ocp考试资料群:569933648 验证码:ocp OCP 12c 19c考试题库解析与资料群:钉钉群号:35277291
全部博文(488)
分类: Mysql/postgreSQL
2023-09-08 14:44:11

PostgreSQL从小白到专家,是从入门逐渐能力提升的一个系列教程,内容包括对PG基础的认知、包括安装使用、包括角色权限、包括维护管理、、等内容,希望对热爱PG、学习PG的同学们有帮助,欢迎持续关注CUUG PG技术大讲堂。
第28讲:索引内部结构
内容1 : PG数据库众多开放特性概述
内容2 : 索引结构与生长
内容3 : Autovacuum自动维护索引
内容4:btree、hash索引应用场景
PostgreSQL 开放特性概述
开放的数据类型接口,使得PG支持超级丰富的数据类型,除了传统数据库支持的类型,还支持GIS,JSON,RANGE,IP,ISBN,图像特征值,化学,DNA等等扩展的类型,用户还可以根据实际业务扩展更多的类型。
开放的操作符接口,使得PG不仅仅支持常见的类型操作符,还支持扩展的操作符,例如 距离符,逻辑并、交、差符号,图像相似符号,几何计算符号等等扩展的符号,用户还可以根据实际业务扩展更多的操作符。
开放的外部数据源接口,使得PG支持丰富的外部数据源,例如可以通过FDW读写MySQL, redis, mongo, oracle, sqlserver, hive, www, hbase, ldap, 等等只要你能想到的数据源都可以通过FDW接口读写。
开放的语言接口,使得PG支持几乎地球上所有的编程语言作为数据库的函数、存储过程语言,例如plpython , plperl , pljava , plR , plCUDA , plshell等等。用户可以通过language handler扩展PG的语言支持。
开放的索引接口,使得PG支持非常丰富的索引方法,例如btree , hash , gin , gist , sp-gist , brin , bloom , rum , zombodb , bitmap (greenplum extend),用户可以根据不同的数据类型,以及查询的场景,选择不同的索引。
PG内部还支持BitmapAnd, BitmapOr的优化方法,可以合并多个索引的扫描操作,从而提升多个索引数据访问的效率。
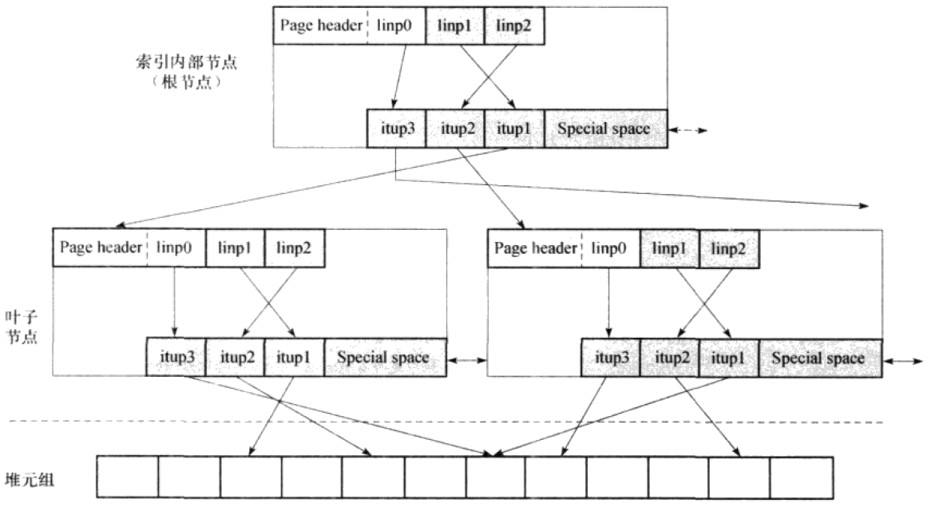
索引结构
· PostgreSQL索引结构
meta page和root page是一定有的,meta page需要一个页来存储,表示指向root page的page id。
随着记录数的增加,一个root page可能存不下所有的heap item,就会有leaf page,甚至branch page,甚至多层的branch page。
一共有几层branch 和 leaf,可以用btree page元数据的 level 来表示。
Btree索引
· Btree索引
索引工具介绍
· 如何访问索引结构
1、create extension pageinspect
2、查看meta块
select * from bt_metap('tab1_pkey');
3、查看root page的stats
select * from bt_page_stats('tab1_pkey',1);
4、查看root(leaf)页里面的内容:
select * from bt_page_items('tab1_pkey',1);
5、根据ctid来访问表:
select * from tab1 where ctid='(0,1)';
Btree索引
· 一层结构
有1层(0)结构,包括meta page, root page
1、环境准备:
postgres=# create extension pageinspect;
postgres=# create table tab1(id int primary key, info text);
CREATE TABLE
postgres=# insert into tab1 select generate_series(1,100), md5(random()::text);
INSERT 0 100
postgres=# vacuum analyze tab1;
VACUUM
2、查看meta块
indx=# select * from bt_metap('tab1_pkey');
magic | version | root | level | fastroot | fastlevel | oldest_xact | last_cleanup_num_tuples
--------+---------+------+-------+----------+-----------+-------------+-------------------------
340322 | 4 | 1 | 0 | 1 | 0 | 0 | 100
此时level 0,root块为1。
3、根据root page id = 1,查看root page的stats
ndx=# select * from bt_page_stats('tab1_pkey',1);
blkno | type | live_items | dead_items | avg_item_size | page_size | free_size | btpo_prev | btpo_next | btpo | btpo_flags
-------+------+------------+------------+---------------+-----------+-----------+-----------+-----------+------+------------
1 | l | 100 | 0 | 16 | 8192 | 6148 | 0 | 0 | 0 | 3
(1 row)
