分类: 云计算
2018-06-06 06:51:57
前面我们介绍了 Kubernetes 的两种监控方案 Weave Scope 和 Heapster,它们主要的监控对象是 Node 和 Pod。这些数据对 Kubernetes 运维人员是必须的,但还不够。我们通常还希望监控集群本身的运行状态,比如 Kubernetes 的 API Server、Scheduler、Controller Manager 等管理组件是否正常工作,负荷是否过大等?
本节我们将学习监控方案 Prometheus Operator,它能回答上面这些问题。
Prometheus Operator 是 CoreOS 开发的基于 Prometheus 的 Kubernetes 监控方案,也可能是目前功能最全面的开源方案。我们先通过截图了解一下它能干什么。
Prometheus Operator 通过 Grafana 展示监控数据,预定义了一系列的 Dashboard:
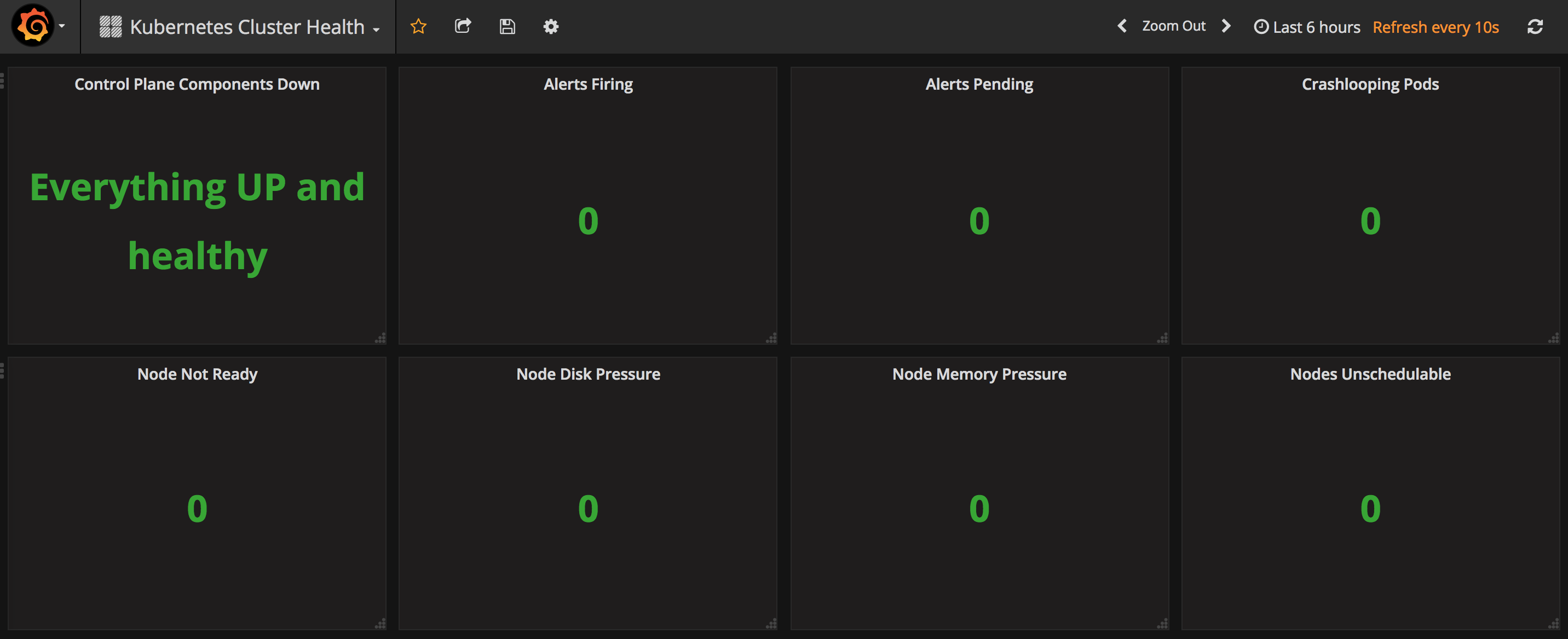
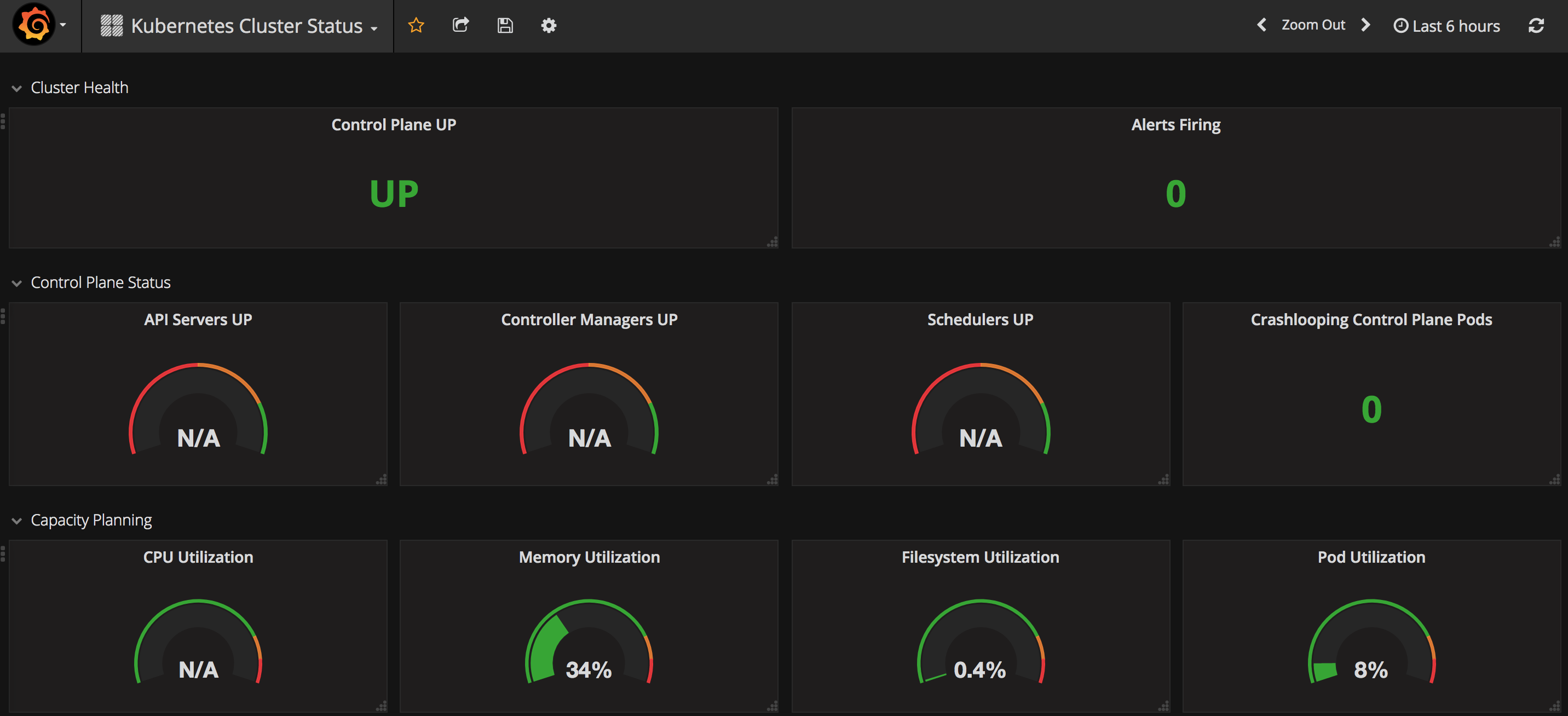
可以监控 Kubernetes 集群的整体健康状态:
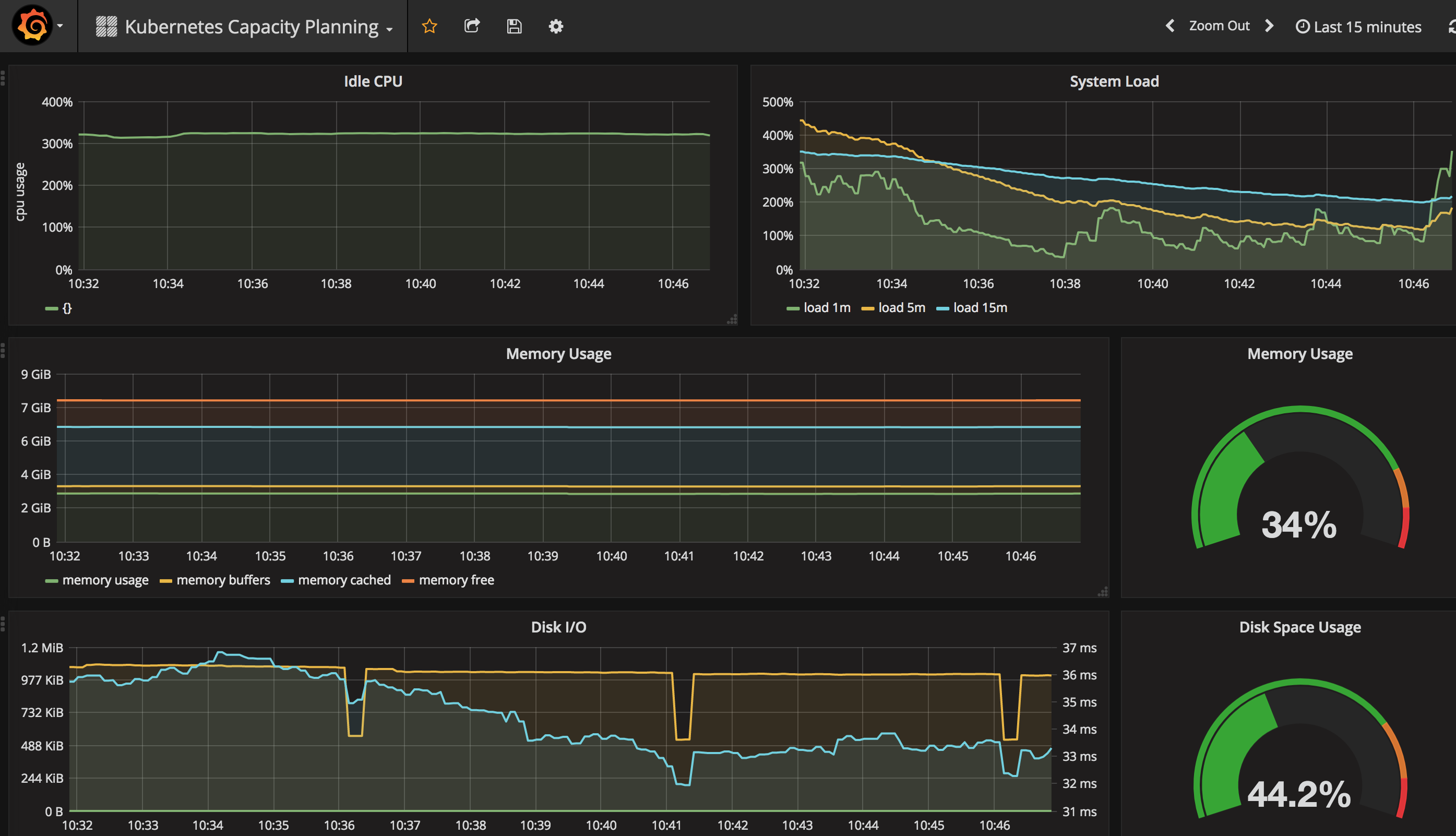
