linux工程师,RHCE
分类: 系统运维
2021-07-22 16:53:41
在深度学习领域,算力从来都是我们关心的一个重点,也是影响人工智能算法落地的一个关键因素。
基于种群的多智能体深度强化学习(PB-MARL)方法在星际争霸、王者荣耀等游戏AI上已经得到成功验证,MALib 则是首个专门面向 PB-MARL 的开源大规模并行训练框架。MALib 支持丰富的种群训练方式(例如,self-play, PSRO, league training),并且实现和优化了常见多智能体深度强化学习算法,为研究人员降低并行化工作量的同时,大幅提升了训练效率。此外,MALib 基于 Ray 的底层分布式框架,实现了全新的中心化任务分发模型,相较于常见的多智能体强化学习训练框架(RLlib,PyMARL,OpenSpiel),相同硬件条件下吞吐量和训练速度有着数倍的提升。现阶段,MALib 已对接常见多智能体环境(星际争霸、谷歌足球、棋牌类、多人 Atari 等),后续将进一步提供对自动驾驶、智能电网等场景的支持。
项目主页:。

在深度学习领域,算力从来都是我们关心的一个重点,也是影响人工智能算法落地的一个关键因素。在很多应用场景里面,足够的算力支持可以显著加快算法从提出、训练到落地的效率,像是 OpenAI Five 的亿级参数量的使用,其每天的 GPU 计算用量在 770±50~820±50 PFlops/s。而在深度强化学习领域,随着应用场景从单智能体扩展到多智能体,算法的求解复杂度也呈现指数级增长,这也对算力要求提出了新的挑战,要求更多的计算资源能够被调用。特别是当所要处理的问题规模,涉及的智能体数量较多时,单机训练算法的可行度显著下降。
多智能体强化学习要解决群体智能相关的问题,其研究往往涉及群体内智能体之间的协作与对抗。目前已有众多现实任务应用涉及大规模智能体和复杂多样化交互,例如人群模拟、自动驾驶以及军事场景中的无人机集群控制:

人群模拟()。

自动驾驶()。
无人机集群()。
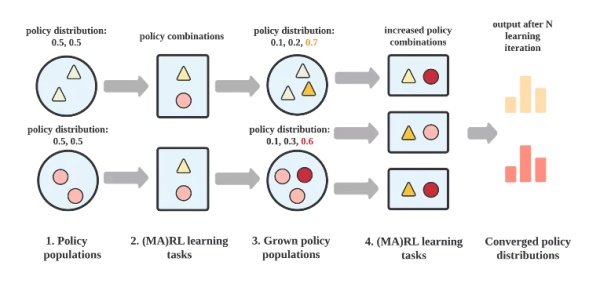
在算法方面,解决此类群体问题的一个重要的途径是基于群体的多智能体强化学习方法,也是 MALib 目前阶段的重点瞄准方向。基于群体的多智能体强化学习(Population-based MARL, PB-MARL)涉及多个策略集合交互问题,下图展示了通常意义上基于群体的多智能体强化学习算法的主要流程。PB-MARL 算法是结合了深度强化学习和动态种群选择方法(例如,博弈论,进化策略)以自动拓展策略集。PB-MARL 能够以此不断产生新的智能,因而在一些复杂任务上都取得了不错的效果,如实时决策游戏 Dota2 、StrarCraftII,以及纸牌任务 Leduc Poker。但在实际问题中,目前的多智能体强化学习算法与应用尚有差距,一个亟待解决的问题便是算法在大规模场景下的训练效率。由于种群算法内在耦合了多智能体算法,致使其训练过程对数据的需求量极大,因而也需要一个灵活、可扩展的训练框架来保证其有效性。
如何提高算法训练效率?对于依赖深度学习技术的很多领域,在面临任务规模变大,模型参数变多的情况下,都需要引入额外的技术来提高训练效率。分布式计算是一个最直接考虑的方法,通过多进程或者多机的方式,提高算法对计算资源的使用效率从而提升算法训练效率。而分布式技术在深度强化学习领域的应用,也催生了分布式深度强化学习这个领域的产生,其研究的重点包括计算框架的设计,以及大规模分布式强化学习算法的开发。
近年来,为了更好地进行大规模深度强化学习算法的训练,研究人员发展了更加专用的训练框架,通过在算法接口和系统设计上进行抽象,来支持更为复杂的实时数据采样、模型训练和推理需求。然而,分布式强化学习技术的发展似乎还未触及群体智能这一问题。实际上,现有分布式强化学习框架对于一般多智能体强化学习算法的分布式计算支持是完全不够的,像 RLlib、Sample-Factory、SEED RL 这样的典型分布式强化学习框架,在设计模式上都是将多智能体任务当作单智能体任务来处理,而忽略了多智能体算法之间的异构性。对于其他强调智能体交互的学习范式,如中心化训练(centralized training)、基于网络的分布式算法以及带有通信功能的协作性算法都没有进行显式支持,缺乏对应的统一接口来简化算法实现和训练流程。因此,研究人员想要进行更多类型多智能体强化学习算法的分布式训练探索时,往往需要进行大量额外的编码工作。而对于多智能体强化学习算法框架方面的发展,现有的工作更多聚焦在算法实现,并不太注重算法在大规模场景下的扩展性,或者更多的是专为某些场景设计的算法库,像 PyMARL、SMARTS 这样的框架,其作用更偏向于服务专门领域内的 benchmark,在算法类型上,大部分框架也做得并不全面。因此对于多智能体强化学习算法框架支持这一块,也一直是缺乏一套比较全面的框架来打通算法实现、训练和部署测试这一套流程。
我们认为以上两个发展现状的主要原因至少会有两点:(1)一个是因为多智能体算法本身在结构上具有的异构性较高,导致算法在接口实现的一致性和复用性上不是太高;(2)另一方面也是因为多智能体分布式算法依然处于早期探索阶段。此外,在分布式部署方面,现有分布式强化学习框架对 independent learning 算法的支持更友好,也更自然和直接。就像通常分布式技术在机器学习领域的应用一样,要解决目前分布式技术在大规模多智能体强化学习领域的更深层次的应用,算法和框架都必不可少,两者相辅相成。
在算法方面,一个重要的途径是基于群体的多智能体强化学习方法,也是 MALib 目前阶段所重点瞄准的方向。基于群体的多智能体强化学习(Population-based MARL, PB-MARL)涉及到多个策略集合交互问题,下图展示了通常意义上基于群体的多智能体强化学习算法的主要流程。PB-MARL 算法特点是结合了深度强化学习和动态种群选择方法(例如,博弈论,进化策略)来进行自动策略集扩展。通过这种方式,PB-MARL 能够不断产生新的智能,并且在解决一些复杂任务上都取得了不错的效果,如实时决策游戏 Dota2 、StrarCraftII,以及纸牌任务 Leduc Poker。
然而,也正是由于种群算法内在耦合了多智能体算法,导致这一类算法在训练过程对数据的需求极大,因此也需要一个灵活的、可扩展的训练框架来保证其有效性。

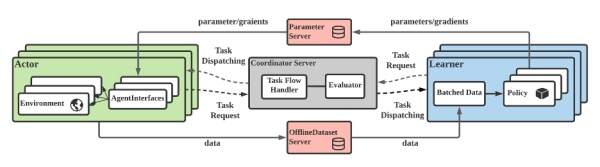
MALib框架图
为了应对这些需求,我们提出了 MALib,从三个方面提出了针对大规模群体多智能体强化学习算法的解决方案:(1)中心化任务调度:自动递进式生成训练任务,作业进程的半主动执行能够提高训练任务的并行度;(2)Actor-Evaluator-Learner 模型:解耦数据流,以满足多节点灵活的数据存储和分发;(3)从训练层面对多智能体强化学习进行抽象:尝试提高多智能体算法在不同训练模式之间的复用率,比如 DDPG 或者 DQN 可以很方便地嫁接到中心化训练模式中。