此时:btpo=0,说明处于第0层。
btpo_flags=3,说明它既是leaf又是root页。即:root_page(2)+leaf_page(1)=3
注:
meta page
root page :表示为btpo_flags=2
branch page :表示为btpo_flags=0
leaf page :表示为btpo_flags=1
4、查看root(leaf)页里面的内容:
itemoffset | ctid | itemlen | nulls | vars | data
------------+---------+---------+-------+------+-------------------------
1 | (0,1) | 16 | f | f | 01 00 00 00 00 00 00 00
2 | (0,2) | 16 | f | f | 02 00 00 00 00 00 00 00
3 | (0,3) | 16 | f | f | 03 00 00 00 00 00 00 00
4 | (0,4) | 16 | f | f | 04 00 00 00 00 00 00 00
5 | (0,5) | 16 | f | f | 05 00 00 00 00 00 00 00
此时ctid就是指向表的行id,类似于oracle的rowid,PG中为tid。
data就是索引列的值,16进制。
5、根据ctid来访问表:
indx=# select * from tab1 where ctid='(0,1)';
id | info
----+----------------------------------
1 | 7c3402d464509541c0d788e1afe2c90f
6、查看表的数据来验证:
indx=# select * from tab1 limit 2;
id | info
----+----------------------------------
1 | 7c3402d464509541c0d788e1afe2c90f
2 | f19de3e3255b9f1f676584fd50ad73d9
· 二层结构
有2层(0,1)结构,包括meta page, root page, leaf page
准备工作:
继续往表中插入数据,让索引生长。
insert into tab1 select generate_series(101,10000), md5(random()::text) ;
1、查看meta数据:
indx=# select * from bt_metap('tab1_pkey');
magic | version | root | level | fastroot | fastlevel | oldest_xact | last_cleanup_num_tuples
--------+---------+------+-------+----------+-----------+-------------+-------------------------
340322 | 4 | 3 | 1 | 3 | 1 | 0 | -1
root块在第3块。
2、根据root page id 查看root page的stats:
indx=# select * from bt_page_stats('tab1_pkey',3);
blkno | type | live_items | dead_items | avg_item_size | page_size | free_size | btpo_prev | btpo_next | btpo | btpo_flags
-------+------+------------+------------+---------------+-----------+-----------+-----------+-----------+------+------------
3 | r | 28 | 0 | 15 | 8192 | 7596 | 0 | 0 | 1 | 2
3、查看root page存储的 leaf page items (指向leaf page):
indx=# select * from bt_page_items('tab1_pkey',3);
itemoffset | ctid | itemlen | nulls | vars | data
------------+--------+---------+-------+------+-------------------------
1 | (1,0) | 8 | f | f |
2 | (2,1) | 16 | f | f | 6f 01 00 00 00 00 00 00
3 | (4,1) | 16 | f | f | dd 02 00 00 00 00 00 00
一共28个叶块。data存储的是这个leaf page存储的{BANNED}最佳小值。
4、查看{BANNED}中国第一个叶块统计:
indx=# select * from bt_page_stats('tab1_pkey',1);
blkno | type | live_items | dead_items | avg_item_size | page_size | free_size | btpo_prev | btpo_next | btpo | btpo_flags
-------+------+------------+------------+---------------+-----------+-----------+-----------+-----------+------+------------
1 | l | 367 | 0 | 16 | 8192 | 808 | 0 | 2 | 0 | 1
btpo=0,说明是{BANNED}最佳底层,btpo_flags=1,即叶块。