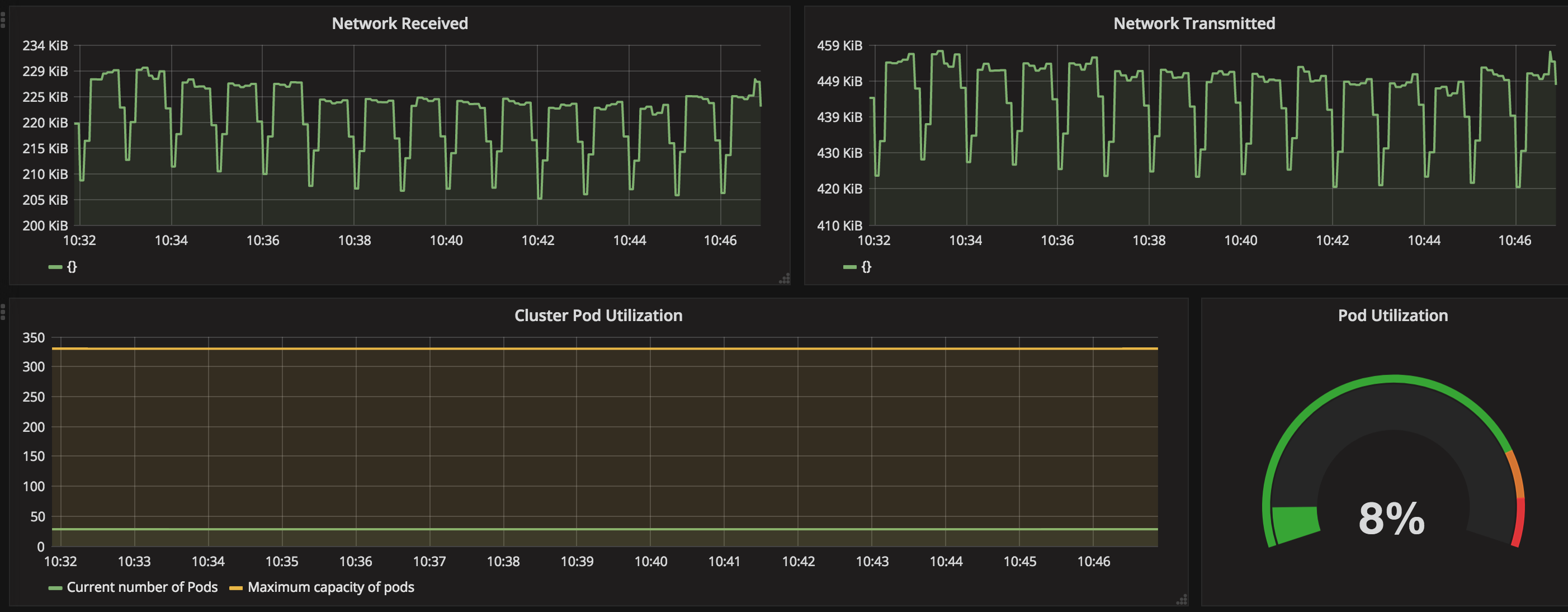
整个集群的资源使用情况:
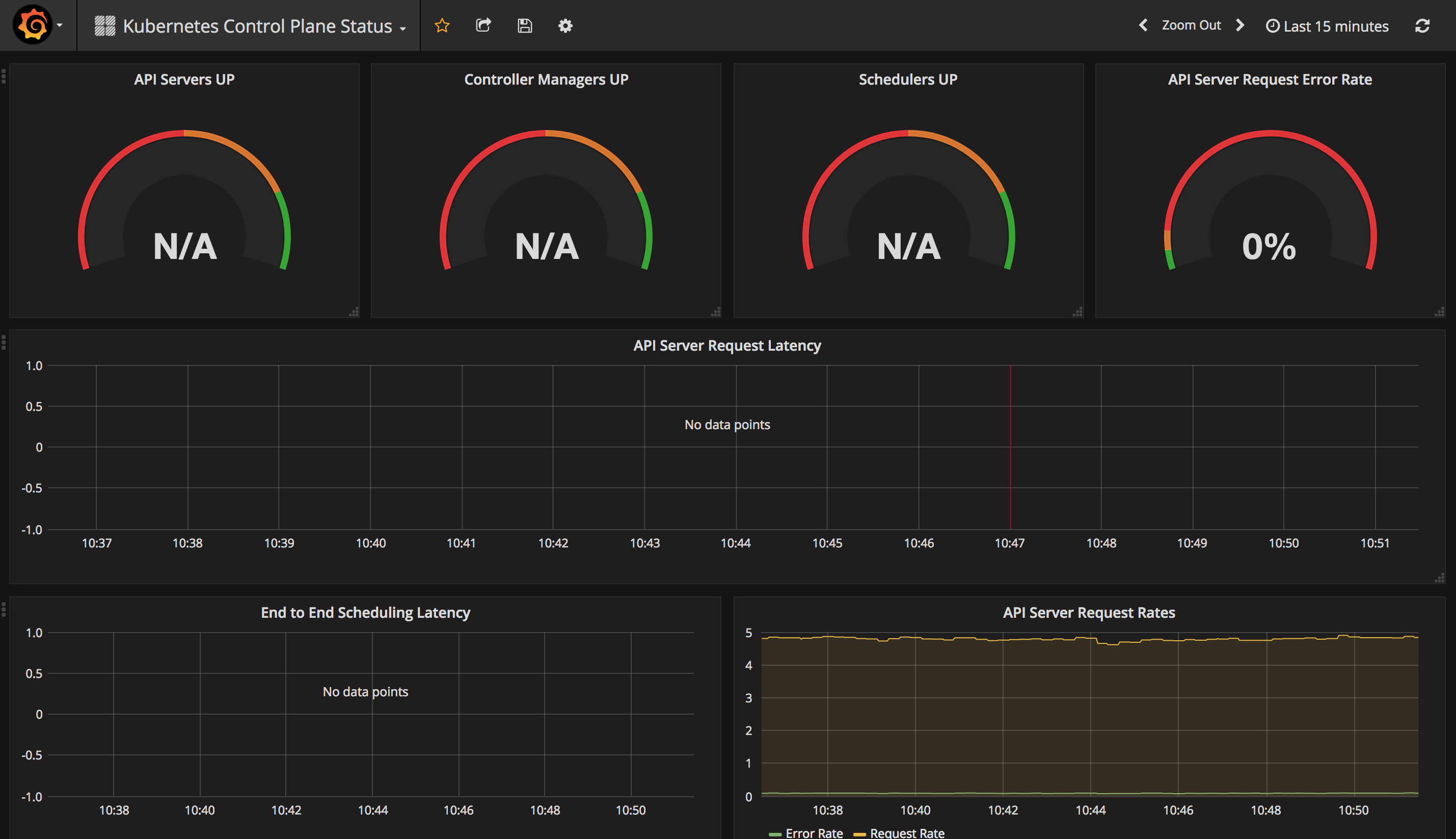
Kubernetes 各个管理组件的状态:
