来自农村的老实娃
分类: Oracle
2011-08-03 14:45:50
结果缓存有何不同?我们之前讨论过,结果缓存提供了极大的优势,因为查询的最终结果存储在共享池的一个单独部分中,之后,当用户执行相同的查询时,进程不必遍历缓冲区缓存中的数百万行,而是可以跳过这一步,从共享池的结果缓存部分中检索数据。
在 Oracle RAC 环境中,如果从一个实例多次执行查询,过程并无不同;将从结果缓存中检索结果。那么,有什么区别吗?实际上,可以说有,也可以说没有。区别体现在集群中的第二个实例使用 /*+ RESULT CACHE */ 提示执行相同的查询时。不是从 I/O 子系统获取所有行(如我们在方法 1 中看到的那样),而是仅传输来自结果缓存的结果。
在 Oracle RAC 环境中,这是一项极大的优势,可减少互连流量或 I/O 子系统调用。那么,文档中为什么说结果缓存是实例本地的?因为它确实如此。在 Oracle RAC 环境中,不存在全局结果缓存;结果缓存在实例的共享池内本地维护。(参见图 3。)
我们来通过一次练习逐个步骤地讨论 Oracle RAC 环境中的这项特性。
第 1 步
让我们来看看,为结果缓存部分分配了多少缓存,目前有多少缓存可用。可使用以下方法确定共享池的结果缓存部分的当前使用率:
SQL>SET SERVEROUTPUT ON; SQL>execute DBMS_RESULT_CACHE.MEMORY_REPORT(TRUE); R e s u l t C a c h e M e m o r y R e p o r t [Parameters] Block Size = 1K bytes Maximum Cache Size = 251680K bytes (251680 blocks) Maximum Result Size = 12584K bytes (12584 blocks) [Memory] Total Memory = 12784 bytes [0.000% of the Shared Pool] ... Fixed Memory = 12784 bytes [0.000% of the Shared Pool] ....... Memory Mgr = 200 bytes ....... Bloom Fltr = 2K bytes ....... = 2088 bytes ....... Cache Mgr = 5552 bytes ....... State Objs = 2896 bytes ... Dynamic Memory = 0 bytes [0.000% of the Shared Pool]
共享池的结果缓存部分还可通过对 v$sgastat 视图进行查询来验证。
SQL> SELECT * FROM gv$sgastat WHERE POOL='shared pool' AND NAME LIKE 'Result%' AND INST_ID =1;
INST_ID POOL NAME BYTES
------- ----------- ---------------------------------- ----------
1 shared pool Result Cache: State Objs 2896
1 shared pool Result Cache: Memory Mgr 200
1 shared pool Result Cache: 2088
1 shared pool Result Cache: Cache Mgr 5552
1 shared pool Result Cache: Bloom Fltr 2048
上面的输出和之前内存报告生成的输出表明了相同的统计信息。
在上面的输出中,我们注意到,没有为结果缓存部分分配共享池的任何内存(0.000% 的共享池)。结果缓存是从共享池的动态内存部分分配的。
我们还可以使用以下查询间接验证是否出现了任何对象。该查询将列出结果缓存中当前存储的所有对象。
SQL> SELECT INST_ID INT, ID, TYPE, CREATION_TIMESTAMP, BLOCK_COUNT, COLUMN_COUNT,
PIN_COUNT, ROW_COUNT FROM GV$RESULT_CACHE_OBJECTS;
第 2 步
让我们在实例 1 (SSKY1) 上使用 /*+ RESULT CACHE */ 提示执行查询。
SELECT /*+ RESULT_CACHE */ OL_W_ID, OL_D_ID, OL_NUMBER, sum(OL_AMOUNT),sum(OL_QUANTITY)
FROM
ORDER_LINE OL, ORDERS ORD WHERE OL.OL_O_ID = ORD.O_ID AND OL.OL_W_ID =
ORD.O_W_ID AND OL.OL_D_ID = ORD.O_D_ID GROUP BY OL_NUMBER, OL_W_ID, OL_D_ID
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.01 0.02 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 21 33.85 97.00 346671 346755 0 300
------- ------ -------- -------------------- ---------- ---------- ----------