5、查看其它叶块统计,当查询到第30块时,显示超出块的范围。
indx=# select * from bt_page_stats('tab1_pkey',29);
blkno | type | live_items | dead_items | avg_item_size | page_size | free_size | btpo_prev | btpo_next | btpo | btpo_flags
-------+------+------------+------------+---------------+-----------+-----------+-----------+-----------+------+------------
29 | l | 118 | 0 | 16 | 8192 | 5788 | 28 | 0 | 0 | 1
6、查看{BANNED}中国第一个叶块的内容:
indx=# select * from bt_page_items('tab1_pkey',1);
itemoffset | ctid | itemlen | nulls | vars | data
------------+---------+---------+-------+------+-------------------------
1 | (3,1) | 16 | f | f | 6f 01 00 00 00 00 00 00
2 | (0,1) | 16 | f | f | 01 00 00 00 00 00 00 00
3 | (0,2) | 16 | f | f | 02 00 00 00 00 00 00 00
7、根据CTID查看表中的行数据:
select * from t_btree where ctid='(0,1)';
id | info
----+----------------------------------
1 | 9892a864978b60abb3a30e9c23298967
· 三层结构
记录数超过1层结构的索引所能够存储的记录数时,会分裂为2层结构,除了meta page和root page,还可能包含1层branch page以及1层leaf page。
1、继续往tab1表插入新数据,导致btree增长一层:
insert into tab1 select generate_series(10001,100000), md5(random()::text) ;
postgres=# vacuum analyze tab1;
2、查看meta page,可以看到root page id = 412, 索引的level=2,即包括1级 branch 和 1级 leaf。
postgres=# select * from bt_metap('tab1_pkey');
magic | version | root | level | fastroot | fastlevel
--------+---------+------+-------+----------+-----------
340322 | 2 | 412 | 2 | 412 | 2
3、根据root page id 查看root page的stats
indx=# select * from bt_page_stats('tab1_pkey', 412);
blkno | type | live_items | dead_items | avg_item_size | page_size | free_size | btpo_prev | btpo_next | btpo | btpo_flags
-------+------+------------+------------+---------------+-----------+-----------+-----------+-----------+------+------------
412 | r | 11 | 0 | 15 | 8192 | 7936 | 0 | 0 | 2 | 2
btpo = 2 当前在第二层,另外还表示下层是1。
btpo_flags = 2 说明是root page
4、查看root page存储的 branch page items (指向branch page)
postgres=# select * from bt_page_items('tab1_pkey', 412);
itemoffset | ctid | itemlen | nulls | vars | data
------------+----------+---------+-------+------+-------------------------
1 | (3,1) | 8 | f | f |
2 | (2577,1) | 16 | f | f | e1 78 0b 00 00 00 00 00
3 | (1210,1) | 16 | f | f | ec 3a 18 00 00 00 00 00
4 | (2316,1) | 16 | f | f | de 09 25 00 00 00 00 00
5、根据branch page id查看stats
indx=# select * from bt_page_stats('tab1_pkey', 3);
blkno | type | live_items | dead_items | avg_item_size | page_size | free_size | btpo_prev | btpo_next | btpo | btpo_flags
-------+------+------------+------------+---------------+-----------+-----------+-----------+-----------+------+------------
