分类: 大数据
2019-05-24 15:57:16
Hive是什么:
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
Hive 没有专门的数据格式。 Hive 可以很好的工作在 Thrift 之上,控制分隔符,也允许用户指定数据格式。
Hive架构图:
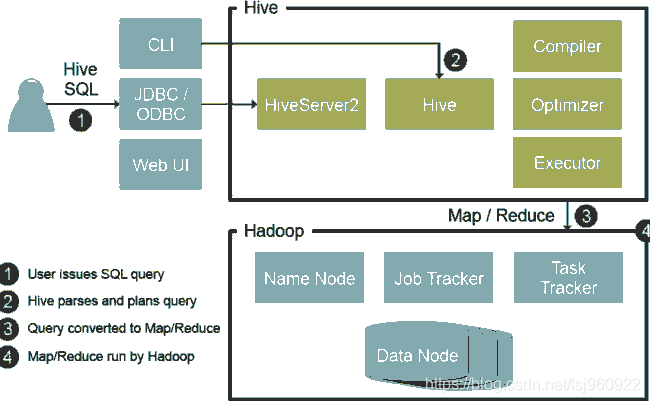
![]()
直接使用hadoop所面临的问题:
为什么要使用Hive:
如何快速掌握Hive:
(课程可以帮助你如何部署以及管理hive适合有一定大数据基础的学员学习)

![]()
更多精品技术课程:
阿里云大学官网()