total 23 33.86 97.03 346671 346755 0 300
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Parsing user id: 89 (TPCC)
Rows Row Source Operation
------- ---------------------------------------------------
300 RESULT CACHE 8fbjhchhd9zwh7uhn4mv7dhvga (cr=346755 pr=346671 pw=0 time=1046 us)
300 HASH GROUP BY (cr=346755 pr=346671 pw=0 time=299 us cost=126413 size=4950 card=150)
21541174 HASH JOIN (cr=346755 pr=346671 pw=0 time=84263640 us cost=125703 size=680920944 card=20633968)
2153881 INDEX FAST FULL SCAN ORDERS_I2 (cr=11664 pr=11635 pw=0 time=566756 us cost=2743 size=22694870 card=2063170)(object id 86234)
21541174 INDEX FAST FULL SCAN IORDL (cr=335091 pr=335036 pw=0 time=62691616 us cost=87415 size=453947296 card=20633968)(object id 86202)
从 10046 跟踪事件中收集到的统计信息的第一部分与非结果缓存操作相同。如图 3 所示,从 I/O 子系统读取了大约 340,000 行(第 1 步),并且遍历了缓冲区缓存(第 2 步)来获得 300 个汇总行的结果,这些行随后将加载到共享池的结果缓存部分中(第 3 步)。
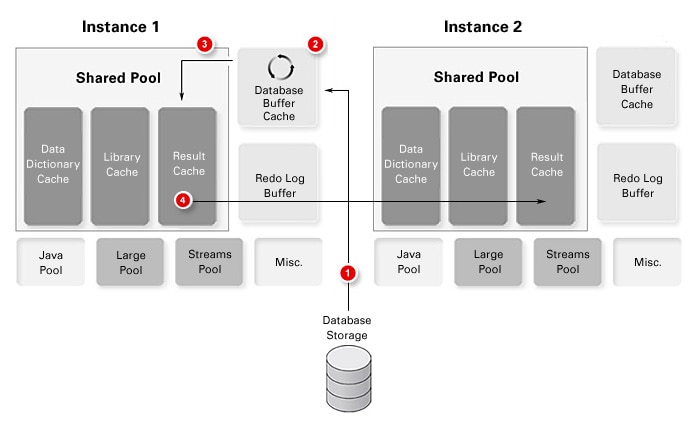
图 3 Oracle RAC 环境中的结果缓存行为
第 3 步
我们来检查一下结果缓存部分,看看能发现什么。
SQL>SET SERVEROUTPUT ON; SQL>execute DBMS_RESULT_CACHE.MEMORY_REPORT(TRUE); R e s u l t C a c h e M e m o r y R e p o r t [Parameters] Block Size = 1K bytes Maximum Cache Size = 251680K bytes (251680 blocks) Maximum Result Size = 12584K bytes (12584 blocks) [Memory] Total Memory = 207000 bytes [0.004% of the Shared Pool] ... Fixed Memory = 12784 bytes [0.000% of the Shared Pool] ....... Memory Mgr = 200 bytes ....... Bloom Fltr = 2K bytes ....... = 2088 bytes ....... Cache Mgr = 5552 bytes ....... State Objs = 2896 bytes ... Dynamic Memory = 194216 bytes [0.004% of the Shared Pool] ....... Overhead = 161448 bytes ........... Hash Table = 64K bytes (4K buckets) ........... Chunk Ptrs = 62920 bytes (7865 slots) ........... Chunk Maps = 31460 bytes ........... Miscellaneous = 1532 bytes ....... Cache Memory = 32K bytes (32 blocks) ........... Unused Memory = 23 blocks ........... Used Memory = 9 blocks ............... Dependencies = 2 blocks (2 count) ............... Results = 7 blocks ................... SQL = 7 blocks (1 count)
一次查询执行改变了内存报告。0.004% 的动态内存部分分配给结果缓存部分用于存储 9 块数据。这 9 块数据背后的数学原理是怎样的?两个块分配给作为查询一部分的相关对象(ORDER_LINE 和 ORDERS),7 个块分配给查询的结果集。结果集中有 5 列的数据类型均为 NUMBER,结果中包含 300 行。这大约相当于 5.5 个数据块,约等于 6 个数据块,另有一个块用于查询元数据。
注意:结果缓存块大小不应与数据块大小混淆。如报告所示,结果缓存块大小为 1K,数据库块大小为 8K。
结果缓存中存储的一种可检查对象的有用视图就是 V$RESULT_CACHE_OBJECTS 视图。它提供了结果缓存中包含的大多数信息,包括底层数据或对象更改时的对象相关性和失效。