3 | i | 316 | 0 | 15 | 8192 | 1836 | 0 | 2247 | 1 | 0
6、查看branch page存储的 leaf page ctid (指向leaf page)
indx=# indx=# select * from bt_page_items('tab1_pkey', 3);
itemoffset | ctid | itemlen | nulls | vars | data
------------+----------+---------+-------+------+-------------------------
1 | (1748,1) | 16 | f | f | 32 56 0c 00 00 00 00 00
2 | (1,0) | 8 | f | f |
3 | (3519,1) | 16 | f | f | 47 08 00 00 00 00 00 00
只要不是{BANNED}最佳右边的页,{BANNED}中国第一条都代表右页的起始item。
第二条才是当前页的起始ctid
注意所有branch page的起始item对应的data都是空的。
也就是说它不存储当前branch page包含的所有leaf pages的索引字段内容的{BANNED}最佳小值。
7、根据ctid 查看leaf page的统计:
indx=# select * from bt_page_stats('tab1_pkey', 1);
blkno | type | live_items | dead_items | avg_item_size | page_size | free_size | btpo_prev | btpo_next | btpo | btpo_flags
-------+------+------------+------------+---------------+-----------+-----------+-----------+-----------+------+------------
1 | l | 234 | 0 | 16 | 8192 | 3468 | 0 | 2952 | 0 | 1
btpo = 0 当前在第0层,即{BANNED}最佳底层,这里存储的是heap ctid
btpo_flags = 1 说明是leaf page
第0层叶块,第1层枝块,第2层root块。
8、查看leaf页的指向表的ctid:
indx=# select * from bt_page_items('tab1_pkey', 1);
itemoffset | ctid | itemlen | nulls | vars | data
------------+------------+---------+-------+------+-------------------------
1 | (1509,1) | 16 | f | f | 25 09 00 00 00 00 00 00
2 | (4072,81) | 16 | f | f | 05 00 00 00 00 00 00 00
3 | (1035,12) | 16 | f | f | 07 00 00 00 00 00 00 00
9、通过ctid查看表的数据:
indx=# select * from tab2 where ctid='(1748,1)';
id | info
---------+----------------------------------
2222345 | aa2555d335e54892040bf20843ee71af
索引案例应用
利用查看索引数据块的变化,去证明Autovacuum是否会维护索引。
1、环境搭建
create table tbl_test (id int, info text, c_time timestamp);
insert into tbl_test select generate_series(1,100000),md5(random()::text),clock_timestamp();
create index tbl_test_id_ind on tbl_test (id);
2、索引信息
--查看索引元数据
select * from bt_metap('tbl_test_id_ind');
--查看索引root根统计
select * from bt_page_stats('tbl_test_id_ind',3);
--查看索引叶块内容(此时没有发生数据更新)
indx=# select * from bt_page_items('tbl_test_id_ind',1);
itemoffset | ctid | itemlen | nulls | vars | data
------------+---------+---------+-------+------+-------------------------
1 | (3,1) | 16 | f | f | 6f 01 00 00 00 00 00 00
2 | (0,1) | 16 | f | f | 01 00 00 00 00 00 00 00
3 | (0,2) | 16 | f | f | 02 00 00 00 00 00 00 00
4 | (0,3) | 16 | f | f | 03 00 00 00 00 00 00 00
3、更新表数据,导致autovacuum触发
update tbl_test set info=md5(random()::text) where id < 20060;
4、查看索引叶块的内容变化(autovacuum前)
indx=# select * from bt_page_items('tbl_test_id_ind',1);
itemoffset | ctid | itemlen | nulls | vars | data