中心化任务调度模型 (c) 与以往分布式强化学习框架调度模型的对比:(a)完全分布式;(b)层级式
具体而言,MALib 的框架特点如下:
我们和一些现有的分布式强化学习框架进行了对比,以 MADDPG 为例,下图展示的是在 multi-agent particle environments 上使用不同并行程度训练 simple-spread 任务的学习曲线。
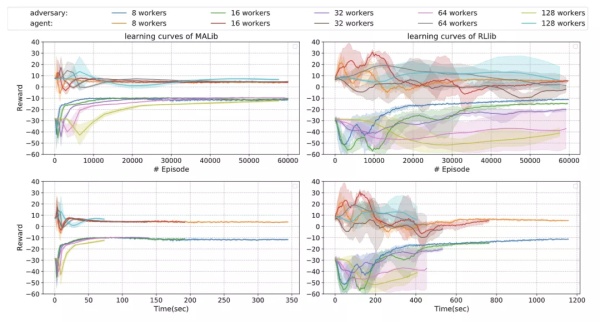
与 RLlib 对比训练 MADDPG 的效果。
对照框架是 RLlib。随着 worker 的数量增多,RLlib 的训练越来越不稳定,而 MALib 的效果一直表现稳定。包括更复杂的环境,比如 StarCraftII 的一些实验,我们对比 PyMARL 的实现,比较 QMIX 算法训练到胜率达到 80% 所花费的时间,MALib 有显著的效率提升(worker 数量都是设置成 32)。
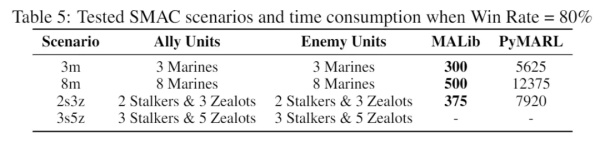
与 PyMARL 在星际任务上的效率对比。
另一方面,我们比较关注的是训练过程的采样效率。我们也对比了与其他分布式强化学习框架的吞吐量对比,在多智体版本的 Atari 游戏上,MALib 在吞吐量和扩展性上都表现了不错的性能。
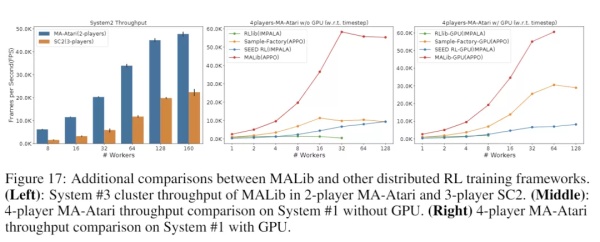
在星际及多智能体 Atari 任务上不同框架的吞吐量对比。
目前,我们的项目已经开源在 GitHub 上(),更多的功能正在积极开发中,欢迎使用并向我们提出宝贵的改进意见!同时如果有兴趣参与项目开发,欢迎联系我们!联系方式:ying.wen@sjtu.edu.cn。
本项目由上海交通大学与伦敦大学学院(UCL)联合的多智能体强化学习研究团队开发。MALib 项目主要由上海交通大学温颖助理教授指导下进行开发,核心开发成员包括上海交通大学三年级博士生周铭,ACM 班大四本科生万梓煜,一年级博士生王翰竟,访问学者温睦宁,ACM 班大三本科生吴润哲,并得到上海交通大学张伟楠副教授和伦敦大学学院的杨耀东博士、汪军教授的联合指导。
团队长期致力于从理论算法、系统与应用三个层面入手,针对开放、真实、动态的多智能场景下的智能决策进行研究。理论团队核心成员在人工智能和机器学习顶会发表多智能体强化学习相关论文共计五十余篇,并获得过 CoRL 2020 最佳系统论文、AAMAS 2021 Blue Sky Track 最佳论文奖。系统方面,除了面向多智能体强化学习种群训练的系统 MALib,本团队研发 SMARTS、CityFlow、MAgent 等大规模智能体强化学习仿真引擎,累计在 Github 上获得了超过 2000 加星。此外,团队在游戏、自动驾驶、搜索与推荐等场景下具有强化学习技术的真实应用落地的经验。《linux就该这么学》不错的linux自学书籍