以下数据子集来自 V$RESULT_CACHE_OBJECTS 视图,提供了与查询及其结果相关的基本信息。输出列出了两个相关项和一个结果。结果还包含其他信息,如结果集中的列数和总行数。
SQL> SELECT inst_id INT, ID, TYPE, CREATION_TIMESTAMP, BLOCK_COUNT, COLUMN_COUNT, PIN_COUNT, ROW_COUNT FROM GV$RESULT_CACHE_OBJECTS WHERE INST_ID=&&instNum;
INT ID TYPE CREATION_ BLOCK_COUNT COLUMN_COUNT PIN_COUNT ROW_COUNT
----------------- -------------------------------- ---------- ---------
1 1 Dependency 09-FEB-10 1 0 0 0
1 0 Dependency 09-FEB-10 1 0 0 0
1 2 Result 09-FEB-10 7 5 0 300
以下输出列出了查询(相关项)所使用的全部对象以及存储为结果的查询本身。如本练习的第 1 步所述,结果缓存的区域由一个名为 CACHE_ID 的 ID 标识。只要查询完全相同,Oracle Database 11g 每次将生成相同的 CACHE_ID,无论查询执行了多少次,跨集群中的多少个实例执行。
SQL> SELECT INST_ID INT, ID, TYPE, STATUS, NAME, OBJECT_NO OBJNO,CACHE_ID,INVALIDATIONS INVALS
FROM GV$RESULT_CACHE_OBJECTS WHERE INST_ID=&&instNum;
INT ID TYPE STATUS NAME OBJNO CACHE_ID INVALS
---- --- ---------- -------- -------------------------------- ------ -------------------------- ------
1 1 Dependency Published TPCC.ORDERS 86209 TPCC.ORDERS 0
1 0 Dependency Published TPCC.ORDER_LINE 86201 TPCC.ORDER_LINE 0
1 2 Result Published SELECT /*+ RESULT_CACHE */ OL_W_ID 0 8fbjhchhd9zwh7uhn4mv7dhvga 0
,OL_D_ID,OL_NUMBER,sum(OL_AMOUNT),
sum(OL_QUANTITY) FROM ORDER_LINE O
L, ORDERS ORD WHERE OL.OL_
注意:在 OBJECT_NO (OBJNO) 列中找到的值对应于 DBA_OBJECTS 视图中 OBJECT_ID 列的值。
继续观察在 V$RESULT_CACHE_OBJECTS 视图中找到的数据子集,以下输出列出了此操作的结果部分的当前空间占用率。
SQL> SELECT INST_ID INT,ID,TYPE,BLOCK_COUNT BLKCNT,COLUMN_COUNT CLMCNT,SCAN_COUNT,ROW_COUNT RCNT,ROW_SIZE_MAX RSM,
ROW_SIZE_AVG RSA,SPACE_OVERHEAD SOH,SPACE_UNUSED SUN FROM GV$RESULT_CACHE_OBJECTS WHERE INST_ID=&&instNum;
INT ID TYPE BLKCNT CLMCNT RCNT RSM RSA SOH SUN
------- --------- ------- ------- ----- ----- ----- ----- -----
1 1 Dependency 1 0 0 0 0 0 0
1 0 Dependency 1 0 0 0 0 0 0
1 2 Result 7 5 300 27 26 536 35
第 4 步
在本练习的第 2 步所讨论的输出中,我们注意到,此操作利用了共享池动态内存部分的 0.004%。以下查询提供了详细报告:
INST_ID POOL NAME BYTES
------- ---------------------------------------------- ----------
1 shared pool Result Cache: State Objs 2896
1 shared pool Result Cache 194216
1 shared pool Result Cache: Memory Mgr 200
1 shared pool Result Cache: 2088
1 shared pool Result Cache: Cache Mgr 5552
1 shared pool Result Cache: Bloom Fltr 2048
现在,我们了解了实例 1 (SSKY1) 上的结果缓存发生了什么。据观察,此功能的行为与单实例实现中相同。