------------+-----------+---------+-------+------+-------------------------
1 | (1,1) | 16 | f | f | a3 00 00 00 00 00 00 00
2 | (0,1) | 16 | f | f | 01 00 00 00 00 00 00 00
3 | (934,63) | 16 | f | f | 01 00 00 00 00 00 00 00
4 | (0,2) | 16 | f | f | 02 00 00 00 00 00 00 00
5 | (934,64) | 16 | f | f | 02 00 00 00 00 00 00 00
6 | (0,3) | 16 | f | f | 03 00 00 00 00 00 00 00
7 | (934,65) | 16 | f | f | 03 00 00 00 00 00 00 00
注意红色的为被更新的索引行。
5、查看索引叶块的内容变化(autovacuum后)
indx=# select * from bt_page_items('tbl_test_id_ind',1);
itemoffset | ctid | itemlen | nulls | vars | data
------------+-----------+---------+-------+------+-------------------------
1 | (1,1) | 16 | f | f | a3 00 00 00 00 00 00 00
2 | (934,63) | 16 | f | f | 01 00 00 00 00 00 00 00
3 | (934,64) | 16 | f | f | 02 00 00 00 00 00 00 00
4 | (934,65) | 16 | f | f | 03 00 00 00 00 00 00 00
5 | (934,66) | 16 | f | f | 04 00 00 00 00 00 00 00
观察后发现索引块的信息更新了,原来的索引行被删除。
说明autovacuum会自动维护索引信息。
索引维护
· 索引维护
testdb=# reindex INDEX id_data_ind2;
Reindex后索引的relfilenode就发生变化:
testdb=# select relname,oid,relfilenode from pg_class
where relname='id_data_ind2';
relname | oid | relfilenode
--------------+-------+-------------
id_data_ind2 | 65538 | 65546
Btree索引应用场景
· PostgreSQL B-Tree是一种变种(高并发B树管理算法)
应用场景
b-tree适合所有的数据类型,支持排序,支持大于、小于、等于、大于或等于、小于或等于的搜索。
索引与递归查询结合,还能实现快速的稀疏检索。
示例
postgres=# create table t_btree(id int, info text);
CREATE TABLE
postgres=# insert into t_btree select generate_series(1,10000), md5(random()::text) ;
INSERT 0 10000
postgres=# create index idx_t_btree_1 on t_btree using btree (id);
CREATE INDEX
postgres=# explain (analyze,verbose,timing,costs,buffers) select * from t_btree where id=1;
· Hash索引结构
哈希索引项只存储每个索引项的哈希代码,而不是实际的数据值
应用场景
hash索引存储的是被索引字段VALUE的哈希值,只支持等值查询。
hash索引特别适用于字段VALUE非常长(不适合b-tree索引,因为b-tree一个PAGE至少要存储3个索引行,所以不支持特别长的VALUE)的场景,例如很长的字符串,并且用户只需要等值搜索,建议使用hash index。
示例
postgres=# create table t_hash (id int, info text);
CREATE TABLE
postgres=# insert into t_hash select generate_series(1,100), repeat(md5(random()::text),10000);
INSERT 0 100
-- 使用b-tree索引会报错,因为长度超过了1/3的索引页大小
postgres=# create index idx_t_hash_1 on t_hash using btree (info);
ERROR: index row size 3720 exceeds maximum 2712 for index "idx_t_hash_1"
HINT: Values larger than 1/3 of a buffer page cannot be indexed.
Consider a function index of an MD5 hash of the value, or use full text indexing.
postgres=# create index idx_t_hash_1 on t_hash using hash (info);
CREATE INDEX
postgres=# explain (analyze,verbose,timing,costs,buffers) select * from t_hash where info in (select info from t_hash limit 1);
