进程间通讯(IPC)的机制。多进程的应用包括:Oracle数据库,SAP,以及PeopleSoft。
•Java应用:Java技术为应用提供了支持多线程技术的强有力的保证。一方面,使用Java语言能够非常便捷的开发多线程应用,特别是在Java 5.0中,多线程的开发变得更为简便、直观。另一方面,Java虚拟机本身就是多线程的:JVM中使用多个线程来实现任务的调度和内存的管理。Java应用程序,特别是Java的应用程序服务器,例如Sun公司的Java Application Server,BEA的Weblogic,IBM的WebSphere,Apache的TomCat等,都能够借助CMT技术大幅提高性能。同样,部署在这些应用服务器之上的各种应用也都能够相应的获得性能的大幅提升,提高各自的吞吐量。
•多实例的应用程序(Multi-instance application):如果某些应用程序无法充分利用多线程技术将负载在CMT处理器上分布开的话,我们可以通过在CMT架构的系统上并发运行该应用程序的多个实例来获取性能的提升。当然,这种运行方式可能会需要操作系统的支持,例如:由操作系统来实现各个运行实例之间一定程度上的隔离。这时,可以借助于操作系统提供的虚拟化技术将整个系统划分为若干个独立、安全的逻辑子系统,每个实例运行在一个子系统中。Sun公司的Solaris操作系统种所提供的Container技术就是实现这样逻辑子系统的一种非常优秀的技术。
从这里可以回答我们前面提出的问题:对于单线程的应用,通过运行应用的多个实例,同样可以让它们在CMT上飞速运作!
当然,CMT也并非是万能的,不是所有的应用程序都适合运行在CMT系统上。某些应用程序如果不能将负载很好的在CMT架构上很好的分布,就不能够利用CMT的特性。例如:
•某些单线程应用的运行需要很长的时间,如果不能够以多个实例的方式并发的运行,就不适合在CMT系统上运行。
•同样的,以单线程方式运行的批处理类型的应用程序,往往也不太适合CMT架构。
随着CMT技术日臻成熟,当前业界对于CMT应用的一个主要问题自然而然的落在软件方面:必须要有一个同CMT相配套的操作系统为用户提供使用CMT强大功能的良好接口;同时还要考虑到许多传统软件的存在,能否将传统软件无缝的移植到支持CMT技术的操作系统上;第三就是良好的开发环境,为用户提供方便的软件开发包,充分利用CMT的高线程并发能力。
在本系列的第一篇文章中,我们向大家介绍了CMT的提出背景,TLP技术,CMT技术的实质、性能优势以及所适用的场合。在第二篇中,我们将向大家展示采用CMT技术的第一款商用处理器,UltraSPARC T1的技术特色。
作者简介:
黄鹏现在在Sun公司的Global Partner Engineering/East Asia部门工作,是Sun公司的资深技术顾问。他的经验包括:为ISV提供系统设计、系统架构方面的咨询;指导和帮助ISV使用J2EE技术和Solaris操作系统开发、移植产品;指导和帮助ISV对其产品进行压力测试并定位和解决从编码,中间件、操作系统配置,网络直至硬件架构的各个层面的系统性能瓶颈。利用Sun公司的Java Enterprise System中间件套间和Solaris 10操作系统,并结合他丰富的工程经验,他已经成功的帮助多个ISV大幅度的提升应用的性能。