Oracle RAC 最大的优势之一就是多个用户可从集群中的多个实例查询相同的一组数据。如前所述,如果一个用户从实例 2 (SSKY2)、实例 3 (SSKY3) 或实例 4 (SSKY4) 执行完全相同的查询,根据所检索的数据量,将使用缓存融合通过互连传输数据,或者在 Oracle Database 11g 第 2 版中,将从存储本地检索数据(使用全新的 bypass reader 算法)。同样,进程不仅必须通过互连传输所有数据或从存储载入数据,还需要遍历缓冲区缓存内的所有行,之后才能生成结果集。
纵览这次练习,我们在实例 3 (SSKY3) 上执行查询,观察具体情况。如图 3 所示,在 Oracle RAC 环境中使用结果缓存特性的最大性能收益就是仅在实例之间传输最终结果集,从而大大减少了 CPU 和网络资源占用。
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.01 0.02 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 21 0.00 0.00 0 0 0 300
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 23 0.02 0.03 0 0 0 300
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Parsing user id: 89 (TPCC)
Rows Row Source Operation
------- ---------------------------------------------------
300 RESULT CACHE 8fbjhchhd9zwh7uhn4mv7dhvga (cr=5 pr=0 pw=0 time=299 us)
0 HASH GROUP BY (cr=0 pr=0 pw=0 time=0 us cost=126413 size=4950 card=150)
0 HASH JOIN (cr=0 pr=0 pw=0 time=0 us cost=125703 size=680920944 card=20633968)
0 INDEX FAST FULL SCAN ORDERS_I2 (cr=0 pr=0 pw=0 time=0 us cost=2743 size=22694870 card=2063170)(object id 86234)
0 INDEX FAST FULL SCAN IORDL (cr=0 pr=0 pw=0 time=0 us cost=87415 size=453947296 card=20633968)(object id 86202)
根据从 10046 跟踪事件收集的统计信息,应该注意到,没有本地检索的数据,也不存在对本地实例缓冲区缓存中任意行的遍历。执行计划表明,仅获取最终结果集。这样的结果集是如何获得的?又是从何处获得的?利用缓存融合算法,Oracle 数据库能够过从实例 1 的共享池的结果缓存部分中检索结果集,并通过互连传输数据。这是不是非常巧妙?这种方法切实减少了数据处理,提高了资源利用率。
共享池结果缓存部分的内存结构也与初次执行查询的实例中的内存结构完全相同。这证明了两点:第二个实例无需使用额外的内存或资源,每个 Oracle RAC 实例都在其本地结果缓存内维护自己的一份结果集副本。
R e s u l t C a c h e M e m o r y R e p o r t [Parameters] Block Size = 1K bytes Maximum Cache Size = 251680K bytes (251680 blocks) Maximum Result Size = 12584K bytes (12584 blocks) [Memory] Total Memory = 208144 bytes [0.004% of the Shared Pool] ... Fixed Memory = 13928 bytes [0.000% of the Shared Pool] ....... Memory Mgr = 200 bytes ....... Bloom Fltr = 2K bytes ....... = 3232 bytes ....... Cache Mgr = 5552 bytes ....... State Objs = 2896 bytes ... Dynamic Memory = 194216 bytes [0.004% of the Shared Pool] ....... Overhead = 161448 bytes ........... Hash Table = 64K bytes (4K buckets) ........... Chunk Ptrs = 62920 bytes (7865 slots) ........... Chunk Maps = 31460 bytes ........... Miscellaneous = 1532 bytes ....... Cache Memory = 32K bytes (32 blocks) ........... Unused Memory = 23 blocks ........... Used Memory = 9 blocks ............... Dependencies = 2 blocks (2 count) ............... Results = 7 blocks ................... SQL = 7 blocks (1 count) PL/SQL procedure successfully completed.