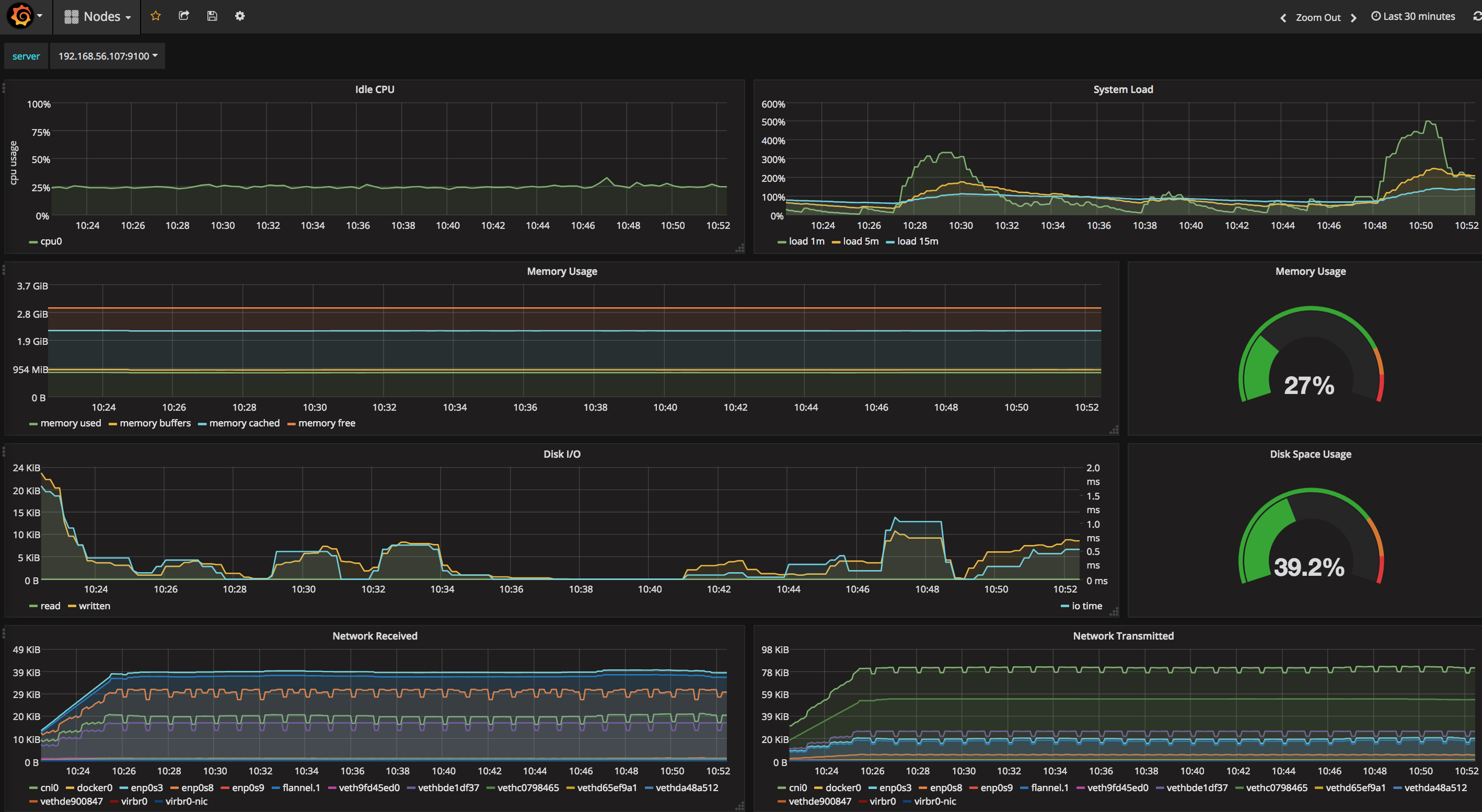
节点的资源使用情况:
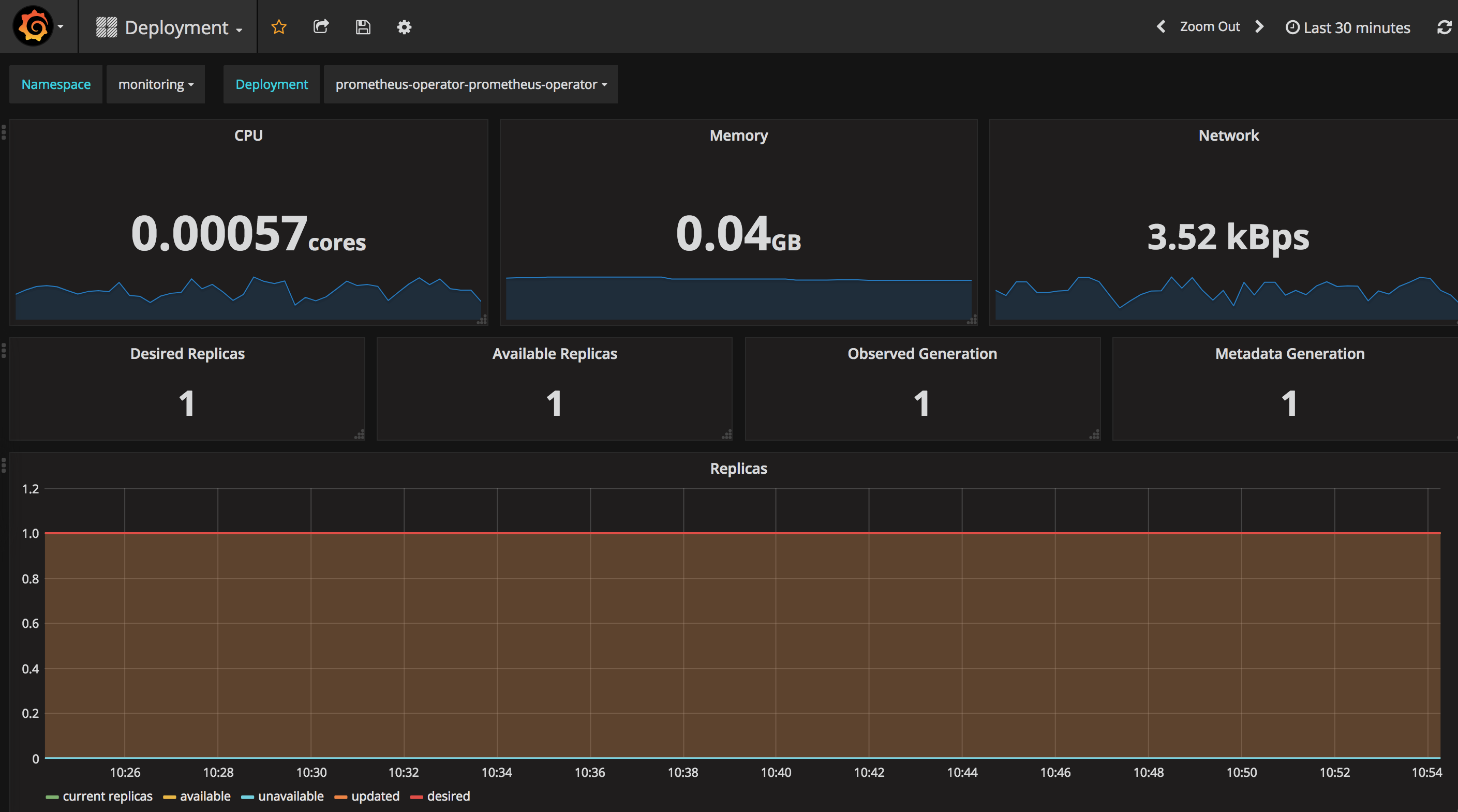
Deployment 的运行状态:
Pod 的运行状态:
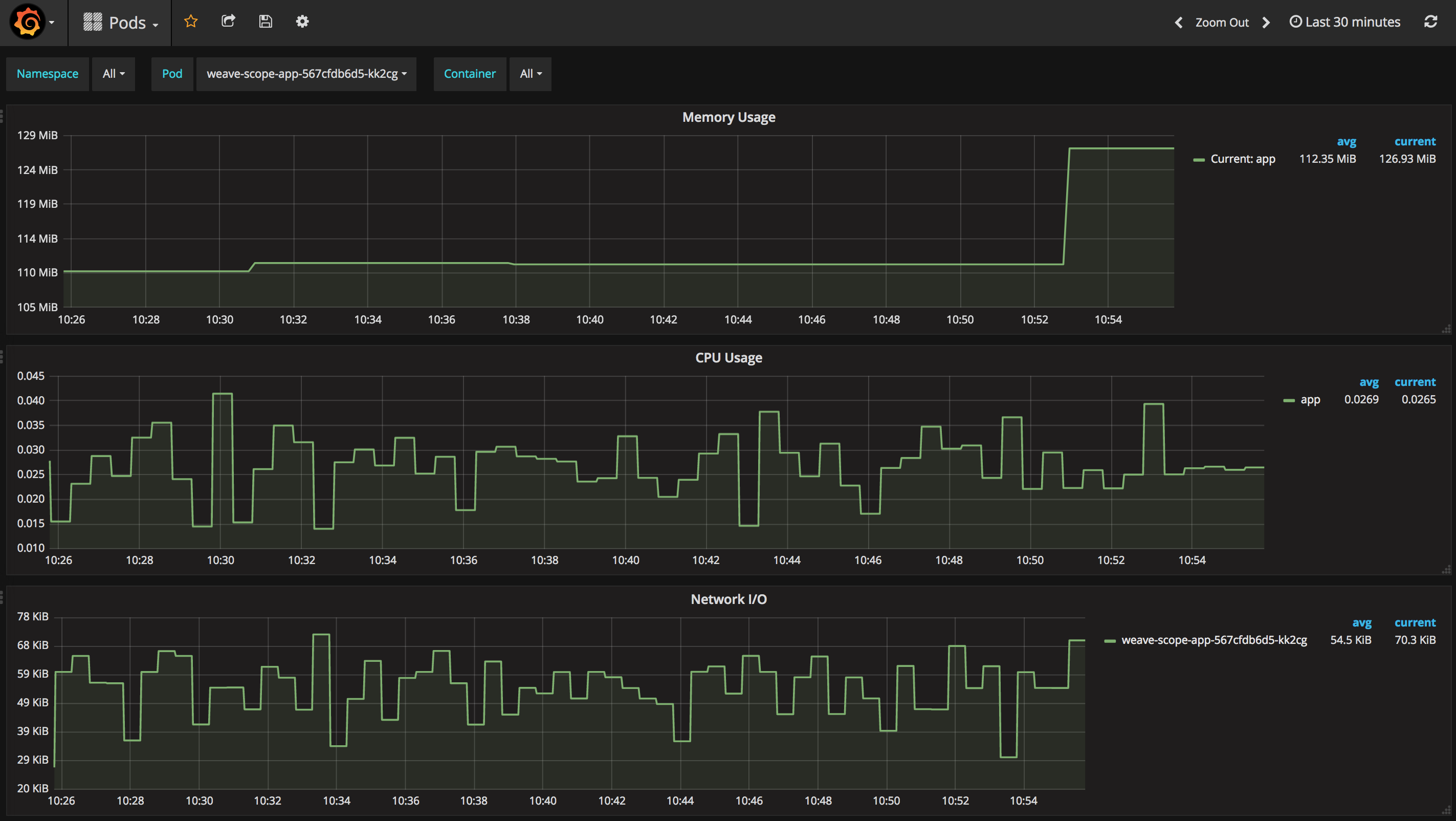
这些 Dashboard 展示了从集群到 Pod 的运行状况,能够帮助用户更好地运维 Kubernetes。而且 Prometheus Operator 迭代非常快,相信会继续开发出更多更好的功能,所以值得我们花些时间学习和实践。
通过上面这些内容相信对 Prometheus Operator 有了些感性的认识,下一节我们将讨论 Prometheus Operator 的架构。
书籍:
1.《每天5分钟玩转Kubernetes》
2.《每天5分钟玩转Docker容器技术》
3.《每天5分钟玩转OpenStack》
