全部博文(51)
分类: 虚拟化
2018-10-08 14:41:56
一致性算法是用来解决一致性问题的,那么什么是一致性问题呢? 在分布式系统中,一致性问题(consensus problem)是指对于一组服务器,给定一组操作,我们需要一个协议使得最后它们的结果达成一致. 更详细的解释就是,当其中某个服务器收到客户端的一组指令时,它必须与其它服务器交流以保证所有的服务器都是以同样的顺序收到同样的指令,这样的话所有的服务器会产生一致的结果,看起来就像是一台机器一样.
实际生产中一致性算法需要具备以下属性:
我们可以说一个分布式系统可靠性达到99.99...%,但不能说它达到了100%, 为什么? 就是因为一致性问题是无法彻底解决的. 以下四个分布式系统中的问题都与一致性问题有关:
我介绍了教科书上的一些选举算法, 它们也是属于一致性算法,即最后所有服务器所认为的leader都是一致的. 现在实际应用中主流的一致性算法有两个Paxos 和 Raft. Zookeeper 就是选用的Paxos, 而etcd使用的Raft. 作为一名Go爱好者,我先来讲一下Raft吧.
Raft是因为Paxos太难懂太难以实现而提出的,目的是在可靠性不输于Paxos的情况下,尽可能的简单易懂. 但是Raft的论文 In Search of an Understandable Consensus Algorithm还是有18页,我要比它更简单易懂.
Raft把一致性问题分解成为三个小问题:
每个Server有三个状态: leader, follower, candidate
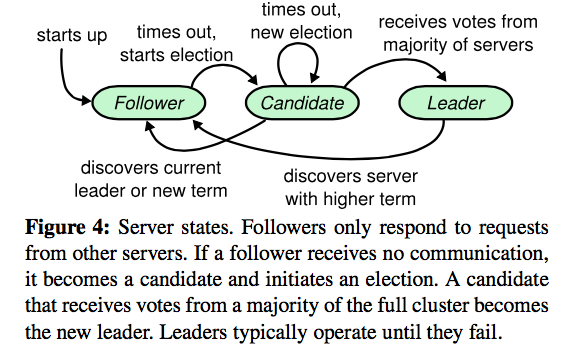
Raft把时间分为terms. 每一个term开始时都进行一次选举. 每一个term里最多有一个leader, 或者没有leader.
算法需要两种RPC, RequestVote RPC:由candidates在选举过程中发起,当另外一个server收到这个RPC之后, 只有当对方term和log都至少和自己的一样新的时候才会投赞成票,收到多数赞成票的candidate会当选leader.

AppendEntries RPC 由leader发起用来分发日志, 强迫follwer的log和自己一致.

如果一个follower在election timeout的时间里没有收到leader的信息,就进入新的term,转成candidate,给自己投票,发起选举 RequestVote RPC. 这个状态持续到发生下面三个中的任意事件:
为什么会有3这个情况呢,就是当如果大家同时发起选举,都投给自己,那就没有Server能够得到多数选票了,这个时候就要进入下一个term,再选一次. 为了避免这个情况持续发生,每个Server的election time被随机的设成不同的值,所以先timeout的就可以先发起下一次选举.
选好leader之后就可以分发log啦.
每一个log都有一个log index 和 term number. 当大多数的follower都复制好这个log时,就说这个log是committed,可以执行了. Leader 记住已经commit的最大log index, 用它来分发下一个 AppendEntries RPC. 这个和TCP里段的编号的作用是一样的.
当一个leader重新选出来时,它的log和follower的log可能不一致,那么它会强制所有的follower都和自己的log一致.首先leader要找到和follower之间的最大的编号一致的log,然后覆盖掉那之后的log.
但是到目前为止仍然不能保证安全性.比如说, 当leader在commit log时, 某follower掉线了,然后这个follower后来被选为leader,它会覆盖掉现在follwer那些已经committed log, 由于这些log是已经执行过的,所以结果不同的机器就执行不同的指令. 在选举过程中,再加多一个限制就可以防止这种情况发生, 即:
Leader completeness property:
对于任意一个term, leader都要包含所以在之前term里committed的logs.
这样就是完整的Raft算法了.
注:图片都来自Paper In Search of an Understandable Consensus Algorithm