在实例 3 上执行的一次查询提供了与实例 1 上的查询完全相同的内存结构;0.004% 的动态内存部分分配给了结果缓存部分,用于存储 9 个数据块。
查询 GV$RESULT_CACHE_OBJECTS 视图,有两个结果缓存部分,一个位于实例 1 上,另一个位于实例 2 上,表明在 Oracle RAC 环境中,Oracle 数据库不维护全局结果缓存部分。而是在实例内本地管理结果缓存。
SQL> SELECT INST_ID INT, ID, TYPE, STATUS, NAME, OBJECT_NO OBJNO,CACHE_ID,INVALIDATIONS INVALS FROM GV$RESULT_CACHE_OBJECTS;
INT ID TYPE STATUS NAME OBJNO CACHE_ID INVALS
--- -- ---------- --------- ---------------------------------- ------ --------------------------- -----
3 1 Dependency Published TPCC.ORDERS 86209 TPCC.ORDERS 0
3 0 Dependency Published TPCC.ORDER_LINE 86201 TPCC.ORDER_LINE 0
3 2 Result Published SELECT /*+ RESULT_CACHE */ OL_W_ID 0 8fbjhchhd9zwh7uhn4mv7dhvga 0
,OL_D_ID,OL_NUMBER,sum(OL_AMOUNT),
sum(OL_QUANTITY) FROM ORDER_LINE O
L, ORDERS ORD WHERE OL.OL_
1 1 Dependency Published TPCC.ORDERS 86209 TPCC.ORDERS 0
1 0 Dependency Published TPCC.ORDER_LINE 86201 TPCC.ORDER_LINE 0
1 2 Result Published SELECT /*+ RESULT_CACHE */ OL_W_ID 0 8fbjhchhd9zwh7uhn4mv7dhvga 0
,OL_D_ID,OL_NUMBER,sum(OL_AMOUNT),
sum(OL_QUANTITY) FROM ORDER_LINE O
L, ORDERS ORD WHERE OL.OL_
6 rows selected.
在上述输出中,有几个因素值得注意:
查询在两个实例上具有相同的 CACHE_ID。
从执行计划(第 4 步)中,我们观察到,实例 3 的结果缓存中的行数与实例 1 相同。
集群有 4 个实例,然而,只有在针对实例的结果缓存已经被利用的情况下,视图才会包含数据,也就是说,实例 2 和实例 4 的结果缓存部分中均无任何条目。然而,当用户在任何一个实例上执行相同的查询时,在实例 3 上观察到的行为将复制到这些实例上。
查询是否会始终返回相同的结果集?当基本对象中的数据发生更改时,将出现怎样的情况?包含结果的结果缓存部分会发生怎样的情况?
这些都是非常好的问题。让我们继续探讨练习,尝试解答部分问题。
当任何基本对象中的数据数据发生更改时,Oracle 数据库将使集群中所有实例上的结果集失效,也就是说,之后再执行相同查询将需要刷新数据处理,以便重新生成结果集,并将结果存储在共享池的结果缓存部分中。
INT ID TYPE STATUS NAME OBJNO CACHE_ID INVALS
--- -- ---------- --------- ---------------------------------- ------ -------------------------- ------
1 1 Dependency Published TPCC.ORDERS 86209 TPCC.ORDERS 0
1 0 Dependency Published TPCC.ORDER_LINE 86201 TPCC.ORDER_LINE 1
1 2 Result Invalid SELECT /*+ RESULT_CACHE */ OL_W_ID 0 8fbjhchhd9zwh7uhn4mv7dhvga 0
,OL_D_ID,OL_NUMBER,sum(OL_AMOUNT),
sum(OL_QUANTITY) FROM ORDER_LINE O
L, ORDERS ORD WHERE OL.OL_
3 1 Dependency Published TPCC.ORDERS 86209 TPCC.ORDERS 0
3 0 Dependency Published TPCC.ORDER_LINE 86201 TPCC.ORDER_LINE 1
3 2 Result Invalid SELECT /*+ RESULT_CACHE */ OL_W_ID 0 8fbjhchhd9zwh7uhn4mv7dhvga 0
,OL_D_ID,OL_NUMBER,sum(OL_AMOUNT),
sum(OL_QUANTITY) FROM ORDER_LINE O
L, ORDERS ORD WHERE OL.OL_
如果再次执行查询从数据库中检索新结果集,则将在结果缓存部分中添加一个新行 (ID=9)。Oracle 数据库保留无效的结果集,直至实例回弹,结果缓存将被刷新,结果缓存中的数据将过期并从缓冲区中删除。
INT ID TYPE STATUS NAME OBJNO CACHE_ID INVALS
--- -- ---------- --------- ---------------------------------- ------ ------------------------- ------
1 1 Dependency Published TPCC.ORDERS 86209 TPCC.ORDERS 0
1 0 Dependency Published TPCC.ORDER_LINE 86201 TPCC.ORDER_LINE 1
1 9 Result Published SELECT /*+ RESULT_CACHE */ OL_W_ID 0 8fbjhchhd9zwh7uhn4mv7dhvga 0
,OL_D_ID,OL_NUMBER,sum(OL_AMOUNT),
sum(OL_QUANTITY) FROM ORDER_LINE O
L, ORDERS ORD WHERE OL.OL_
1 2 Result Invalid SELECT /*+ RESULT_CACHE */ OL_W_ID 0 8fbjhchhd9zwh7uhn4mv7dhvga 0
,OL_D_ID,OL_NUMBER,sum(OL_AMOUNT),
sum(OL_QUANTITY) FROM ORDER_LINE O
L, ORDERS ORD WHERE OL.OL_
3 1 Dependency Published TPCC.ORDERS 86209 TPCC.ORDERS 0
3 0 Dependency Published TPCC.ORDER_LINE 86201 TPCC.ORDER_LINE 1
3 2 Result Invalid SELECT /*+ RESULT_CACHE */ OL_W_ID 0 8fbjhchhd9zwh7uhn4mv7dhvga 0
,OL_D_ID,OL_NUMBER,sum(OL_AMOUNT),
sum(OL_QUANTITY) FROM ORDER_LINE O
L, ORDERS ORD WHERE OL.OL_
在上面的输出中,如果从 ORDER_LINE 表中删除几行,结果行将标记为 Invalid,GV$RESULT_CACHE_OBJECTS 视图的 INVALIDATIONS (INVALS) 计数器将增加。如果稍后对 ORDER_LINE 表执行了另一项操作,无论是添加新行还是再删除几行,计数器都将再次增加。这表明结果缓存中的对象失效了多少次。
它保持无效的时间有多长?与 Oracle 数据库实例中的其他缓存区域一样,结果缓存部分的内存管理也是相同的;无效结果将移动到脏数据列表中,并在新数据载入缓存部分时从缓存部分中刷新出去。
结果缓存的主要局限性在于结果仅存储在缓存中。这意味着,如果实例出错或因维护而关闭,数据将被清除。如果结果集必须永久存储在数据库中,则应使用物化视图等选项。
使用这种特性时,某些类型的操作不受支持。例如,查询不能包括或使用 CURRENT_DATE、CURRENT_TIMESTAMP、LOCAL_TIMESTAMP、SYS_CONTEXT、SYS_GUID、SYS_TIMESTEMP、USERENV 等 SQL 函数。如果使用了这些函数,将发生以下类型的错误:
ERROR at line 1:
ORA-00904: "SYS_TIMESTAMP": invalid identifier
在 SYS 或 SYSTEM 模式中,来自对象/表的结果或数据集不能使用此特性进行缓存。来自数据库序列的 CURRVAL 和 NEXTVAL 伪列的数据不能使用此特性进行缓存。
Oracle Database 11g 第 1 版中引入的结果缓存特性为结果集不常更改的操作提供了显著的收益。该特性可帮助在内存中存储最终结果集,提供对数据集的高速访问。
当数据库中的数据不会因频繁变更而导致数据结果集失效时,这项新特性是非常有帮助的,例如在数据库仓库或报告数据库环境中。
